

编码与开发
开发者能用上的操作和概念大杂烩

操作
备忘录
启动博客预览:
bundle exec jekyll servevscode 中 ctrl + shift + p,Python: select interpreter 即可导入虚拟环境
vscode 中 alt + shift + 鼠标拖动可以创建多个光标同时编辑,也可以 ctrl + 上下键创建多个光标
tensorboard 命令
1
tensorboard --logdir=my_log_path --port=6007
pip freeze可以将环境下的包以 requirements.txt 的格式导出,使用pip install -r requirements.txt即可得到一个一样的环境np_array 的图片是 HWC(height,width,channel),用 shape 属性可以查看;cv.imread 得到的是 ndarray。numpy 相对于 list 的好处是数据类型固定,内存单元连续,所以速度更快。tensor 是数学上定义的张量,torch 和 tensorflow 重载了这个概念, ndarray 是程序中的概念。
服务器上同时存在 gcc/g++-11 和 gcc/g++-12,也同时存在多版本的 CUDA,改 bashrc 或者临时 export 环境变量切换。
使用 ctrl + shift + v 进行粘贴时出现
[[200~~,是因为终端仿真器误解了剪贴板中的内容,或复制的内容中含有非标准字符,仿真器将其解释为了控制序列。更新 windows 系统环境变量之后要重启才能生效
代码快捷键失效多半是快捷键冲突了
开了大写锁定之后标点也会变成英文的半角
fn+\键切换背光设置
在装配体中新建零件,保存到外部文件,单独打开零件,利用装配体中的参考画完之后,单独打开外部零件断开外部参考(断开之前显示——➡️,断开之后显示—x),然后删除相关的草图约束,参考平面可能也需要重新选一个平行的。
sw 草图平面解耦分开,一个草图只画一个功能,哪怕他们在同一个面,设计的时候 准备多套硬件模块以交叉验证这样方便后期调整,草图的依赖关系和层次要符合逻辑,不能想怎么画怎么画
替换 keil 安装目录下的 global.prop 文件可以美化界面
带参数的宏:使用
do{...}while(0)构造后的宏定义不会受到大括号、分号等的影响,总是会按你期望的方式调用运行。CLion 远程开发 CUDA 程序,在 CMakeLists 添加
1 2
set(CMAKE_CUDA_ARCHITECTURES 89) set(CMAKE_CUDA_COMPILER /usr/local/cuda-11.8/bin/nvcc)
GLM 矩阵默认采用列主序(column-major)存储,但这与矩阵的索引方式(
[行][列])并不冲突。存储主序和索引方式并不矛盾、前者是内存存储方式,后者是逻辑访问方式。在矩阵存储主序上,glm 列主序、CUDA 列主序、C++行主序。matlab 切片操作
V(:, 1:k),选取所有行,选取第 1 列到第 k 列os.system 函数可以将字符串转化成命令在服务器上运行;其原理是每一条 system1 函数执行时,其会创建一个子进程在系统上执行命令行,子进程的执行结果无法影响主进程。
@property是 Python 的一个 装饰器(decorator),用于将一个方法“伪装成”属性来使用。这样你就可以像访问属性一样使用一个函数的返回值,而不用加()。ctrl+space 唤起 powertoys 快速启动、win+space 切换键盘输入法、alt+space 唤起 utools 快速启动、win+alt+space 唤起 powertools 命令面板
有线连接的以太网,每次重启要重新登陆校园网。
PowerToys 快捷键
查找鼠标:慢击左 ctrl 两次
裁剪窗口视图并置顶:alt+t
高级粘贴(可粘贴为特定语言代码格式):alt+v
命令面板(类似于 utools):win+alt+space
快速启动(类似于 utools):ctrl+space
屏幕标尺:ctrl+shift+win+m
文本提取器:alt+e
屏幕缩放:alt+1
屏幕白板:alt+2
窗口置顶:alt+q
窗口布局:ctrl+win+/编辑布局,拖动窗口并按 shift 分配窗口位置
编辑或启动工作区:ctrl+shift+/
重音字母:按住字母+space
正则表达式
常用命令
linux bash
1
2
3
4
5
6
source ~/.bashrc # 刷新环境变量
lsb_release -a # 查看系统版本
uname -m # 查看系统架构
cp source_file destination_file # 在当前目录下复制文件
cp source_file /path/to/destination/ # 复制文件到另一个目录
cp -r source_directory /path/to/destination/ # 复制文件夹
anaconda
1
2
3
4
5
conda create -n my_env_name python=3.10
conda activate my_env_name
conda deactivate
conda env list
conda install -c anaconda pkg_name
ROS2
1
2
3
4
5
6
7
8
9
10
11
12
13
ros2 run package_name node_name # 运行节点
ros2 node list # 查看所有节点
ros2 node info node_name # 查看节点详细信息
ros2 topic list # 查看所有话题
ros2 topic echo topic_name # 打印话题消息
ros2 topic pub --rate freq topic_name msg_type msg # 以指定频率向指定话题发布消息
ros2 service call service_name # 调用服务
ros2 action send_goal action_name # 发送动作目标
ros2 bag record topic_name # 录制话题数据
ros2 bag play databag_name # 播放录制的数据
Linux 命令
命令格式
Unix/Linux 命令的基本格式为 command [options] [arguments]
- 命令名称
command:这是执行的指令,例如ls、cp、mv等 - 选项或参数
[options]:这些是用来修改命令行为的标志,通常以短选项(单个破折号和一个字母,例如l)或长选项(两个破折号和一个单词,例如-all)的形式出现;短选项一般可以组合使用 - 操作对象
[arguments]:这是命令要操作的文件、目录或其他对象
这个格式其实是文档编写和命令行工具帮助文档中的一种常见约定:
- command:表示命令名称,必选项,执行的命令。
- [options]:可选项,表示命令的选项参数。
-
:必选项,表示命令的操作对象或参数。 - [argument]:可选项,表示可选的操作对象或参数。
{choice1 choice2 choice3}:必选项,表示在给定选项中选择一个。 - -long-option:表示长选项,通常用于详细说明命令的功能。
- option: 表示短选项,通常是长选项的首字母或缩写。
- …:表示可以重复的参数或选项,表示多个相同类型的参数。
通配符
Linux 命令行支持一系列的通配符,常见的通配符如下
星号(*):匹配零个或多个字符。例如
*.txt会匹配所有以.txt结尾的文件。问号(?):匹配任意单个字符。例如
?.txt会匹配所有单个字符后跟.txt的文件,如a.txt,但不会匹配ab.txt。- 方括号([ ]):
- 匹配方括号中的任意单个字符。例如,
file[1-3].txt会匹配file1.txt、file2.txt和file3.txt。 - 可以包含字符范围,如
[a-z]匹配任意小写字母,[0-9]匹配任意数字。 - 通过使用
!或^在方括号内部的第一个位置,可以表示不匹配这个集合中的字符。例如,file[!0-9].txt匹配不含数字开头的文件名后跟.txt。
- 匹配方括号中的任意单个字符。例如,
- 花括号({ }):
- 匹配花括号内的字符串中的任意一项。例如,
file{1,2,3}.txt会匹配file1.txt、file2.txt和file3.txt。 - 也可以用来创建序列,如
{a..z}或{1..10}。
- 匹配花括号内的字符串中的任意一项。例如,
- 反斜线(\\):用于转义特殊字符,使之成为字面量。例如,
\\?[]需要在命令行中用\\来转义,如\\*表示字面量星号而不是通配符。
复杂命令
grep:grep(Global Regular Expression Print)是用于搜索文件中匹配给定模式的行的工具,支持正则表达式,允许复杂的搜索模式,功能强大。基本用法是grep 'pattern' filename在文件中搜索匹配pattern的行,并将其打印出来。例如,grep -i 'error' logfile.txt会搜索logfile.txt中所有包含“error”(不区分大小写)的行。- 常用选项:
i:忽略大小写。v:反向匹配,即显示不匹配的行。c:统计匹配行的数量。n:显示匹配行的行号。r:递归地搜索目录中的所有文件。
- 常用选项:
wc:(Word Count)用于计算文本的行数、词数或字节数。基本用法是wc [options] [file]。例如,wc -l filename.txt将输出filename.txt中的行数。- 常用选项:
l:仅计算行数。w:仅计算词数。m:仅计算字数。c:仅计算字节数。
- 常用选项:
管道符
|:用于将一个命令的输出作为另一个命令的输入,这使得用户可以将多个简单的命令链接起来,执行复杂的任务。管道符的基本语法为:command1 | command2,command1的输出会直接传递给command2作为输入。使用技巧
组合多个命令:可以使用管道符将多个命令串联起来,比如你可以使用
grep来过滤ls的输出,然后用sort来排序结果。ls -l | grep ".txt" | sort高级过滤:利用
grep命令进行正则表达式匹配,筛选出符合特定模式的行。dmesg | grep -i error文本处理:利用
awk和sed这样的文本处理工具,可以对数据进行更复杂的处理。例如,提取文本中的特定列并排序。cat data.txt | awk '{print $2}' | sort | uniq使用
tee命令同时输出到文件和屏幕:tee是三通管道,tee命令读取标准输入,将内容写入文件,并同时输出到标准输出。ls -l | tee output.txt | grep "config"
软链接与硬链接
软连接又称符号链接,是一种类似于快捷方式的文件,指向另一个文件或目录的路径,可以跨文件系统和分区。硬链接则是直接将一个文件的多个路径关联到同一个文件的实际数据上。硬链接与原文件共享相同的 inode(存储在硬盘上的物理数据块),因此它们实际上是同一个文件的多个入口,只能在同一个文件系统和分区内创建,不能跨文件系统。创建软链接的命令是 ln -s,创建硬链接的命令是 ln,下面的命令会创建名为 python 的链接,指向 python3。
1
2
ln -s /usr/bin/python3 /usr/bin/python # 软连接
ln /usr/bin/python3 /usr/bin/python # 硬链接
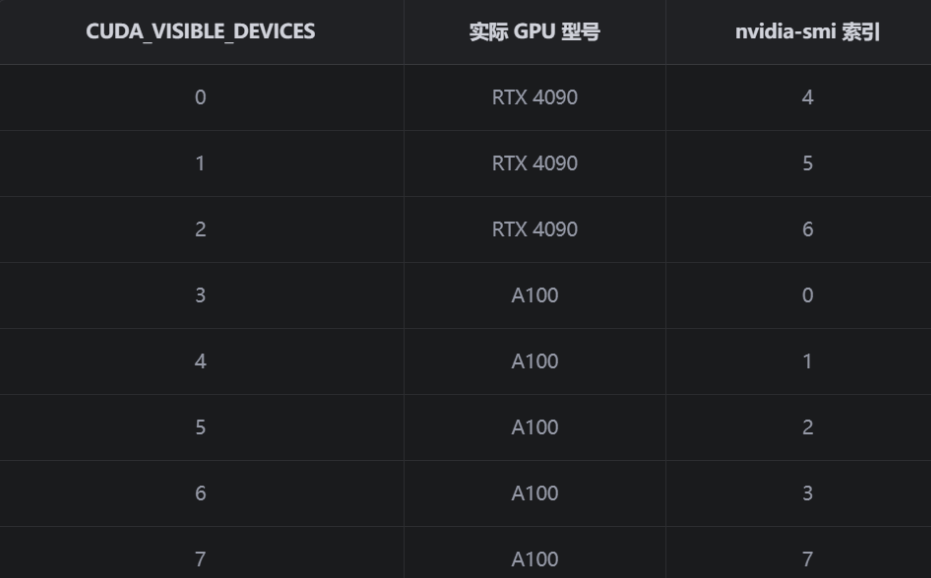
GPU 设备选择
nvidia-smi 的输出是按照物理 GPU 的序号排列的绝对编号,而代码中设置的序号均为 CUDA_VISIBLE_DEVICES 这个逻辑序号。CUDA_VISIBLE_DEVICES 是一个环境变量,用于设置让程序只看到某些卡。比如,export CUDA_VISIBLE_DEVICES=7,6 可以让当前 shell 会话只看到 nvidia-smi 中索引为 7 和 6 的卡,并分别映射为程序内部的 cuda:0 和 cuda:1。
.to()将模型或数据移动到目标设备上,如.to("cuda:1"),.to("cuda")默认为 cuda: 0tensor.cuda()将模型或数据移动到目标设备,默认为 cuda: 0;可以显示指定 GPU 序号,.cuda(1)表示移动到 cuda: 1 上。torch.device("cuda")默认为 cuda: 0,也可以显式指定设备序号device="cuda"默认 cuda: 0,也可以显式指定设备序号
pytorch 创建张量如果不指定设备,默认在 cpu 上,建议创建时指定设备,而不用创建之后再用 to 方法移动。torch.cuda.set_device 可以设置默认使用的 cuda 设备,推荐在程序入口处调用一次,方便后续可以直接写.cuda( )、.to( )等,不用显式指定参数。
torch/extension.h 中提供了将 torch 数据转化到 cuda 中并保证内存连续的工具函数(将 torch_tensor 的内存重新解释为 cuda 指针)。PyTorch 自定义 CUDA 扩展不能跨设备使用, 像 diff-gaussian-rasterization 这样的自定义 CUDA 模块,只会在它被首次调用的设备(一般是 cuda:0)上初始化,如果在其它设备上传数据给这个自定义 CUDA 模块,就会导致跨设备非法访问(PyTorch 本身不允许跨 device 调用自定义 C++ CUDA 内核)。
GNU 版本选择
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
which cc # 查看当前系统中cc命令的路径及相关信息, which命令用于查找并显示给定命令的绝对路径
/usr/bin/cc
ls -l /usr/bin/cc # 查看/usr/bin/cc文件的详细信息
lrwxrwxrwx 1 root root 20 10月 1 2024 /usr/bin/cc -> /etc/alternatives/cc
ls -l /usr/bin/gcc # 查看/usr/bin/gcc文件的详细信息
lrwxrwxrwx 1 root root 6 8月 5 2021 /usr/bin/gcc -> gcc-11
ls -l /etc/alternatives/cc # /etc/alternatives/存储了可替代程序的符号链接, cc是指向实际编译器gcc的符号链接
lrwxrwxrwx 1 root root 12 10月 1 2024 /etc/alternatives/cc -> /usr/bin/gcc
update-alternatives --display gcc # 查看linux下gcc命令的多版本管理情况,输出类似下面这样
gcc - auto mode # gcc-12 的优先级是100,gcc-11 优先级是10,优先级高的被自动选中
link best version is /usr/bin/gcc-12
link currently points to /usr/bin/gcc-12
link gcc is /usr/bin/gcc
/usr/bin/gcc-11 - priority 10
/usr/bin/gcc-12 - priority 100
# 在bashrc中设置环境变量来切换使用的gcc版本
export PATH=~/my_gcc_version/bin:$PATH
# 验证
which gcc
gcc --version
/usr/bin/gcc 命令是一个软链接,由 update-alternatives 管理,自动指向优先级最高的版本。有 sudo 权限时可以更改 priority 来改变默认使用的 gcc 版本。没有 sudo 权限时,可以在 bashrc 中 export 环境变量来指定要使用的 gcc 版本。
CLion 远程开发设置 CMake
执行以下步骤来指定 CMake 指定的版本
- 设置环境变量 C =/usr/bin/gcc-11; CXX =/usr/bin/g++-11
- 设置工具链:C 编译器和 C++编译器分别指定为/usr/bin/gcc-11、/usr/bin/g++-11
- CMake 中的 CMake 选项填写-DCMAKE_C_COMPILER =/usr/bin/gcc-11 -DCMAKE_CXX_COMPILER =/usr/bin/g++-11
注:理论上这样设置就可以了,但目前尚不清楚是由于什么原因,导致设置之后并不能稳定成功。(当时 CLion 的远程开发功能尚在 beta 阶段,不知道是不是软件本身的 bug,没有进一步死磕,暂时就记录到这里)
捣鼓这个的起因是 A100 的 gcc 默认为 gcc-12,但是 cuda-11.8 不支持 gcc-11 之后的 GNU 编译链;正常来说,如果 gcc 版本兼容,CLion 不需要进行任何设置。
几种 pip 安装
python setup.py install 是最传统的安装方式,直接调用包内的 setup.py 脚本,通过 setuptools 或 distutils 库执行安装逻辑,会将包文件复制到 Python 环境的 site-packages 目录,卸载需要需手动删除文件
pip install <包名> 是现代 Python 推荐的安装方式,通过 pip 工具从 PyPI 仓库 下载并安装公开的第三方包,自动处理依赖关系
pip install . 是安装 本地包 的方式(. 表示当前目录),本质是用 pip 处理当前目录下的 setup.py 或 pyproject.toml,用 pip 的逻辑处理本地包,依赖处理更可靠
GitHub 无法拉取代码
表现为 GitHub 长期处于半墙状态,挂梯子才能流畅访问,即使开启梯子,clone 仍速度慢/失败。这是因为 git 默认情况下不使用系统代理。
系统代理: 系统代理是通过设置网络协议中的代理服务器,使网络请求(如 HTTP、HTTPS、SOCKS 协议)先通过代理服务器再转发到目标服务器。用户设备上的应用程序会根据系统代理设置(有些应用会选择不转发,即系统代理是非强制的),将流量发送到指定的代理服务器进行处理。系统代理通常只处理特定类型的网络流量,如 HTTP 或 HTTPS 流量。
TUN 模式: TUN 模式则是在操作系统中创建一个虚拟的网络接口,该接口能够接收和发送 IP 数据包。通过 TUN 模式,所有的网络流量(不仅限于某种协议,而是所有 IP 层的流量)都可以被转发到虚拟网络接口,并通过一个隧道(通常是加密的 VPN 隧道)传输到远程服务器。这使得 TUN 模式可以捕获和转发任何网络协议的流量,包括 TCP、UDP、ICMP 等。
如果使用 clash、v2ray 等工具配置,可以开启 TUN 模式,简单快捷,一劳永逸(wsl 和 VSCode 等软件默认都不会使用系统代理)。
如果梯子被封装为程序,一般通过系统代理实现。此时需要修改 git 配置。此时需要打开梯子,在设置-网络和 Internet-代理-使用代理服务器中查看代理 IP 地址和端口,然后打开 powershell,配置 git
1
2
git config --global http.proxy <http://127.0.0.1:7890> # 换成在设置中看到的IP和端口
git config --global https.proxy <https://127.0.0.1:7890> # 换成在设置中看到的IP和端口
博客搭建
本站基于 Jekyll 主题 Chirpy 进行构建,使用 Github Pages 服务完成部署,前置知识为 HTML + CSS + JS 基础语法、Liquid 模板语法、Jekyll 框架使用。开发环境需要安装 Ruby 和 Jekyll。完成后根据 Chirpy 官方提供的使用说明进行配置,就可以得到一个能用的静态博客站点。
在构建过程中,为了自定义外观并添加一些外围的小功能,对源码稍有改动,记录踩过的坑如下:
最开始使用官方推荐的 chirpy-starter 模板 chirpy-starter。这个仓库将站点的大部分代码隐藏在 gems 包中,通过在 Gemfile 中使用
gem "jekyll-theme-chirpy", "~> 7.2", ">= 7.2.4"来引入,适合于想专注于博客内容而不希望花太多精力来定制外观和功能的情况。(使用命令bundle info --path jekyll-theme-chirpy可以定位本地 gem 包中的对应文件)。如跟本站一样有自定义外观和添加功能的需求,需要使用完整版的仓库 jekyll-theme-chirpy官方的使用说明和 CSDN 那篇文章有一点没有说清楚,在部署阶段选择源为“GitHub Actions”之后,需要到 Actions 选项卡开启 Actions,否则提交修改不会触发部署工作流。
将本地修改推送到远程仓库以触发 Github 的 Actions 时,有一项 commitlint 的工作流,即检查 commit 信息是否符合 type(subject): body 的规范(注意英文冒号后有一个空格)。如果 commit 信息不符合规范,会出现报错,因此要注意 commit 信息格式。
开发过程中由于需要对源码作修改但是最开始又使用了 chirpy-starter 模板,后来索性将完整版的仓库直接拉到本地 chirpy-starter 的目录下进行合并,合并之后貌似将 commitlint 的工作流给覆盖掉了,当时没有打算细究 Actions,所以没有将其恢复回来。
在开发过程中,由于尝试使用 Font Awesome 库之外的图标,需要将 svg 图标转为 font 引入,在这个文件末尾添加了自定义样式,而 Vscode 的 Prettier 插件在执行代码格式化时
将:
1
@use 'main.bundle';
格式化为:
1
@use 'main';
由于 production 两端各多了一个空格,导致 scss 文件编译出了错误的 CSS 文件,本地测试没有问题而推送到远程,页面样式渲染出现问题。这个问题在完整版仓库的 Discussion 中也有提及:
博客中用到了一些 jsdelivr 这个免费 cdn,这个网站被墙的程度要远大于 github,之前用过的梯子有的能访问有的不行,加上我又时不时会切换,所有有一阵子出现了博客图片、图标、目录这些使用了 jsdelivr 的资源加载不出来,原因就是向 jsdelivr 的请求被墙了。
Docker 技术
Docker 是一种比较出名的容器技术,通过操作系统级虚拟化,将应用及其依赖打包成容器,实现 “一次构建,到处运行”;但在实现上不虚拟整个操作系统,只虚拟应用运行所需的库、依赖、配置文件等必要组件,并与宿主机共享操作系统内核,比虚拟机更轻量化。Docker 简单来说就是用容器化技术给应用程序封装独立的运行环境,每个运行环境就是一个容器,运行容器的计算机称为宿主机。镜像是容器的模板。每个 Docker 都运行在独立的虚拟环境中,容器的网络与宿主机是隔离的。
Dockerfile 用来以自动化的方式创建 image 镜像,通过镜像可以创建多个不同的 container 容器。
参考 Docker 安装 完成 Docker 的安装,完成后在终端输入 docker --version 能返回版本号说明安装成功。
下面是使用单个容器的基本操作
编写 Dockerfile 以定制镜像,第一行用 FROM 指定基础镜像。在 DockerHub 上提供了许多高质量的操作系统镜像,还有许多方便某种语言、某种框架开发的镜像。
例如:在一个项目工程下创建 Dockerfile,完成编写后使用 docker build 创建镜像,第一次 build 会比较慢
docker build -t image_name . # -t指定镜像名。.表示在当前目录寻找Dockerfile
完成后使用 docker run 启动容器
docker run -p 80:5000 -d --name docker_name image_name # -p将容器上的5000端口映射到主机上的80端口,这样才能从主机的浏览器访问容器中的web应用。-d是detached mode,表示让容器在后台运行,输出不会直接显示在控制台。--name指定容器名字。最后指定容器使用的镜像名
其它常用命令
docker ps -a # 列举所有的容器
docker ps # 列举正在运行中的容器
docker stop <container_ID> # 停止容器
docker rm -f -v <container_ID> # 强制删除运行中的容器,并同时删除volumn
docker images # 列举所有的镜像
docker rmi -f image_name # 强制删除被使用中的镜像
docker exec -it <container_ID> /bin/bash # 启动一个远程shell,用终端 方式访问正在运行的容器
删除容器时会删除其中的所有数据,如果希望保留,可以使用 volumn,这是一个在本地和不同容器中共享的文件夹。本地修改可以和容器中保持同步。有时需要声明某些文件夹不能同步,比如不能让本地的 node_modules 目录覆盖容器中的。有时还要让本地变为 readonly,这样容器中新增的文件和文件夹不同步到本地。
docker volumn create volumn_name # 创建数据卷
docker run -p 80:5000 -d -v volumn_name:/my_dir image_name # 启动容器时通过-v参数指定将数据卷挂载到容器的某个路径下
docker push 可以把制作好的镜像推送到 Docker Hub,docker pull 可以把 Hub 中的镜像拉取到本地。
下面是使用多个容器的操作,这需要用到 docker compos 技术。另外,docker compose 用 yaml 管理命令,避免了命令行输入长串命令的麻烦。并且一个 docker compose 还会自动创建一个子网。
创建 docker-compose.yml 文件,通过 services 来定义多个 container。完成编写后,下面是常用命令
docker compose up -d # 运行所有容器,不加--build表示下次会使用之前的缓存
docker compose up -d --build # 运行所有容器,且镜像有修改就会重建
docker compose stop # 停止但不删除容器
docker compose start # 启动暂停的容器
docker compose down # 停止并删除所有容器,新创建的数据卷需要手动删除
docker compose down -v # 停止并删除所有容器,并同时删除数据卷
服务器上运行 web 应用
下面先在服务器上运行一个最简单的 flask 的 web 应用,新建 app.py,内容如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "Hello, Web App! 部署成功 🎉"
@app.route("/health")
def health():
return {"status": "ok"}
if __name__ == "__main__":
# 0.0.0.0 表示允许外部访问
app.run(host="0.0.0.0", port=5000)
在服务器中新建 python 虚拟环境、启动虚拟环境、安装 flask 依赖、运行 web 应用
sudo apt update
sudo apt install python3-venv python3-pip
python3 -m venv ~/test_flask
source ~/test_flask/bin/activate
pip install flask -i https://pypi.tuna.tsinghua.edu.cn/simple
python app.py
然后在云服务器的防火墙配置中添加一条规则,协议:TCP 端口:5000 授权对象:0.0.0.0/0(允许公网访问)。然后用本地浏览器访问 http://<服务器公有IP>: 5000,看到“部署成功”的提示就搞定了。
计算机网络基础
127.0.0.1 是回环地址,又叫 localhost,只指向当前这台机器,数据包不会走网卡,只能在本机访问。0.0.0.0 表示本机所有的 IP 地址。
10.63.15.65 是内网 IP/私有 IP,内网是只在某个内部环境可用,不能在整个互联网直接访问,相当于小区内部的门牌号。内网 IP 不能直接被公网路由,必须经过 NAT/网关才能访问外网。路由器在公网中不会转发这些 IP 地址,而是直接丢弃。
RFC 1918 规定的三个私有 IP 段为 10.0.0.0 – 10.255.255.255(云服务器/大型内网)、172.16.0.0 – 172.31.255.255(公司内网)、192.168.0.0 – 192.168.255.255(家用路由器)。在同一个内网里的两个网络,不经过 NAT/公网,IP 可以直接互通。如果两台设备的 IP 在同一个网段且子网掩码一致,那么它们在同一个内网下。
校园网会分配给我一个内网 IP,校园网本身是一个超大的内网。学校的出口路由器会有一个 NAT+网关。NAT(Network Address Translation,地址翻译器)把「内网 IP: 端口」翻译成「公网 IP: 端口」,内网可以主动访问公网,反之则不行。网关是内网通向外面的出口。电脑配置中有 IP 地址、子网掩码和默认网关。当访问同一个内网时直接发请求,而不在同一个内网则发给网关,由网关决定下一跳往哪儿走。现实中,校园网出口设备由网关+NAT+防火墙组成。
VPC(Virtual Private Cloud)是云上的专属内网。在云厂商处可以自己创建一个完全隔离的内网,自己决定 IP,自己的云服务器在这个内网里,别人的云服务器进不来。
curl 是一个用于发送网络请求的命令行工具。
在校园网的环境下,如果想让某个应用通过公网 IP 也能访问到,一般有内网穿透和云服务器中转两种方式。由于内网下的应用在 NAT 后面,公网用户不能进来主动访问内网,但内网可以出去主动访问公网。这就是内网穿透,让外部访问的请求沿着你主动建立的连接反向进来。frp 是目前最常用的可以自己搭建的内网穿透工具。frp 有一个跑在公网服务器上的 frps,用于接收公网访问;还有一个跑在内网机器上的 frpc,用于主动连出去。云服务器中转有两种情况,一种就是 frp 中转站(最常见),另一种是云服务器自己就是公网入口。
22、80、443、3306、6379 都是知名的网络端口,对应的服务分别为 ssh、http、https、MySQL、Redis。
域名、DNS、子网、反向代理
原理
字面值(Literal)是指在程序代码中直接表示的固定值,无需通过变量来存储就能被计算机识别和使用,是编程中表示常量的一种形式。
挂载
在 Linux 系统里,挂载就是把一个存储设备(硬盘分区、U 盘等)接入到文件系统的某个目录下,这样你才能通过这个目录访问设备里的文件。插上 U 盘只是让系统识别到这个设备(/dev/sdX),但是文件系统还没有连接到你想访问的目录上。挂载就是把它“接到树上”,让你能用文件路径访问它。
1
2
3
4
# 把设备 /dev/sda1(通常是一个磁盘分区)挂载到 ./u120 这个目录下
mkdir u120 && mount /dev/sda1 ./u120
# 显示系统中所有挂载点的磁盘使用情况
df -h
NFS 是网络文件系统,有服务器端和客户端两部分。服务器即提供文件的设备,通常是 PC;通过编辑 /etc/exports 文件决定要共享的目录。客户端即使用这些文件的设备,通常是板子;用 mount 命令,把服务器上的目录挂载到自己设备的某个目录下。
1
2
# /home/hrx/ws是主机上要被共享的路径,192.168.1.123是主机的ip; 通过将主机的这个目录挂载到板子的/mnt目录,就可以在板子上通过访问/mnt目录来访问到主机上的/home/hrx/ws目录
mount -t nfs 192.168.1.123:/home/hrx/petalinux_ws/nfs_ws /mnt
内存模型
内存模型是针对编程语言的概念,描述了编程语言如何抽象和访问内存;存储器硬件只提供线性的地址空间,不同编程语言需要在这个线性空间上建立自己的软件抽象以便于程序员使用。C 抽象为字节序列+指针、Java 抽象为对象+堆、Python 抽象为对象+垃圾回收堆。内存模型的设计初衷是屏蔽硬件差异,保证程序在不同平台之间的可移植性。
C/C++的内存模型如下,在编译生成的 map 文件中可以找到对应的概念。

命令行工具
命令: 即 Linux 程序。一个命令的本质就是一个 Linux 的可执行程序。命令一般没有图形化界面,但是可以在命令行中通过字符化的反馈与我们交互。
命令行:即 Linux 终端(Terminal),是一种命令提示符页面。以纯字符的形式操作系统,可以使用各种字符画命令对系统发出操作指令。终端是人机交互的窗口,是一个图形化或文本界面程序。
命令行工具 CLI:CLI 是 Command-Line Interface 的简称,泛指通过输入命令和计算机交互的模式。
Shell 是一个接收、解释并执行命令的程序。CMD、PowerShell、Bash 都是 Shell 的一种。CMD(命令提示符)是 Windows 的传统命令行程序,运行 .bat 文件、支持基础命令;PowerShell 是更强大的 CLI 工具,支持对象管道、脚本系统,是 CMD 的“升级版”;Bash 是 GNU Shell,Linux/WSL/Mac 默认终端;zsh 是 Z Shell,是 bash 的超集,有高亮、补全等功能。
Git 工作流
git 管理文件有三种状态:已修改,已暂存,已提交
.gitignore 配置不提交的文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
## git工作流
git clone <url> ## 克隆仓库
git checkout -b <branch_name> ## 创建个人分支
## 写代码
git add <filename> ## 文件修改放入暂存区
git commit -m "commit 内容" ## 提交 commit
git push origin <branch_name> ## 个人分支提交到远程仓库
git checkout master ## 切换到主分支
git pull origin master ## 拉取主分支的更新
git checkout <branch_name> ## 切换到个人分支
git rebase master ## 将主分支的更新同步到个人分支 (如果有冲突需要手动解决)
## 创建 pull request
版本号
大多数软件的版本号一般分为三段,形如 A.B.C,其中 A 表示大版本号,当软件整体重写升级或出现不向后兼容的改变时,才会增加 A;B 表示功能更新,出现新功能时增加 B;C 表示小的改动(例如:修复了某个 Bug),只要有修改就增加 C。
虚拟环境
安装的 Python,主要包含了 Lib 库(包含标准库和 site-packages 第三方包存储位置)、Scripts(包含 pip.exe 包管理器)以及 Python.exe 解释器;安装的时候还安装了 Python 启动器(用于管理多个不同版本的 Python)。虚拟环境即将上面的东西复制一份,一般情况下不含标准库,标准库通过符号链接或直接引用系统 Python 安装路径下的标准库;但 anaconda 出于环境隔离的考虑,会将标准库一并复制;以及会将解释器和包管理器统一放在 Scripts 路径下,主要是为了方便添加环境变量。
虚拟环境本质上是对解释器、包管理器的一种隔离式复制;虚拟环境的激活和去激活就是在环境变量 Path 中添加或去除虚拟环境的解释器路径,相当于对安装位置默认的路径进行截胡。在虚拟环境下安装第三方库,就会安装到虚拟环境的路径下了。
base 是 Anaconda 安装后默认创建的虚拟环境,为了让用户开箱即用,默认在终端启动时就激活 base 环境。如果不激活任何虚拟环境,就在操作系统本地的环境(也叫 “系统 Python” 或 “裸机环境”)中,容易造成 依赖污染、库版本冲突、难以迁移项目 Denham 问题,这正是虚拟环境存在的原因。Anaconda Prompt 本质上是一个 CMD 命令行 + 初始化脚本。它启动时根据使用的 shell 调用不同的脚本,然后设置好 PATH 等环境变量,并激活 (base) 环境。
RSS
RSS 是免广告、免切换、摆脱算法推荐的资讯聚合平台。订阅 RSS 后,每当网站发布一篇新文章,就会向 RSS 链接中添加一条新记录。RSS 阅读器的作用是存储用户订阅的 RSS 网址,以固定的频率自动检查更新。
Numpy
numpy 以具有维度的数组来组织数据,最常用的是 Python 语法中的切片操作,如 array [1:: 2, 3] 表示第二行开始到最后一行每隔一行,第四列;另外注意 numpy 的广播机制,很方便但也容易埋坑。shape 方法查看形状,reshape 方法重塑形状,如三维数组(2, 4,3)可以理解为两个四行三列的二维数组叠起来,dtype 属性查看数据类型或定义时设置数据类型;zeros、ones、full、eys、random、randn、radint 方法填入形状参数可以填充数组元素,concatenate 方法可以合并两个数组。
Shebang
在 Unix/Linux 系统中,Shebang(也称为 Hashbang)是一个特殊的符号序列,位于脚本文件的第一行,用于指定执行该脚本的解释器。它的格式为:#!/path/to/interpreter,其中 #! 是 Shebang 符号,后面跟着解释器的绝对路径。Windows 系统不支持 Shebang,而是通过文件扩展名(如 .py)和关联程序来确定解释器。
Pytorch
pytorch 是基于 Python 的开源机器学习框架,机器学习的基本流程包括:数据集准备和加载、网络模型构建、前向传播、计算损失、反向传播、使用优化器进行梯度下降、保存训练模型。pytorch 对其中的每个步骤都提供了丰富的 API,在使用框架构建机器学习系统时,每个步骤主要的关注点如下
- 数据集准备和加载:数据集的组织方式以及提供 img 和 label 的访问接口、使用 transforms 进行预处理(ToTensor、Resize、Normalize、Compose 等)、加载方式(batch_szie、shuffle、num_workers)。另外,pytorch 提供了图像分类、目标检测、语义分割等任务的常见公开数据集可供直接使用。
- 网络模型构建:继承 nn.Module 类并使用 nn 中提供的各种层并配置相应的参数来构建网络,常用的层包括 Conv、MaxPool、LInear、ReLU、Sigmoid、Flatten 等等,可以使用 Sequential 将它们串联起来。另外,pytorch 图像分类、目标检测、语义分割等任务的经典网络模型可供直接使用。
- 前向传播:将输入传入构建的模型并得到预测输出并记录计算图。计算图即用于记录从输入一步步算到输出的过程的数据结构。
- 计算损失:使用 nn.loss 并指定损失函数,计算输出和目标的损失,常见的损失函数包括 L1、MSE、交叉熵等。
- 反向传播:调用 loss 的 backward 方法,通过链式法则计算损失函数对模型参数的梯度。pytorch 中通过 autograd 机制实现反向传播,当参数 tensor 的 requires_grad 属性为 True 时,在调用 backward 方式并传入模型参数时,就会自动追踪并计算梯度。
- 梯度下降:使用 optimizer 并选用优化器算法,根据反向传播计算出的梯度更新模型参数,常见的优化器算法包括 SGD、Adam 等。
- 模型保存:推荐用 save 方法保存模型的 state_dict 只保存模型参数,可以减小模型大小;加载时使用 load_state_dict 即可。
pytorch 默认会对所有 tensor 记录计算图以便反向传播求梯度,但并不是所有操作都需要梯度(全部追踪会浪费内存和计算),只有用于训练模型的前向传播、损失计算、反向传播以及其它需要对模型参数求导的地方需要追踪梯度,其它如模型推理、日志保存、指标计算等都不需要追踪梯度。通过 with torch.no_grad( ): 这个上下文管理器,with 代码块中的语句会临时关闭梯度追踪,可以显著降低显存占用。
pytorch 默认会对梯度进行累加,通常来说需要在每轮执行完 step 的参数更新到下一轮 backward 之间,调用 optimizer 的 zero_grad 方法清除之前的梯度以确保只记录当轮梯度。只有一些特殊情况下(如显存不足需要累积多个小批次的梯度后再更新参数),才会每 N 轮后才清零一次梯度。
del 用于删除变量引用,释放内存引用计数,真正的内存释放由 Python 的垃圾回收器(GC)决定,PyTorch 的 CUDA 后端有缓存机制,释放后的 GPU 显存会被缓存,一般搭配 torch.cuda.empty_cache()清理显存缓存。
Petalinux
为了在 Xilinx 的硬件平台上运行 Linux,需要使用 Petalinux 工具。Petalinux 不是 Linux 内核,而是一套配置开发环境的工具,降低 uboot、内核、根文件系统的配置的工作量,可以从 Vivado 导出的硬件信息自动完成相关软件的配置。Petalinux 本身基于 Yocto Project(嵌入式 linux 定制框架)构建,内置了针对赛灵思硬件的交叉编译工具链(如 arm-xilinx-linux-gnueabi),支持在 x86 主机上编译针对 ARM 架构的 Linux 内核、驱动和应用程序。Petalinux 编译后会生成嵌入式系统的核心镜像,包括 Linux 内核镜像(定制化的 Linux 内核)、设备树 Device Tree Blob(描述硬件拓扑)、根文件系统 rootfs(包含系统库、命令行工具、应用程序等,Python 就在这里面)、启动加载器 bootloader(默认使用针对 Xilinx 硬件优化的 u-boot)
下面简单记录按照 Alinx 厂家的教用 Petalinux 制作板子镜像并固化到 SD 卡的过程,详细步骤见教程。由于 Petalinux 对系统版本和设置有严格要求,这里按照 Alinx 厂家的教程,在 PC 的虚拟机上安装 ubuntu16.04(或者双系统也行)并在 ubuntu 上面安装 Petalinux2017.4。用 Petalinux 定制 Linux 系统涉及 Vivado 工程和 petalinux 工程,在 Vivado 中编译生成 bit 文件,导出硬件信息并得到包含硬件信息的 hdf 文件,Petalinux 根据 hdf 文件配置 uboot ,内核、文件系统等。
1
2
3
4
5
6
7
8
9
10
11
12
# 创建Petalinux工程
petalinux-create --type project --template zynq --name ax_peta
# 基于Vivado导出的hdf文件,由配置界面配置硬件信息
petalinux-config --get-hw-description ../linux_base.sdk
# 由配置界面配置内核
petalinux-config -c kernel
# 由配置界面配置根文件系统
petalinux-config -c rootfs
# 编译
petalinux-build
# 生成BOOT文件
petalinux-package --boot --fsbl ./images/linux/zynq_fsbl.elf --fpga --u-boot --force
在 PC 的 Linux 上用 disk 工具,分区出 FAT 和 EXT,此时可以把文件放入 SD 卡的 EXT 分区中(Windows 系统是不显示 EXT 分区的,Linux 可以,所以放文件要在 PC 端的 Linux 下操作);然后将工程目录 images –> linux 目录中的 BOOT.BIN 和 image.ub 复制到 SD 卡的 FAT 分区即可。如果需要打包成 img 镜像,使用 imageUSB 工具即可。
Petalinux 的版本和 Python 的版本是绑定的,但 Xilinx 的官方文档中并没有给出对应关系,目前已知 Petalinux2023.1 对应 python3.10.6。如果需要改 Python 版本就需要尝试安装不同的 Petalinux 版本并完成整套的 Linux 系统定制,在板子上运行起来编译出的镜像之后,由 python3 –version 才能查到这个 Petalinux 版本对应的 Python 版本是否符合要求。
另外再多说一句图形界面相关的问题(完全可以不用图形界面拥抱命令行,不过已经问过了相关的情况,这里就一起记录下来了),Petalinux 自带桌面系统 matchbox,但这个系统与 ZYNQ 7000 架构的适配有 bug;Alinx 厂家是自己移特制 Linux 内核和经过移植的 Debian 桌面文件系统,理论上应该也可以自己移植 Linux 其它发行版如 ubuntu 的桌面系统,但移植时涉及文件系统,Python 版本和库也要在此时一并作好处理;不过移植 Linux 在没有接触过的情况下工作量太大坑太多,并且图形界面也不是刚需,这里就不配置了。
NSYS 工具
NVIDIA 的 nsys 工具(NVIDIA Nsight Systems),它是一款性能分析器,主要用于分析 CUDA 程序的 GPU 和 CPU 时间占用、API 调用、内存传输等。
1
nsys profile --stats=true ./main
会运行 CUDA 程序 ./main,并对其进行性能分析,最后输出各种统计信息。
可以手动插入 NVTX 埋点标记区域进行时间统计,“未被你 NVTX 标记住的部分”,也会耗时,但不会出现在 nvtxsum 中。nsys 默认是分析 整个进程的生命周期。
CUDA 编程
基本概念
在 GPU 编程中,CPU 称为主机,GPU 称为设备。GPU 上以 kernel(内核)处理指令,处理的指令称为核函数。核函数不是只执行一次,而是被 GPU 上的所有线程“同时”执行一次。这称为 “单程序多数据(SPMD)” 模型:所有线程运行相同的代码(核函数),但处理不同的数据(通过 index 区分)。CUDA runtime 会将 kernel 的任务描述符(即调用核函数时传入的参数)放入 GPU 的指令队列,由全局的调度器将任务分块并分派给不同的流处理器。
GPU 程序的基本范式为:CPU 分配内存、CPU 内存数据拷贝到 GPU 显存、CPU 启动 GPU 内核函数进行并行数据处理、GPU 显存数据拷贝回 CPU 内存。
硬件结构
CUDA 编程是和 Nvidia 显卡的硬件设计绑定的,其设计初衷需要结合硬件架构才能更好地理解。影响 GPU 性能最主要的两大因素,一个是 GPU 的架构和含有的计算核心数,另一个是显存带宽。在硬件一定的情况下,GPU 编程的一大目标,就是利用共享内存等机制,减少 CPU 和 GPU 间的数据传输,使得 GPU 尽可能多地用于计算而非数据搬运。
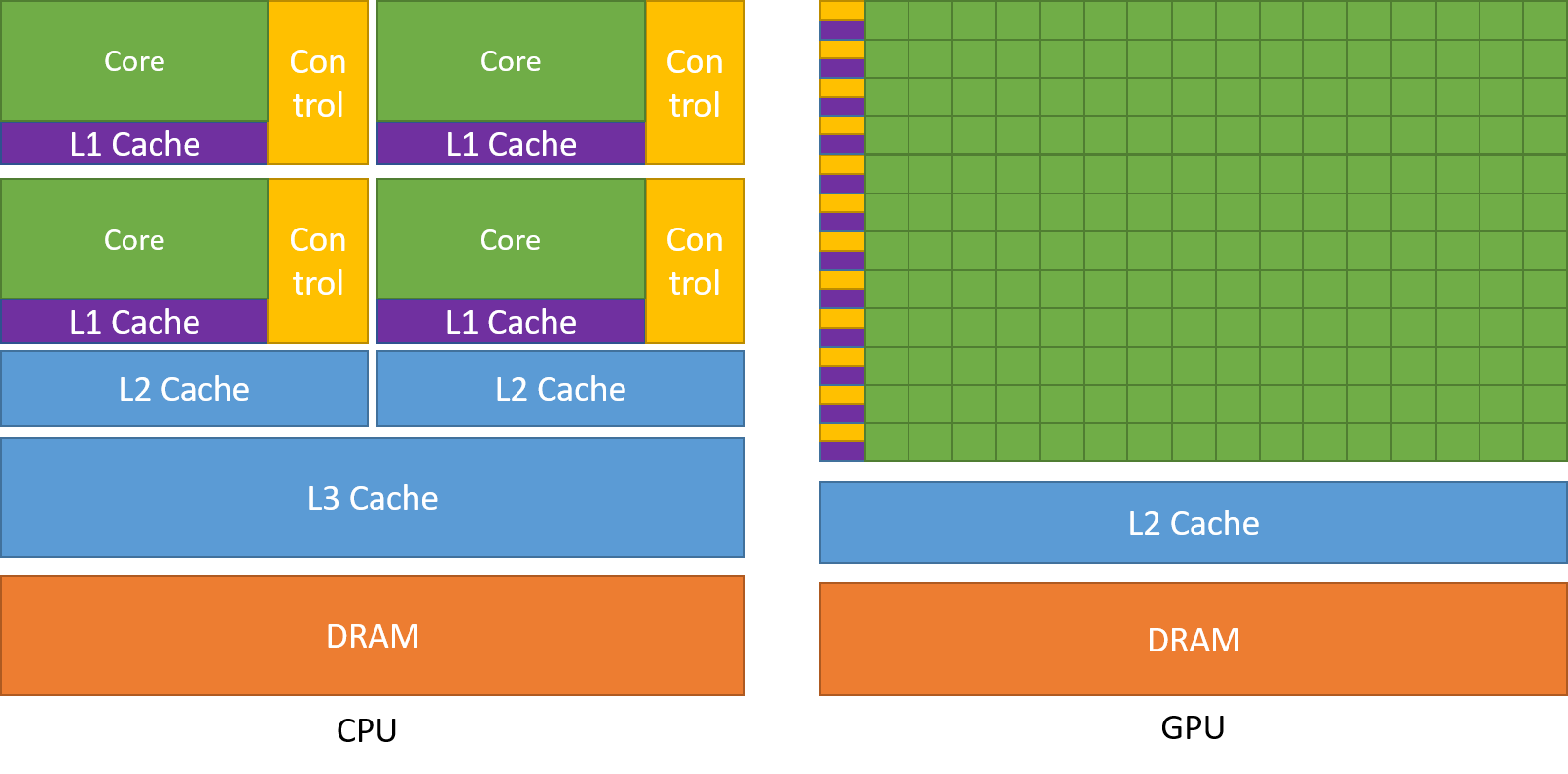
GPU 主要由多组 SM(Stream Multiprocessor,流式多处理器)构成,每组 SM 单元中包含多个流处理器,这些流处理器称为 CUDA 核心。一般来说,一条指令对应一个线程,一个线程对应一个 CUDA 核心。warp 是硬件调度的最小执行单位,由线程束调度器管理,一个流处理器通常配备 4 个线程束调度器。
GPU 的物理架构简化如下图,一个 SM 中包含多个 Warp 和一个 RT Core(Ray Tracing Core,光线追踪核心),一个 Warp 中包含 32 个 CUDA Core 和一个 Tensor Core(专用的张量计算单元)。

早期 GPU 的计算架构是 SIMD(单指令多数据),从 Telsa 架构开始为 SIMT(单指令多线程),区别在于后者支持各个线程以不同的速度执行指令。所谓的 SIMT 是指一个 block 内的线程会以 32 个线程为单位打包为 warp,一个 warp 内的 32 个线程会同步执行同一条指令,但每个线程有独立的寄存器和数据。
语法特性
核函数以线程 thread 为单位、在 grid 范围内执行,线程被分组为线程块 block,线程块 block 又被分组为网格 grid。一个 grid 内可以共同访问全局内存,一个 block 内可以共同访问共享内存,共享内存的访问速度远快于全局内存,但容量相对也是有限的。在内存布局上,CUDA 中将矩阵/张量当成向量处理,用一维索引的方式访问。高维矩阵在内存中按行优先(row-major)方式展开。
核函数声明符 __global__ 用于标记可在 GPU 上并行执行的函数,用于启动大量并行线程,必须返回 void,由 CPU 调用,GPU 执行。返回 void 的原因是,如果像普通函数那样 return 一个大结果,需要把数据从 GPU 内存复制回 CPU 内存,效率很低。而通过传入 C 的地址,GPU 可以直接在 C 的内存位置上写结果,省去了额外的数据复制。设备端 / 主机端函数限定符 __device__(仅 GPU 调用,在 GPU 上执行)、__host__(仅 CPU 调用)用于标识变量和函数。
gridDim 和 blockDim 分别表示网格中线程块的维度和线程块中线程的维度(三维结构,包含 x、y、z 分量,未指定的维度会被自动设置为 1)。blockIdx 和 threadIdx:分别表示线程块在网格中的索引和线程在线程块中的索引(三维结构,包含 x、y、z 分量)。索引是每个线程独有的变量,不同线程的这两个值不同,由硬件自动分配。dim3 是三维向量类型,专门用于指定网格和线程块的维度。<<<...>>> 用于配置网格并启动内核 kernel<<<blocksPerGrid, threadsPerBlock>>>(...)
1
int globalThreadId = blockIdx.x * blockDim.x + threadIdx.x;
cudaMalloc 用于在 GPU 的显存(全局内存)上分配空间,并把该显存的地址写入指针变量。函数签名中已经说明了要传的参数是指向设备内存指针的指针。之所以要用指针的指针,是因为 CUDA Runtime 要修改在 CPU 上定义的指针变量的值,让它指向 GPU 显存。要修改一个指针变量的值,就必须传入指向该指针的指针(即二级指针)。cudaMemcpy 将数据在目标设备之间拷贝,可选择 cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost, cudaMemcpyDeviceToDevice 来指定拷贝的源设备和目标设备。cudaFree 释放设备上的内存。cudaDeviceSynchronize 用于同步 CPU 和 GPU,等待 GPU 完成所有核函数执行。
原语是 CUDA 提供的基础操作函数,通常是高性能的、直接在 GPU 硬件上实现的。cuBLAS 和 cuDNN 是最常用的两个 GPU 加速的 API 库,cuBLAS 聚焦于通用线性代数运算加速,cuDNN 聚焦于深度学习中的特定优化操作。两个库中的 API,按照官网文档的说明调用即可。
CUDA 语法是 C/C++ 的扩展,只能在 .cu 文件中编写,并由 nvcc 编译时分离为宿主代码和设备代码。宿主代码(未被 __global__ 和 __device__ 修饰的函数)经编译生成 CPU 可直接执行的 x86 二进制指令;设备代码(被 __global__ 和 __device__ 修饰的函数)则先被编译为并行线程执行(PTX)中间语言,再在程序运行时通过即时编译(JIT)机制转换为特定 GPU 的原生指令。
程序优化
CUDA device memory 默认不会自动初始化(不像 host memory 的 new 可以初始化为 0),不显示初始化很容易引发非法访问,表现为 OOM 或 kernel 崩溃。
GPU 利用率(Utilization)很低而显存占用很高,说明程序占用了大量显存,但几乎没在真正跑 GPU 计算任务,说明计算瓶颈不在 GPU,而可能在别的地方。比如, 模型或数据加载到了 GPU,但推理/训练计算很少或很慢;数据准备在 CPU 上太慢,GPU 处于等待态;操作本身不需要多少计算,但内存占用大;再比如渲染代码是逐帧处理,没有批量化处理。可以 log 记录每次 render 的时间,确认是不是 CPU 在等。
数据在 cpu 和 gpu 之间的传递会比较耗时,应当尽量避免。内存优化技巧主要有:
- 使用固定内存缓冲区:通过
pin_memory()方法将数据加载到固定缓存(常驻内存)中,可以加速 CPU 到 GPU 的数据传输。 - 重用张量内存:在可能的情况下,重用已分配的张量内存,避免频繁的内存分配和释放。
- 尽量让邻近线程访问邻近内存位置,可提高缓存效率。
ROS2
ROS = 通信机制 + 开发工具+ 应用功能 + 生态系统,目的是设计一套标准的机器人平台和其中的软件,提高机器人软件复用率,不要重复造轮子,高效开发机器人。ROS1 针对的是有工作站级别运算平台、以有线连接为主保证网络连接、成本高昂的实验室机器人。与之相反的需求(在资源有限的嵌入式平台运行、在有干扰的地方保证通信可靠性、做成产品走向市场)便是 ROS1 面临的问题,类似问题的涌现致使 ROS2 诞生。ROS2 面向的需求有:多机器人系统、跨平台、实时性、网络连接安全可靠、产品化、设计开发调试测试部署等全流程的项目管理,整个框架尽量保留了 ROS1 中的概念以便于迁移。

工作空间
ROS 系统中一个典型的工作空间结构如图所示,dev_ws 为工作空间的根目录,其中包含四个子空间
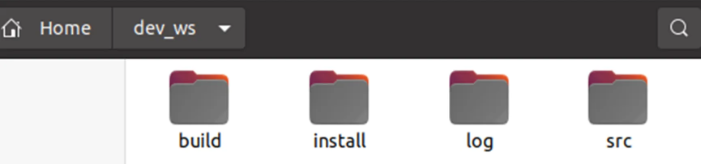
- src:代码空间,未来编写的代码、脚本,都需要人为的放置到这里;
- build:编译空间,保存编译过程中产生的中间文件;
- install:安装空间,放置编译得到的可执行文件和脚本;
- log:日志空间,编译和运行过程中,保存各种警告、错误、信息等日志。
绝大部分操作都是在 src 中进行的,编译成功后,就会执行 install 里边的结果,build 和 log 两个文件夹用的很少。
拉取工作空间后,要进行依赖配置
1
rosdepc install -i --from-path src --rosdistro humble -y
功能包
不同功能的代码划分到不同的功能包中
在 src 目录下创建功能包
1
2
ros2 pkg create --build-type ament_cmake c++_package_name # 创建C++包
ros2 pkg create --build-type ament_python python_package_name # 创建python包
C++功能包中,package.xml 包含功能包的版权描述、依赖声明;CMakeLists.txt 包含编译规则。Python 功能包中,package.xml 包含功能包的版权描述、依赖声明;setup.py 中包含 entry_points 配置的程序入口
节点
节点是机器人的工作细胞,负责执行具体任务,是可独立运行的可执行文件,得到这个可执行文件的编程语言多种多样,ROS2 中一般使用 C++和 Python。节点可以是分布式的,即运行在不同计算机上,每个节点命名唯一。实现一个节点的流程:编程接口初始化、创建节点并初始化、实现节点功能、销毁节点并关闭接口。
通信机制
通信模型有话题、服务、动作三种通信机制
话题:节点不是孤立的,通过话题来联系,话题是节点间传递数据的桥梁。话题的实现使用基于 DDS 的发布/订阅模型。发送数据的对象称之为发布者,接收数据的对象称之为订阅者,每一个话题都需要有一个名字,传输的数据也需要有固定的数据类型。话题使用.msg 文件定义。
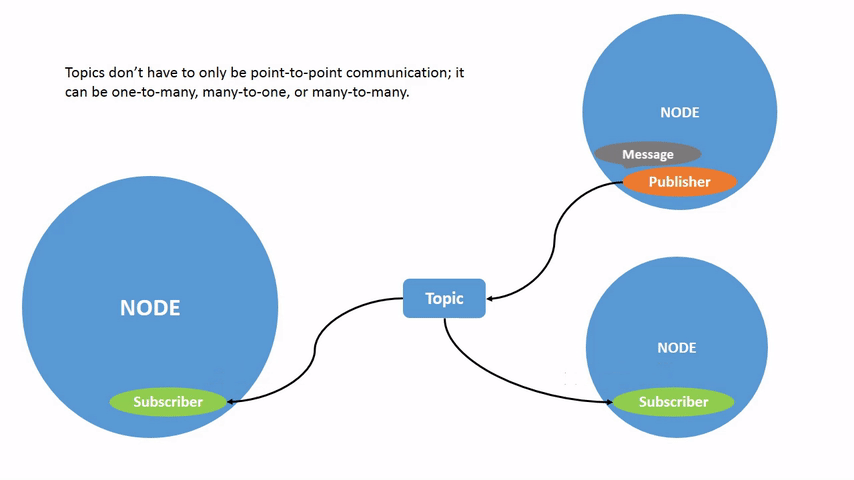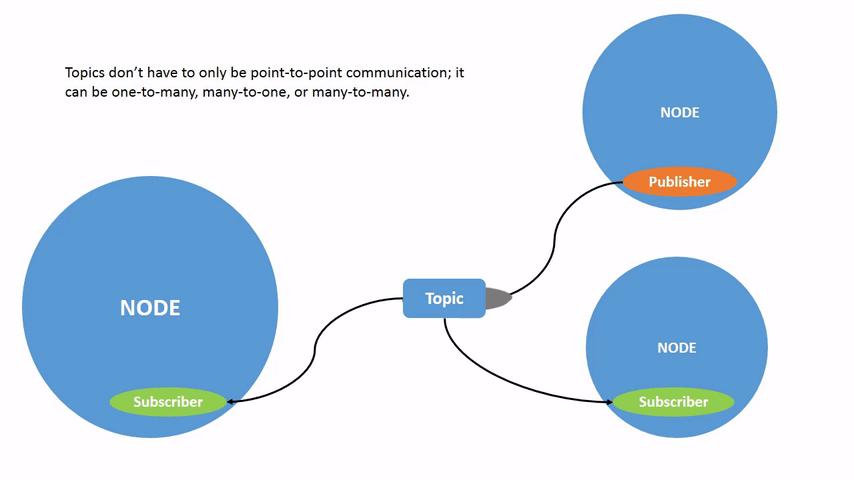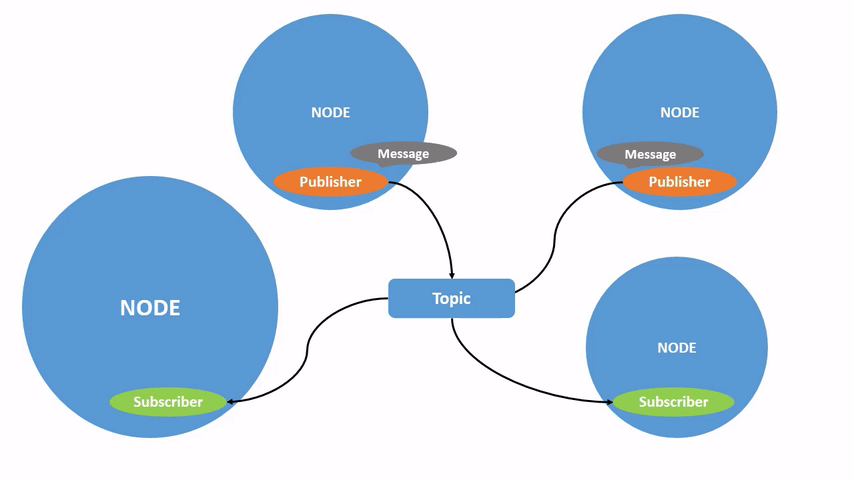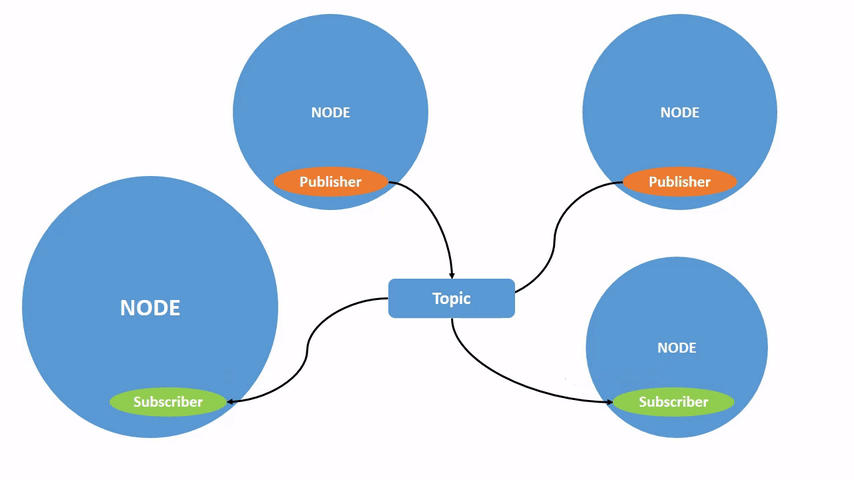
- 发布者和订阅者的数量并不是唯一的,可以称之为是多对多的通信模型。
- 话题通信是异步的,适合用于一些周期发布的数据,比如传感器的数据,运动控制的指令等等
- 话题通信数据的描述格式称之为消息,对应编程语言中数据结构的概念。消息是 ROS 中的一种接口定义方式,与编程语言无关,我们也可以通过.msg 后缀的文件自行定义。
- 话题通信是单向的
- 实现一个发布者的流程:编程接口初始化、创建节点并初始化、创建发布者对象、创建并填充话题消息、发布话题消息、销毁节点并关闭接口
- 实现一个订阅者的流程:编程接口初始化、创建节点并初始化、创建订阅者对象、回调函数处理话题数据、销毁节点并关闭接口。
服务:从服务的实现机制上来看,这种你问我答的形式叫做客户端/服务器模型,简称为 CS 模型,客户端在需要某些数据的时候,针对某个具体的服务,发送请求信息,服务器端收到请求之后,就会进行处理并反馈应答信息。适合一问一答,同步性要求更高的数据。服务使用的是.srv 文件定义。
- 在服务通信中,客户端可以通过接收到的应答信息,判断服务器端的状态,我们也称之为同步通信。
- 服务器端唯一,但客户端可以不唯一。
- 数据分为请求的数据和反馈的数据。
- 实现一个客户端的流程:编程接口初始化、创建节点并初始化、创建客户端对象、创建并发送请求数据、等待服务器端应答数据、销毁节点并关闭接口
动作:动作也使用客户端/服务端模型,用户发送动作目标,服务端执行动作,同时周期反馈执行中的状态。动作是一种应用层的通信机制,基于话题和服务实现。动作的三个通信模块,有两个是服务,一个是话题,当客户端发送运动目标时,使用的是服务的请求调用,服务器端也会反馈一个应答,表示收到命令。动作的反馈过程,其实就是一个话题的周期发布,服务器端是发布者,客户端是订阅者。
- 动作通信可以有多个客户端,只有一个服务端
- 因为反馈,动作机制也是一种同步通信机制
通信接口
接口(Interfaces)给数据定义一个标准的结构,ROS 的接口和编程语言无关,这些定义在编译时会自动对应到具体编程语言中的数据结构

- 话题通信接口的定义使用的是.msg 文件,由于是单向传输,只需要描述传输的每一帧数据是什么就行,比如在这个定义里,会传输两个 32 位的整型数,x、y,我们可以用来传输二维坐标的数值。
- 服务通信接口的定义使用的是.srv 文件,包含请求和应答两部分定义,通过中间的“—”区分,比如加法求和功能,请求数据是两个 64 位整型数 a 和 b,应答是求和的结果 sum。
- 动作是另外一种通信机制,用来描述机器人的一个运动过程,使用.action 文件定义,比如让小海龟转 90 度,一边转一边周期反馈当前的状态,此时接口的定义分成了三个部分,分别是动作的目标,比如是开始运动,运动的结果,最终旋转的 90 度是否完成,还有一个周期反馈,比如每隔 1s 反馈一下当前转到第 10 度、20 度还是 30 度了,让我们知道运动的进度。
自定义通讯接口需要在 CMakeLists.txt(或 setup.py 和 setup.cfg)和 package.xml 中添加对应规则,使用 rosidl(interface definition language),根据自定义接口生成对应的代码
参数
参数是 ROS2 系统中的全局字典,即所有节点可访问的键值对,可编写程序声明、创建、修改参数的值,也可用 yaml 文件配合 dump 命令保存节点中的参数和 load 命令加载参数。
设计模式
设计模式是面向对象系统的代码设计思想,核心思想是提供可复用的解决方案,让代码更易维护、扩展和理解。设计模式独立于具体编程语言,不同编程语言特性差异很大,有的语言本身就是为了贯彻某个设计原则而被开发出来的,有的语言提供了针对某些设计模式的语法糖,同一种设计模式在不同语言中也可能有不同的实现方式。
代码的设计其实自底向上分为三层,最基本的是低耦合高内聚的设计思想,往上是面向对象的设计原则,再往上才是各种设计模式。设计模式依赖接口这个抽象规范,接口是抽象方法的集合,在底层实现接口时,必须按照接口给定的调用方式来实现,而对高层模块则隐藏了类的内部实现。
面向对象的设计原则
面向对象的三大法则是封装继承多态,三者是递进关系。封装就是有意识地把对象的属性和方法分为对内的和对外的;继承是为了提高代码的复用性,子类可以直接复用父类的属性和方法,并可以实现新功能或覆写父类方法的实现;多态指同一操作作用于不同对象时,会产生不同的执行结果。
面向对象的设计原则包括:
- 开放封闭原则:对扩展开放,对修改关闭,即支持加新功能,但最好不要修改已经成型的代码。
- 里氏替换原则:引用父类的对象要能透明地使用其子类的对象,即子类和父类的方法,实现上可以不同,但输入和返回需要一致。
- 依赖倒置原则:高层模块不应该依赖底层模块,两者应该依赖接口这个抽象。抽象不应该依赖细节,细节应该依赖抽象,即要针对接口而不是针对实现编程。
- 接口隔离原则:客户端不应该依赖那些它不需要的接口,因此要使用多个专门的接口而不是单一的总接口。
- 单一职责原则:一个类只负责一项职责,不要存在多个导致类变更的原因。
设计模式分类
设计模式大致分为创建者模式、结构型模式、行为型模式。创建者模式解决如何创建对象的问题;结构型解决对象之间怎么组织的问题;行为型模式解决如何实现方法的问题。
- 创建者模式:简单工厂模式、工厂方法模式、抽象工厂模式、建造者模式、原型模式、单例模式
- 结构性模式:适配器模式、桥接模式、组合模式、装饰模式、外观模式、享元模式、代理模式
- 行为型模式:解释器模式、责任链模式、命令模式、迭代器模式、中介者模式、备忘录模式、观察者模式、状态模式、策略模式、访问者模式、模板方法模式
创建者模式
简单工厂模式:通过工厂类负责创建产品类的实例,隐藏创建对象的实现,但违反了单一职责原则和开闭原则。
工厂方法模式:将工厂分为抽象工厂角色和具体工厂角色,一个工厂角色只负责创建一个产品类的实例。
抽象工厂模式:每一个具体工厂都生产一套产品而不是一个,有利于维护产品之间的约束关系,但难以支持新种类的抽象产品。
建造者模式:用指挥者角色以同样的构建过程创建不同的表示,有利于约束构建顺序。
原型模式:对于需要被复制的类,从内部提供克隆的接口方法,使得在某些属性和方法对外部不可见的情况下,外部也能对类进行复制。
单例模式:保证一个类只有一个实例并提供一个全局的访问点,相当于全局变量的同时防止了命名空间被污染。单例模式分饿汉式和懒汉式,饿汉式即在类加载时进行实例化,懒汉式即在第一次使用时进行实例化。
一般来说,以简单工厂或工厂方法开始,当发现设计需要更大的灵活性时,再向抽象工厂或建造者演化。
结构性模式
适配器模式:使得原本由于接口不兼容而不能一起工作的类可以一起工作,实现方式有多继承(类适配器)和组合(对象适配器)两种,多继承即同时继承多个类,组合即将要适配的类作为适配器的属性,以在适配器中调用需要的属性和方法。
桥接模式:将一个实物的两个维度分离成抽象和实现,将继承关系转换为组合关系,两个维度都可以独立扩展,提高了扩展的灵活性。
组合模式:将对象组合成树形结构,使得用户对单个对象和组合对象的使用具有一致性,角色包括抽象组件、叶子组件、复合组件。
装饰模式:在不改变原有对象结构的前提下,动态地给对象添加额外功能。它通过创建一个包装类(装饰器)来包裹原始对象,允许在调用原始对象方法的前后添加新的行为,同时保持接口的一致性。
外观模式:定义高层接口来统一调用子系统中的功能,使得子系统组合起来的功能更易于使用,实质是多一层封装。
享元模式:通过共享技术减少系统中对象的数量,节省内存空间并提高性能;适用于存在大量相似或相同对象的场景,通过复用已存在的对象来避免重复创建,仅在必要时才创建新对象。
代理模式:为真实对象提供一种代理来以控制这个对象的访问,角色包括抽象实体(作为接口)、实体(真实对象)、代理(和真实对象使用一致的代理对象);常见的应用场景如远程代理、虚代理、保护代理。
行为型模式
解释器模式:一般用于做编译器,解释器是负责解释文法规则的模块,解释器模式是一种语法解释器的开发框架。
责任链模式:使多个对象连成一条链并沿着这条链传递请求,链上的对象都有机会处理请求,避免在客户端处理发送者和接收者之间的耦合关系,一个对象无需知道是其它哪一个对象处理其请求,要求链上的对象有同样的处理接口并存储链的下一级对象。
命令模式:一般用于做桌面程序、命令行工具等,将请求转换为一个包含与请求相关的所有信息的独立对象。将对象的具体实现(行为的实现者)通过接口与业务逻辑(行为的请求者)分离。
迭代器模式:一般用于实现迭代器这种数据结构,将遍历逻辑与聚合对象分离,使得同一聚合对象可以支持多种遍历方式,同时遍历方式的变化不会影响聚合对象本身。
中介者模式:减少对象之间混乱无序的依赖关系,限制对象之间的直接交互,迫使它们通过中介者对象进行合作。
备忘录模式:允许在不暴露对象实现细节的情况下保存和恢复对象之前的状态,用于实现对象的 “快照” 功能和撤销操作。核心结构包括原发器(可以创建备忘录或从备忘录恢复)、备忘录(存储原发器的内部状态,对除了原发器之外的外部隐藏细节)、负责人(管理备忘录的存储和获取,但不直接操作备忘录中的状态)。
观察者模式:又称发布订阅模式,当一个对象的状态改变时,所有依赖它的对象都得到通知并被自动更新,角色包括抽象发布者、具体发布者、抽象观察者、具体观察者。
状态模式:将对象在不同状态下的行为封装到独立的状态类中,使得对象的状态变化时,其行为能自动切换到对应状态的实现,从而避免使用大量的条件判断。内部状态需抽象,行为与状态匹配,不同状态关联不同行为导致不同表现效果。状态模式是状态机思想的一种实现方式。
策略模式:封装一系列可相互替换的算法,算法独立于使用它的客户而变化,即提供相同行为的不同实现,角色包括抽象策略、具体策略和上下文,但客户必须了解不同的策略。
访问者模式:在不修改已有类的前提下,为一组不同类型的对象添加新的操作。它通过将操作逻辑与对象结构分离,使得操作可以独立于对象而变化。定义一个访问者对象,来访问一组不同类型的元素,并对每个元素执行特定操作,而无需在元素类中直接实现这些操作。
模板方法模式:定义一个操作中的算法骨架,而将一些步骤延迟到子类中,可以在不改变算法结构的情况下可重定义操作的某些步骤。角色包括抽象的原子操作/钩子操作(实现模板方法作为算法的骨架)和具体类(实现原子操作)。