3DGS软硬件协同优化工作梳理
论文梳理
3DGS 软硬件协同工作
按照“做的事 + 动机和分析 + 实验设置与效果 + 具体方法”的模板来梳理文章
ISSCC
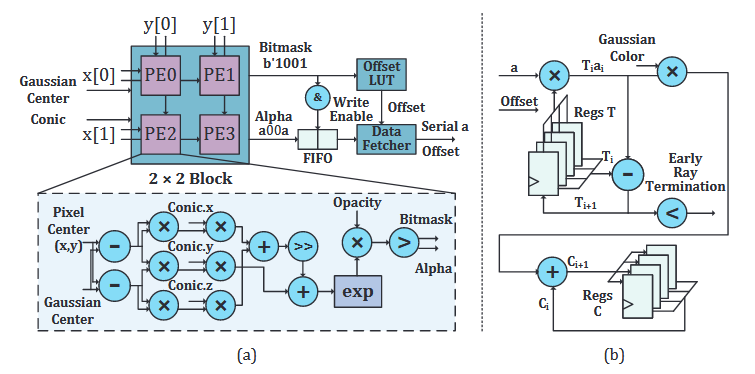
1.78mJ/Frame 373fps 3D GS Processor Based on Shape-Aware Hybrid Architecture Using Earlier Computation Skipping and Gaussian Cache Scheduler(ASIC 流片,3DGS 边缘部署)
动机和分析:高斯在 NX 上只能跑到 6.4FPS。第一,复杂的计算流需要支持多样的运算操作和较大的处理位宽。第二,高斯形状多样导致依赖大量依赖输入的低效计算。第三,球谐系数需要很大的片外存储和频繁的不规则访存。
实验设置与结果:工作频率 150-700MHz,在 NeRF-Synthetic 数据集上。150MHz 下实现 6.65TOPS/W 峰值能效,帧率 80FPS,功耗 46.5mW,每帧能耗 0.58mJ。700MHz 下帧率 373FPS,功耗 664mW。
具体方法:
- 一是对于 alpha 的计算,支持精准计算和插值计算的切换,高斯平滑时使用利用邻近像素结果做插值计算,关于平滑的判定条件文中没有给出公式,应该是看高斯的扩展程度和变化梯度。
- 二是分别判断 tile 四个角的 alpha、高斯中心与 tile 的距离、高斯椭圆半径是否覆盖 tile、opa 是否本身很小这四个条件来跳过低效计算。
- 三是设计 cache 机制并用 z-order 扫描减少渲染 tile 时的不规则访存。
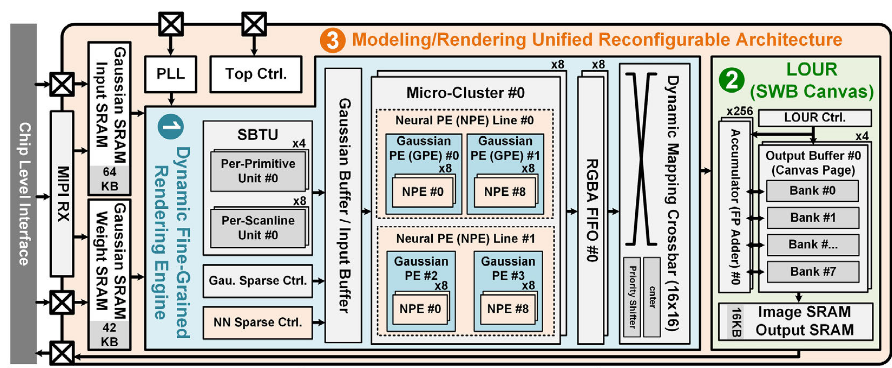
A 1286fps 0.39mJ/Frame Modeling/Rendering Unified 3D GS Processor with Locality-Optimized Computation and Reconfigurable Architecture(ASIC 流片,支持前馈高斯建模和前向渲染的处理器)
动机与分析:传统 3DGS 为分钟级重建,用前馈高斯来实现更快的建模。前馈高斯和传统高斯的高斯特征分布以及数据流不同,适用于传统高斯的加速器直接用在前馈高斯上性能不佳。第一,前馈高斯会产生更多更小的局部高斯,传统高斯中 256 的 blocksize 用在此处会有大量 PE 空转浪费计算资源。第二,更多高斯数量导致传统高斯复制+tile 排序的过程成为性能瓶颈,中间变量读写使得外部访存开销巨大。第三,前馈高斯需要支持异构乘法累积操作和光栅化数据流分别用于建模和渲染,异构架构会增加额外的面积开销。
实验设置与结果:工作频率 80-680MHz。渲染模式支持基于优化的传统高斯模型(在 NeRF-Synthetic 数据集上)和前馈模型(在 RE10K 数据集上)。680MHz 下帧率 1286FPS,功耗 507mW,建模模式下功耗 1067mW。80MHz 下每帧仅耗 0.15mJ。前馈算法将建模时间缩短到 1.2s。处理器支持稀疏计算(跳过零值计算)和 FP8 量化,推理时间缩短至 0.3s。
具体方法:
- 一是将原来 256 个 PE 的阵列拆成小计算块 Micro-Cluster,每个负责一个高斯,而不是一整个阵列只处理一个高斯,文中称为 DFGRE 架构。每个 MC 动态分配只处理一个高斯,每个 MC 中包含四个 GPE,GPE 负责计算高斯对一个像素的贡献,一个 MC 计算一个高斯对一个 2x2 像素块的贡献,得到的 RGBA 结果保存在 FIFO 中,再由后续调度累积到图像上。一个 MC 拿到一个 GS 后先提取边界(类似于 AABB 框,但文中用的是 SBTU,SBTU 定位了 alpha 等于预定义值的椭圆,可以提取基于扫描线的边界),然后以 2x2 像素块为单位遍历这个边界内的所有像素,完成后再取下一个高斯。
- 二是高斯跨多个 tile 会导致 binning 和大量外存访问,提出 LOUR,让每个高斯只属于一个滑动窗口处理。将 tile 改成一个窗口在图像上滑动,高斯中心属于哪个窗口就在哪个窗口渲染,不再复制到多个 tile。高斯跨窗口时,用 core region + padding region 的方式,文中为 16×16 window 和 8×8 core。另外,论文提到,在训练时加入了 Scale-Penalized Gaussian (SPG)来限制高斯过大。窗口按照行列方向扫描,保证 core 不重叠但 window 重叠。这样每个像素的最终写入只在一个 core。另外,论文提到,高斯是顺次取用且不用排序的,每个高斯来了直接找到对应 window 然后光栅化。整个流程是:Gaussian stream↓project to screen↓compute center↓find window index↓rasterize inside window↓accumulate to SWB canvas↓window 完成 ↓ 写入 framebuffer↓window 移动。另外做一个知识上的补充,原版高斯的 alpha compositing 才会需要从前到后的排序,而如果把渲染改成了 weighted sum,就不需要排序了。 这篇论文使用的是 sort-free / weighted-sum 方案。当然,weighted sum 并不是这篇文章的贡献。滑动窗口画布使用了四个 pingpong buffer 交替进行读、写和计算任务。
- 前两个贡献的关系是这样的:LOUR 工作流负责确定各个高斯分别在哪个 core 里渲染,确定好后由 DFGRE 具体处理计算,计算结果通过 DMC 这个 crossbar 写入这个基于滑动窗口的画布(crossbar 用于调度 pixel 写入,否则多个 MC 同时写 pixel 可能造成 bank conflict,比如两个 RGBA 同时涉及同一个像素位置,写地址冲突),画布内进行加权和得到颜色,window 完成后写入 framebuffer。
- 三是设计了一套可以切换的同一架构,让同一套计算单元和存储结构既能做建模也能做渲染。前馈高斯中既要对高斯进行渲染,还要运行神经网络生成高斯。把同一组 processing unit 在不同模式下重新配置。(切换数据流+PE 重配置)。
A-SSCC
A 66.6 FPS High Quality Gaussian Splats Rendering FPGA Processor with Reconfigurable Computation Architecture(FPGA,加速 3DGS 前向渲染)
动机与分析:在边缘设备实现实时 3DGS 渲染具有挑战性,主要有三个原因:一是由于计算密集型特性,体渲染阶段占用了系统延迟的 59.4%,二是 SH 频段参数比片上内存(Cyclone V)高出 114.4×,三是渲染过程在每个阶段都需要多种矩阵操作。
实验设置与结果:基于 Intel Cyclone V 实现,最大时钟频率为 200 MHz,渲染帧率 66.6FPS,功耗 3.6W,54.1mJ 每帧。基于合成 NeRF Synthetic Lego 和 T&T Truck 数据集测试。资源使用:LUT 为 103342,DSP 为 288,Block Memory 为 7340032bit(约 896KB)。使用 FP16。
具体方法:
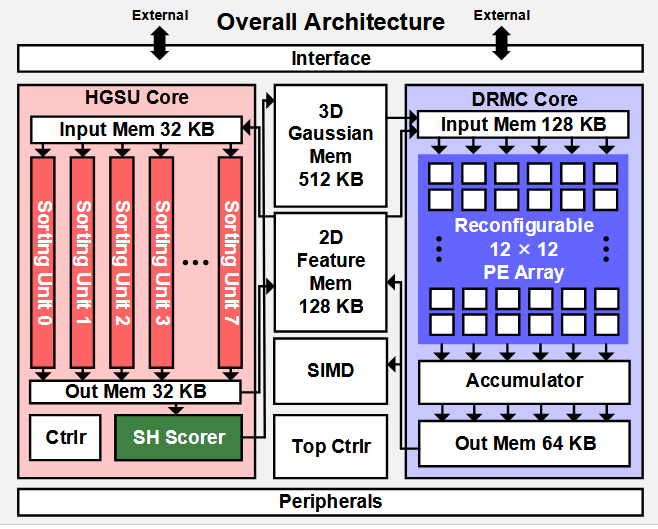
- 一是设计分层排序单元(HGSU),分三级逐渐筛选;第一级用深度 16bit 中的高 4bit 中的两组(共 8bit)进行 4bit radix sort,完成按深度的粗略分组;第二级对每一组估计 alpha 总和(直接把高斯的 alpha 相加做粗略估计,不计算精确的实际 alpha 贡献),如果小于阈值则说明对最终颜色贡献小,直接跳过这一组高斯;第三级再对留下来的高斯进行 16bit radix sort 排序。文章中这个分层排序是基于 tile binning 之后的结果做的,也就是已经将高斯分到了 tile 上,只是没有进行 tile 内按深度的排序。
- 二是使用同一套 PE 根据矩阵维度动态重配置。由于渲染流程中涉及许多维度不统一的矩阵运算,如果给每一种维度都开一个专用单元,很多计算单元会限制,比如 PE 是 4x4,在算 3x3 的时候就会有 7 个 PE 闲置,文中测量 PE 利用率只有 53.7%。每个 PE 可配置为执行 axb+c 的 MAC 或 axb 的 MULT,这样提高了 DSP 的利用率。
- 三是预测哪些高斯不重要,对这些高斯只计算低阶 sh。由于 sh 存储和计算开销大,许多高斯对最终画面贡献很小,即使存在也只提供很平滑的颜色,不需要完整的 sh。只有 scale 或 opa 超过阈值的高斯才被认为是重要的高斯,进行完整计算,否则只计算 0 阶 sh。
ISCAS
A Real-time 4.31 mJ/Frame Neural-3DGS Processor with Voxel Similarity Memory Management and Opacity-based Sparsity Generation(ASIC 流片,加速 Scaffold-GS 实时低功耗推理)
动机与分析:原版高斯需要在每一帧均访问高斯特征,内存占用高。因此提出 Neural-3DGS 这类方法将场景体素化,并将体素中的高斯分组,用神经网络训练二维特征。在新视角合成时,由神经网络推理体素特征,内存效率(dB/MB)4x。Neural-3DGS 采用图块处理(16×16 像素)处理,相邻的 tile 具有高度的几何相似性,导致重复体素的冗余外部访存和计算。对生成的 GS 进行排序(约 230K)限制了系统延迟,且无法与神经网络推理以及体渲染(矩阵乘法,MM)共享计算单元。神经网络推理以及体渲染计算量庞大,每个过程都需要不同的尺寸和精度。因此需要一个支持多种配置且工作负荷较低的计算单元。
实验设置与结果:200MHz,在 NeRF-Synthetic 数据集上测试,FP8 和 FP16 混合精度,98.8-132.4FPS,231.6mW,2.34/4.31mJ 每帧。
具体方法:
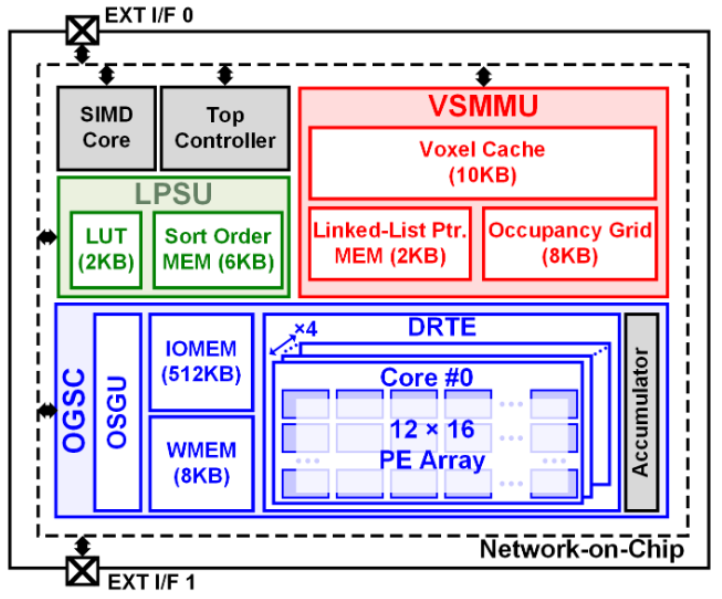
- 一是体素相似度感知内存管理单元(VSMMU),利用体素之间的相似性,减少重复数据访问和计算。相邻 tile 的 voxel 很多是重复的,因此缓存已经计算过的 voxel 结果,如果下一个 tile 需要同一个 voxel,可直接用 cache 中读取,减少 EMA 和 NN 推理。
- 二是用 LUT 提前存好排序结果,避免实时复杂排序计算。论文提出,一个 voxel 内的高斯排序是固定的几种模式,视角方向只有有限变化,因此排序结果只可能是少数几种排列,只需要 3 种 planar+4 种 axis,加上它们的反序共 14 种排序顺序。这样就根据视角方向选择对应的排序模板,不再实时排序。
- 三是根据 opa 来判断哪些高斯对图像贡献很小,从而跳过这些高斯的计算。低 opa 的高斯生成 skip index(打上 01 的 mask,0 的表示跳过,1 的表示计算),后根据 run length encoding(游程编码)来压缩索引。RLE 是一种无损数据压缩方法,把连续重复的数据,用“值 + 重复次数”来表示。另外设计可重构的统一计算单元,MAC 可以重新组合来支持不同矩阵计算大小。
HyperGS: Efficient Real-Time 3D Gaussian Rendering Processor Through Hierarchical Sorting(FPGA 加速 3DGS 渲染)
动机与分析:低性能边缘设备上排序所占用的时间比例更高,主要原因是在分拣数百万高斯时存在 DDR 内存带宽瓶颈。GS-Core 试图通过消除冗余的排序过程和优化 3D-GS 中的超参数来解决瓶颈问题。然而,GS-Core 中排序硬件设计不完整,限制了其处理深度不均和数据大小可变的高斯量的能力。(GSCore 在粗粒度阶段用比较排序,在深度分布均匀时好用,但现实场景的高斯深度分布通常不均匀,比较排序会产生不规则的数据流,比较次数不可预测,对硬件实现不友好。GSCore 在细粒度阶段用双调排序,这是一种硬件友好的结构固定的可并行排序方法,但只能处理固定数量的数据,3DGS 中每个 tile 的高斯数量是不固定的。)
实验设置与结果:在 Zynq UltraScale+ MPSoC ZCU104 评估套件上实现,基于 Deep Blending 和 Tanks & Temples 数据集测试。为了电路稳定运行,缩短了组合逻辑路径以达到更高时钟频率并防止因时钟域交叉导致的数据拥堵,经过时序分析之后,将基数排序引擎(RSE)模块配置为 250MHz 工作,其余加速器模块设置为 300MHz。使用了浮点计算 IP 来提升性能并优化资源使用。
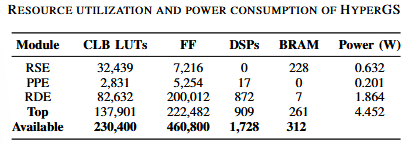
资源使用和功耗如下表,BRAM 使用率高主要是由于 RSE 对高效分拣操作所需的片上内存需求。RDE 是资源最密集的模块,消耗 82,632 个 CLB LUT、872 个 DSP 和 1.864W 的功耗,主要原因是大量使用 DSP。DDR4 内存接口使用超过 15,000 个 LUT,为整体功耗增加约 1.75W。
帧率、功耗和内存带宽需求如下表

具体方法:
- 一是设计了一个 Radix Sort 的排序单元,并且用这个排序单元将排序过程分开,先进行按 tile 的排序,然后进行按深度的排序;其中深度排序和光栅化利用 pingpong buffer(双缓冲 BRAM)来并行运行。当第一个 tile 排序完成,即可立即开始光栅化,后面的继续按深度排序。
- 二是在一的基础上完成了高效、全流水线设计的 3D 高斯预处理与光栅化计算引擎,每个时钟都能处理新的高斯,具备 300 MHz 高速光栅化能力。光栅化按照原版高斯实现,并按照原版逻辑设计跳过的逻辑。
- 三是渲染流程中去除了冗余的三维协方差计算,减少了 18%的预处理计算。scale 和 rotation 是与相机位置无关的模型参数,即 cov3D 的计算与相机姿态无关,原始 pipeline 中每次都算,因此将 cov3D 提前算好并存入模型。
- 四是在一的基础上可以按 tile 顺序访问片外内存,渲染速度比 GPU 实现快 44 倍,带宽消耗降低 7 倍。
DATE
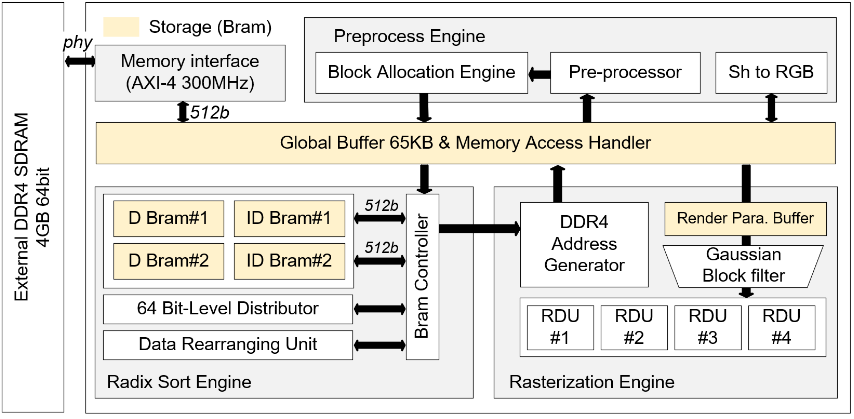
FAMERS: An FPGA Accelerator for Memory-Efficient Edge-Rendered 3D Gaussian Splatting(中低端 FPGA 加速 3DGS 渲染)
动机与分析:大量高斯原语的使用带来了内存密集型操作带来的挑战,这可能阻碍其在边缘中的可行性。轻量化高斯相关的工作聚焦于压缩高斯模型尺寸,然而高斯特征的中间结果仍然需要大量存储资源,导致片外访存压力大。GSCore 提出集中于优化高斯瓦交叉测试的 AISC 设计方案,但随着算法发展,底层硬件的灵活性很关键,因此 FPGA 成为更理想的平台。分析显示,光栅化占整个渲染时长的 50%以上。延长的执行时间主要源于投影高斯(Gi2D)与像素之间的大量交集,而像素通常比高斯多出两个数量级。对渲染过程的进一步研究表明,只有极少数高斯分布器对栅格化有显著贡献。除了渲染时间,还必须考虑对内存消耗的影响。GPU 实现要求以深度顺序格式存储和排序整个投影高斯数组(Gi2D)及其像素交集。这种做法带来了两个重大挑战。首先,该阵列的内存占用空间可能占用显存的相当大面积,考虑到模型大小,内存占用量常常超过 2 GiB。因此,最小化 FPGA 与片外内存之间的内存访问是我们加速器设计的关键方面。其次,预处理、排序和光栅化阶段之间的数据依赖关系在 GPU 实现中形成串行执行模型,这为 FPGA 架构带来了一个有前景的优化机会。
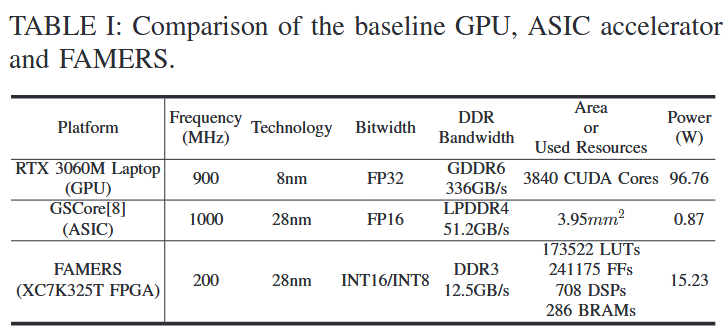
实验设置与结果:在 Xilinx Kintex-7 325T FPGA 上实现,基于 Mip-NeRF360、Tanks & Temples、Deep Blending 数据集测试,200MHz,与协方差矩阵相关的参数量化为 int16,而 SH 系数和不透明度则量化为 int8,因为 SH 系数对图像质量的影响极小。用了剪枝、聚类、量化,实验证明对图像质量影响不大。
资源利用和功耗如下表
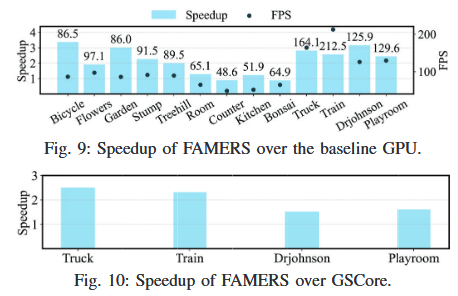
帧率和相较于其它方案的加速比如下表
具体方案:
- 一是集成了模型剪枝与聚类来最小化内存需求,对 fpga 友好并提升渲染速度。使用 Mini-Splatting: Representing Scenes with a Constrained Number of Gaussians 这个工作的方案来减少高斯数量,使用 Compressed 3D Gaussian Splatting for Accelerated Novel View Synthesis 这个工作的聚类和码本方案来压缩。
- 二是根据高斯中心坐标预排序,这样只用相关的高斯子集渲染特定图块,从而无需保留整个高斯 tile 对。传统高斯按照均匀网格分 tile 不行,高斯可能很大二跨多个 tile,仍然需要计算所有高斯 tile 对。首先是在训练阶段用 Mini-Splatting: Representing Scenes with a Constrained Number of Gaussians 和 RadSplat: Radiance Field-Informed Gaussian Splatting for Robust Real-Time Rendering with 900+ FPS 的方法根据重要性评分将大高斯 split 成小高斯,保证绝大部分高斯是局部的。然后把整个场景的高斯按半径分桶,极少部分半径大于 128 的高斯认为对全局有重要影响,直接保留;其余小高斯根据半径分到不同的桶里,所有半径桶里的高斯合起来才构成整个场景。对于每一个半径桶里高斯的处理,离线预处理建立分层网格,对于当前 grid 计算 grid 面积和 grid 中高斯数量乘积,超过阈值则继续均匀划分为 8 块(gird 太拥挤就继续划分,足够稀疏才停止),直到所有 grid 都划分成叶子 grid,最终每个桶得到一个根据高斯中心位置分布产生的不均匀空间树(高斯密集的地方,grid 划分得也会更小),每个高斯只属于一个 grid。然后下面都是在线过程,在渲染时,对于某一个视角,对于某一个桶,先遍历 grid 树每一个 grid,对某一个 grid,将八个顶点投影到二维平面并按 radius 进行一定扩展(防止超出 grid),然后找这个投影与哪些 tile 相交,对每个相交的 tile,把这个 grid 标记为相交。渲染某个 tile 时,取出与这个 tile 相交的 gird 中的高斯进行渲染计算。
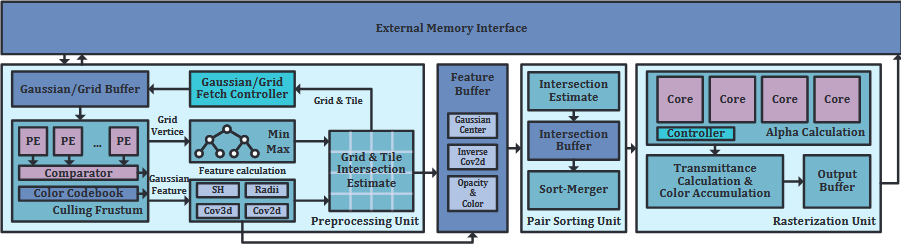
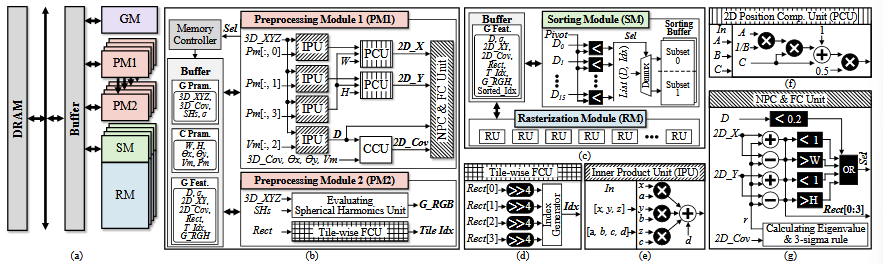
- 三是设计 tiling 和流水线执行方法,允许对每个 tile 独立处理,减少了计算过程中的内存占用,便于设计针对 fpga 实现的架构。由预处理单元、配对分拣单元和光栅化单元构成。预处理单元负责确定与瓷砖的高斯交点并计算其特征;配对分拣单元用了这个 SPAGHETTI: Streaming Accelerators for Highly Sparse GEMM on FPGAs 工作的流水线式的排序合并,实现了两个排序合并和乒乓缓冲区,便于深度队列间的无缝切换;光栅化单元由 α 计算引擎和透射计算与颜色累积引擎两个主要组件组成。
PS-GS: Group-wise Parallel Rendering with Stagewise Complexity Reductions for Real-time 3D Gaussian Splatting(ASIC 仿真,加速 3DGS 前向渲染)
动机与分析:Orin 上的 Ampere GPU 运行 3DGS 渲染帧率不足 5FPS。先前工作做了剪枝和量化;GSCore 用了分层排序来增强流水线并行性,用了高斯形状交叉感知测试来跳过无效计算,但仅考虑了排序阶段,没有考虑到整体过程的流水线并行性,且没有解决预处理阶段的复杂性,预处理的计算负担与排序阶段复杂性相当。分析表明,当高斯分布的近似深度顺序(基于当前视点)已知时,可以提升预处理、排序、光栅化流水线的并行度。为了避免图像质量下降,分组应根据当前视角进行精心调整。文中介绍了直接沿用分组方式可能导致颜色计算不正确。
实验设置与结果:采用 RTL 实现,并采用 28nm CMOS 技术的 Synopsis Design Compiler 合成。使用 Synopsys PrimeTime PX 进行功耗和能耗模拟。加速通过周期级模拟器实现,DRAM 带宽为 51.2GB/s,DRAM 能量基于 [16] 计算。数据集用 Tanks&Templates、Deep-Blending、Mip-NeRF360,用 A6000 进行 30k 轮预训练。32 位浮点训练的模型被转换为 16 位浮点。面积为 3.874 平方毫米,功率为 1.039 瓦,工作频率为 1GHz。PS-GS 配合并行渲染时,平均速度提升为 1.75× 和 1.2×,支持 117 帧/秒的实时渲染。
具体方案:
- 一是提出按深度聚类的并行渲染方案。离线基于距离对高斯分布,采用 K 均值聚类算法进行分组。聚类通过预训练模型离线进行,而在线(实时)阶段则使用聚类参数(重心和半径)进行视点自适应分组。
- 二是提出视点自适应分组,根据视角调整聚类的分组顺序,否则渲染会出错。
- 三是基于聚类的预处理、排序和分组。以 cluster 为单位做深度计算、视锥裁剪,对 cluster 做排序(得到高斯的近似排序),按顺序把 cluster 分为几个 group,然后按 group 顺序进行并行渲染。
- 四是基于上述方案实现完整的硬件计算流。
ICCAD
No Redundancy, No Stall: Lightweight Streaming 3D Gaussian Splatting for Real-time Rendering(ASIC 仿真,3DGS 前向渲染加速)
动机与分析:大量高斯导致内存和计算开销巨大,边缘平台难以实现 3DGS 实时渲染。量化、剪枝和 LOD 方法会降低渲染质量且需要昂贵的重训练。目前的硬件架构创新的工作缺乏整体流水优化且忽略了帧间相似性。计算冗余主要源于两个方面,一是视角变化小,无需对每一帧完全重新渲染;二是高斯 tile 交集会引入大量无效对。硬件资源利用效率可优化的点在于存在区间空闲和区内气泡,这些气泡源于瓦片工作负载不平衡且不可预测。将图块简单地分配到渲染块,无法实现负载均衡。
实验设置与结果:在 NeRF-Synthetic、T&T、Deep Blending、MipNeRF360 这些数据集上测试。以 Orin 为 baseline,对比了 GSCore 和 MetaSapiens 这两个硬件加速方案。 RTL 设计并用 Synopsys 以 16nm FinFET 技术仿真实现,总设计面积仅为 1.84 平方毫米,比 GSCore 的 16 纳米(1.45 平方毫米)比例设计仅增加了 0.39 平方毫米,且明显小于 Jetson 系列边缘 GPU(350 平方毫米)和 MetaSapiens(2.73 平方毫米)。相较于其它算法和硬件加速方案在各个测试的场景上均有数倍速度提升。
具体方案:
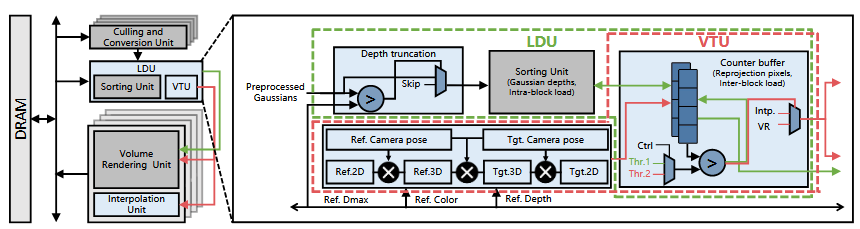
- 一是算法方面,利用相邻的相似帧,不使用传统的逐像素复用方案,而是以 tile 为单位,对每个 tile,缺失像素少则直接插值,插值像素不参与下一帧以避免误差不断传递。利用上一帧的深度信息预测当前帧每个 tile 的 early stop depth,超过这个深度的高斯直接跳过。根据高斯 opa 衰减计算真实影响范围,用椭圆而不是圆,然后用距离判断高斯是否真的与 tile 相交。
- 二是架构方面,基于 GSCore 设计,实现算法部分的逻辑。设计 LDU 来平衡工作负载,估算 tile 的真实工作量,然后更均匀地分给不同的光栅化 block。先用上一帧预测出的深度截断阈值丢掉多余高斯。引入了 z order 编码,把空间上相邻的 tile 倾向于分配到同一个光栅化 block。然后按顺序把 tile 送入 block,维护当前 block 类累积的 workload,计算一个理想平均负载并根据此计算一个阈值,如果累积工作量超过阈值就把 tile 分配到下一个 block。
DAC
GS-TG: 3D Gaussian Splatting Accelerator with Tile Grouping for Reducing Redundant Sorting while Preserving Rasterization Efficiency(ASIC 仿真,3DGS 渲染加速)
动机与分析:边缘设备实时渲染难,算法轻量化方案需要重新训练来补偿渲染质量的下降,能够在不牺牲质量的前提下提升流水线效率的算法优化工作相对稀少。GSCore 用 OBB 减少了交集,FlashGS 提供了一种更精确的 tile 选择方案,并提出了高效运行于 GPU 上的流程。分析发现,增加瓷砖大小减少了冗余的预处理和排序操作,但增加了不必要的光栅化计算,以往的工作凭经验选择 tile 尺寸。大 tile 有利于 preprocessing / sorting,小 tile 有利于 rasterization,两者存在根本冲突(trade-off)。
实验设置与结果: 采用 RTL 实现,并使用 Synopsys 设计编译器和 28nm CMOS 技术进行合成。使用 Synopsys PrimeTime PX 模拟功耗和能耗,速度提升则通过周期级模拟器进行评估。DRAM 带宽设置为 51.2 GB/s,DRAM 能耗基于 [16] 计算。基于 Tanks&Temples、Deep Blending、Mill-19 和 UrbanScene3D 这些数据集测试。1GHz,1.063W,baseline 是 GSCore,帧率比 GSCore 快 1.54 倍。
具体方案:
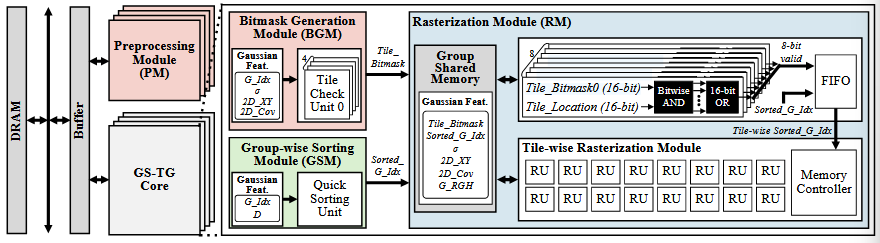
- 一是算法上,把多个小 tile 组成一个“大 tile group”来做 sorting,再用 bitmask 在小 tile 上做精细 rasterization,实现两阶段解耦。预处理不变,tile 分组,如 16 个 tile 为 1 组,找出每个 group 受哪些高斯影响。group 内共享同一批高斯,对 group 做 sorting 避免 tile 级的重复计算。对每一个高斯生成一个 bitmask,每一位表示一个 tile,用于在 group 内快速判断高斯是否影响这个 group,然后在 tile 上做光栅化。
- 二是将上述逻辑实现,多实例化几份来提升吞吐。
GSAcc: Accelerate 3D Gaussian Splatting via Depth Speculation and Gaussian-centric Rasterization(ASIC 仿真,3DGS 渲染加速)
动机与分析:边缘设备部署 3DGS 计算效率和内存需求面临巨大挑战。原始 3DGS 三个步骤有依赖难以流水线化。相邻帧变化小,高斯的 depth 和 sorting 顺序变化不大。每个 tile 涉及许多高斯,但每个高斯只涉及少数 tile。高斯按深度处理,相邻高斯空间位置接近,影响的 tile 有 overlap。
实验设计与结果:开发了一个架构模拟器,用于模拟周期数和芯片外存储访问次数。我们使用与 GSCore 相同的 LPDDR4-3200,最大 DRAM 带宽为 51.2GB/s。DRAM 访问时间通过 Ramulator [7] 模拟,DRAM 功率通过 DRAMPower [8] 模拟。为了准确估算片上功耗和面积,我们在 SystemVerilog 中实现了 RTL 设计。该设计采用 Cadence Genus,采用 Intel16 技术,在 500MHz 频率约束下实现。浮点算术单元来源于 Cadence 芯片软件 IP,缓冲区 SRAM 则由英特尔的 SRAM 编译器生成。基于 Tanks & Temples 和 Deep Blending 数据集。训练模型来自 CompGS,参数被量化为 FP16 以便与 GSCore 比较。以 PPA,即每平方毫米每瓦的渲染帧数(FPS/mm2/W)作为关键指标,比 GSCore 平均高出 1.41 倍。
具体方案:
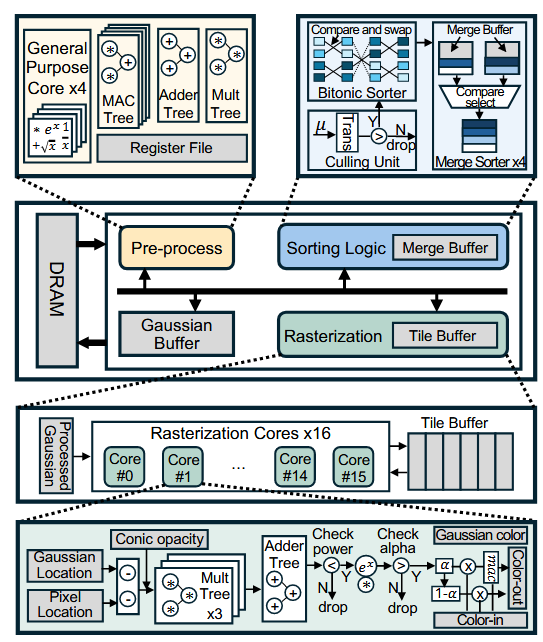
- 一是算法上,把根据上一帧视角算出的 depth 和 sorting 复用到下一帧。view matrix 和 proj matrix 会矫正当前帧。sorting 结果复用上一帧这样就不用等排序结果,预处理和光栅化是流水线的了。这样将 sorting 从前台阻塞移到后台异步,在光栅化计算的这个时间窗口内再用当前帧的视角把下一帧要用的 sorting 算完,即对下一帧的高斯进行了按深度的排序。另外,光栅化部分从面向 tile 改成面向高斯,即对于某一个高斯,更新它影响的 tiles;这样预处理和光栅化可以并行。整个 pipeline 为:渲染当前帧时,流水式地预处理每个高斯,这里的每个高斯已经是按照上一帧的 depth 排序过了的顺序,预处理完之后接着流水光栅化,同时在这个时间窗口内计算下一帧的 depth(下一帧的视角是预先可以拿到的),直到处理完这一帧的所有高斯。另外,把 overlap 的 tile 数据保留在片上缓存中不写回 DRAM。
- 二是架构上,预处理单元用 4 个 MAC 算矩阵,加法树、乘法树算 sh,通通 ALU Core 算开方、指数和平方根倒数。排序单元由 32way 的 bitonic 排序和 4 个 merge 排序构成。光栅化单元按原逻辑实现,由于计算量大实例化多份。
Local-GS: An Order-Independent Gaussian Splatting Training Accelerator Exploiting Splat Locality(ASIC 仿真,3DGS 训练加速)
动机与分析:移动平台部署难,现有工作聚焦于渲染阶段,边缘 NVS 部署的训练则复杂得多。预训练的 NVS 模型通常灵活性较差,仅渲染加速器无法对不同场景做出按需响应。3DGS 的反向传播受深度顺序依赖,需要反向遍历 Gaussian,并且要存中间结果;同时通过 densification/pruning 动态调整 Gaussian 数量。3DGS 的训练瓶颈主要来自反向传播(> 70%),并且受限于内存不足和一个高斯只影响少量像素导致大量线程空闲,造成严重硬件利用率低。
实验设置与结果:采用 RTL 开发,I/O 缓冲区和 CPU 主存由商业 SRAM 编译器生成。该设计由 Cadence Genus 合成,采用 7nm 技术实现,Cadence Innovus 在 1GHz 频段实现。算法对比方案为 3DGS 和 Sort-free GS,硬件对比方案为 GSCore 和 Jetson NX 数据集包括 Tank and Templates、Deep Blending 和 Mip-NeRF 360。
具体方案:
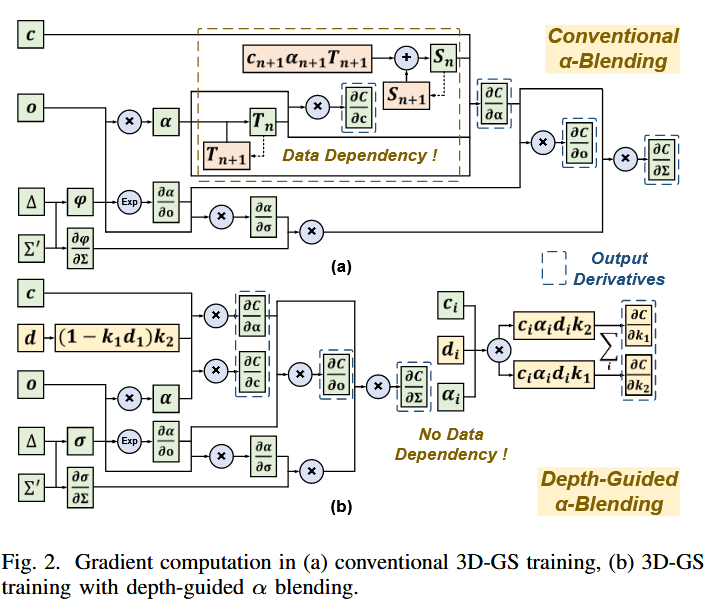
- 一是通过采用“深度加权”替代传统 α-blending 的累积透明度 T,消除了 Gaussian 之间的顺序依赖,实现完全并行的渲染和反向传播。
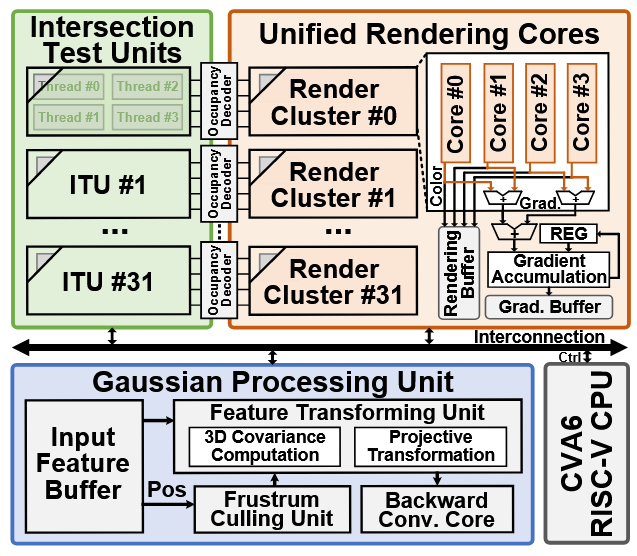
- 二是架构上分为高斯处理单元、32 个渲染核心集群、32 个交集测试单元以及 RISC-V CPU 核心。高斯处理单元进行视锥剔除、将 3D 特征转为 2D 特征并变换坐标基矢量以辅助交集测试,还包含一个小卷积核来简化 SSIM 计算,交集测试单元在局部进行增量式的并行高斯交叉测试,生成是否相交的 mask 标志并进行压缩,压缩后的位图随后被解码为连续的像素流,用于渲染核心的工作负载分配。渲染核心集群用于并行体渲染和反向传播。CPU 核心用于编程和通用状态控制。
- 三是用高斯中心+增量搜索+可分离高斯核(将 2D 高斯计算解耦 1D 高斯计算)实现局部像素检测,实现精确稀疏可并行的计算,可以增量计算,复用 exp 计算结果,用 LUT 和累加实现。渲染核心做成支持前向反向两种模式的 core,并且以高斯为中心进行调度,只处理高斯相关的像素。
STREAMINGGS: Voxel-Based Streaming 3D Gaussian Splatting with Memory Optimization and Architectural Support(ASIC 仿真 3DGS 渲染)
动机与分析:边缘设备的 3DGS 实时渲染难。先前的研究聚焦于优化计算性能,忽略了芯片外的内存流量。现有方法侧重于 tile 为中心的渲染范式,这需要在阶段之间进行过多的数据通信,导致频繁的片外流量,分析表示这会超过当前移动设备在真实场景上的带宽限制。对于真实场景,DRAM 带宽需求超过了最近发布的移动设备 Nvidia Orin NX 的带宽限制。这意味着仅凭数据通信需求就无法实现实时通信。投影和排序主导了整体芯片外数据通信,合计占总 DRAM 流量的 90%。中间数据通信占总芯片外流量的 85%。这一结果促使我们提出一种全流式算法,以最小化芯片外流量。
实验设置与结果:排序单元和渲染单元分别与 GSCore 中的双调排序单元和体积渲染单元相同,1GHz 时钟频率,采用 EDA 工艺开发,并结合 Synopsys 和 Cadence 工具,采用台积电 32 纳米 FinFET 技术进行综合。SRAM 组件的计算标准为 CACTI 7.0 [23],采用 32 纳米工艺。我们仿真中的 DRAM 模型基于美光 16Gb LPDDR3,能耗数据来源于美光系统功率计算器 [25]。数据集为 Synthetic-NSVF、Synthetic-NeRF、Tanks&Temples 以及 Deep Blending。算法对比方案为原始 3DGS、MiniSplatting 和 LightGaussian。硬件对比方案为 Orin NX 和 GSCore。帧率是 Orin 的 45.7 倍。
具体方案:
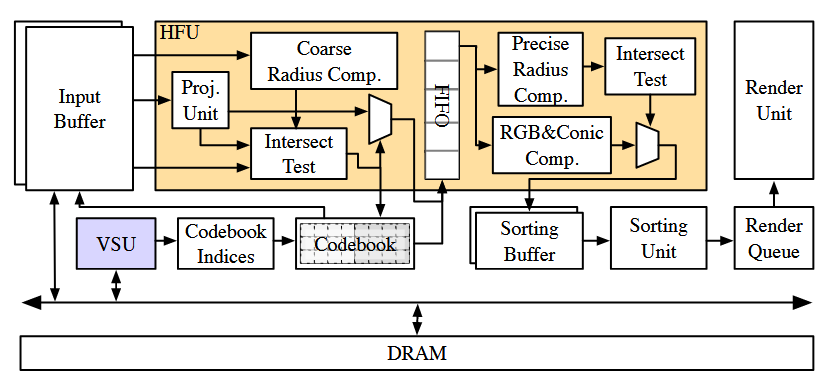
将 tile 为中心改成按体素逐块流式渲染,先对每个像素组找出其射线传过的体素,构建 DAG+拓扑排序得到全局体素渲染顺序,随后按顺序逐个体素处理。在每个 voxel 内通过“粗筛 + 精筛”的层次化过滤减少需要处理的 Gaussian,再进行排序与渲染并累积得到最终像素值,从而保证所有中间数据都能保留在片上。
提出分层过滤,逐步排除无关的高斯分布。将每个高斯特征分成两半,并有意保持前半部分的轻量级。然后我们进行粗略但轻量级的计算,基于前半部分(即位置和半径)过滤掉无关点。接下来,我们进行精确滤波,通过加载后半部分进一步去除无关的高斯分布。减少特征加载的开销,我们用向量量化压缩后半部分。通过在芯片上存储紧凑的代码本,我们只需从 DRAM 获取它们的轻量级索引。通过这种方式,我们大幅减少体素流传输处的 DRAM 流量。
设计了一个高效的加速器(第四节),包括一个体素分选单元以加速体素渲染顺序的确定,以及一个专门的层级滤波单元,用于支持体素流的高斯滤波。给定一组射线方向,体素分选单元首先识别并排序相交的体素。然后,对于每个相交的体素,层级滤波单元应用分层滤波器来识别相交的高斯体素。一旦层级滤波单元获得过滤后的高斯,排序单元和渲染单元分别从各自的缓冲区执行排序和渲染阶段。排序和渲染设计均采用了 GSCore。
ASP-DAC
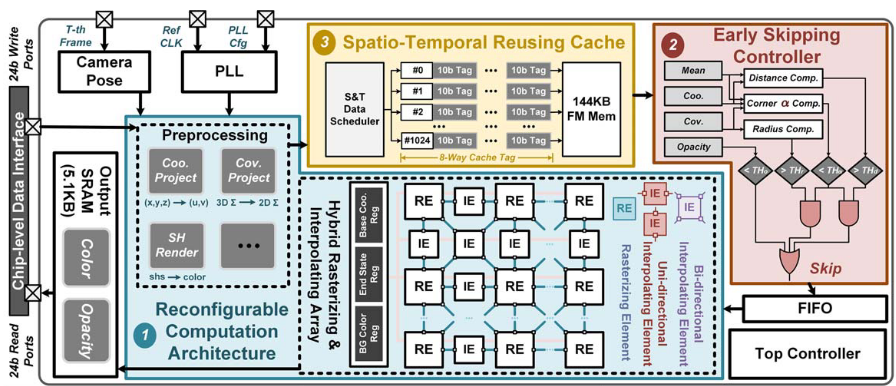
GSNorm: An Efficient 3D Gaussian Rendering Accelerator with Splat Normalization and LUT-assist Rasterization(ASIC 仿真,3DGS 渲染)
动机与分析:边缘平台上难以实时渲染。三维 GS 的渲染过程在计算上受限于光栅化过程,该过程包括大规模的并行浮点乘法和指数计算。这种瓶颈因瓦片分割过程中高斯重复的无效而进一步加剧。此外高斯排序过程也占用了相当大的总运行时间。AABB 太保守导致大量冗余计算;高斯分布不均,一个 pixel 一个 thread 下大量核心空转,利用率低。
实验设置与结果:以台积电 22nm 技术实现,GSNorm 加速器由 RTL 开发,I/O 缓冲区和 CPU 主存使用商业 SRAM 编译器生成。该设计由 Cadence Genus 综合,Cadence Innovus 在 500MHz 频率下实现。包含 8 个渲染核心和开源的 RISC-V CVA6 CPU。数据集包括 Task and Templates 和 Deep Blending。在线量化,int8 和 int12 混合精度。500MHz 下功耗 284mW,帧率在 90-106FPS。
具体方案:
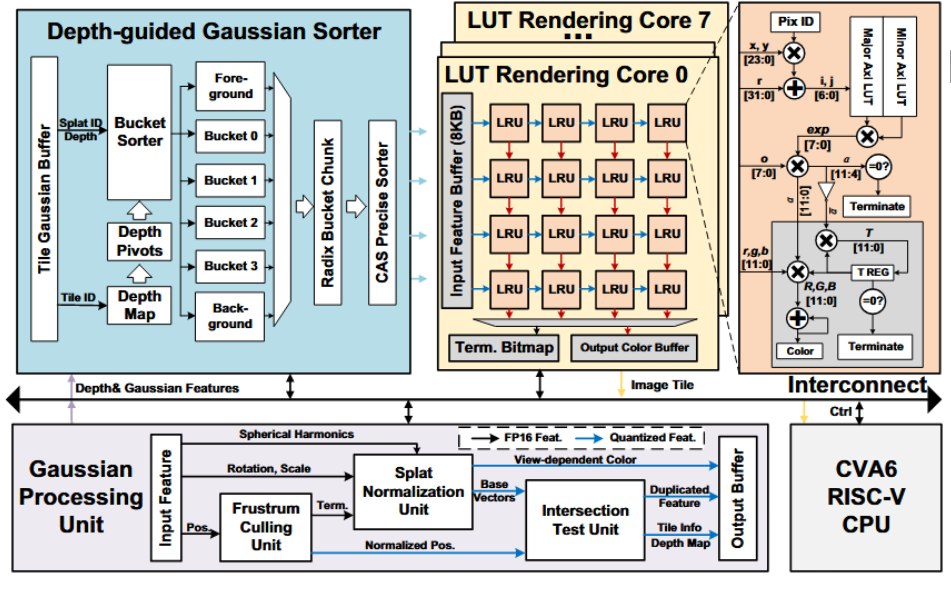
- 一是预处理模块进行视锥裁剪,然后通过做线性变换投影到 2D,然后用归一化矩阵将高斯椭圆变成圆;在对坐标做对应变换,将 alpha 的二维高斯计算简化为两个一维高斯的乘积。LUT 可以预存一部分,并且用查表代替 exp。变成圆之后自然会得到更紧的 bounding box。将 fp16 量化为 int8 和 int12。构建 depth map 给排序用。用 bucket-radix-CAS bitonic 三层排序减少数据规模,降低开销。
- 二是 render core 用 4x4 LUT 小核+全流水线+数据流传递,并用量化消除 pipeline 依赖。把一个 tile 拆成小的并行单元。每个 LRU 执行原版的光栅化计算。
MICRIO
GCC: A 3DGS Inference Architecture with Gaussian-Wise and Cross-Stage Conditional Processing(ASIC 仿真,3DGS 渲染)
分析与动机:3DGS 加速器采用的标准数据 流有两个主要限制,一是两阶段“预处理后渲染”方法引入了冗余的高斯运动和计算。在渲染阶段,α 混合中的早期终止策略导致渲染中使用的高斯分布量明显少于预处理的高斯分布量。这意味着对应非渲染二维高斯的三维高斯算子在预处理时可以完全排除。其次,逐瓦片渲染会针对相同的高斯分布产生重复的数据访问。这导致复制出的高斯 tile 对负载远超高斯数。
实验设置与结果:以 GSCore 为 baseline,数据集为 Tanks and Temples、Deep Blending、NeRF-Synthetic。SystemVerilog 实现,并使用 Synopsys 设计编译器与商用 28 纳米标准单元库、1 GHz 频率合成 RTL,以获得计算单元的面积和功耗。片上缓冲区采用 CACTI-P 建模 [22]。我们用 Python 开发了一个周期精确模拟器,用于建模数据流量和架构中关键计算单元的执行行为。每个硬件模块都被建模为专用的 Python 类,执行渲染流水线的功能正确计算,同时内部跟踪每次操作的周期级执行成本。所有模拟器的计算模块的执行周期均已通过周期级的 HDL 设计验证。为了匹配 GSCore 使用的内存配置,我们采用了 Micron LPDDR4-3200 DRAM 型号作为片外存储系统,峰值带宽为 51.2 GB/s。渲染帧率比 GSCore 快 5.24 倍。
具体方案:
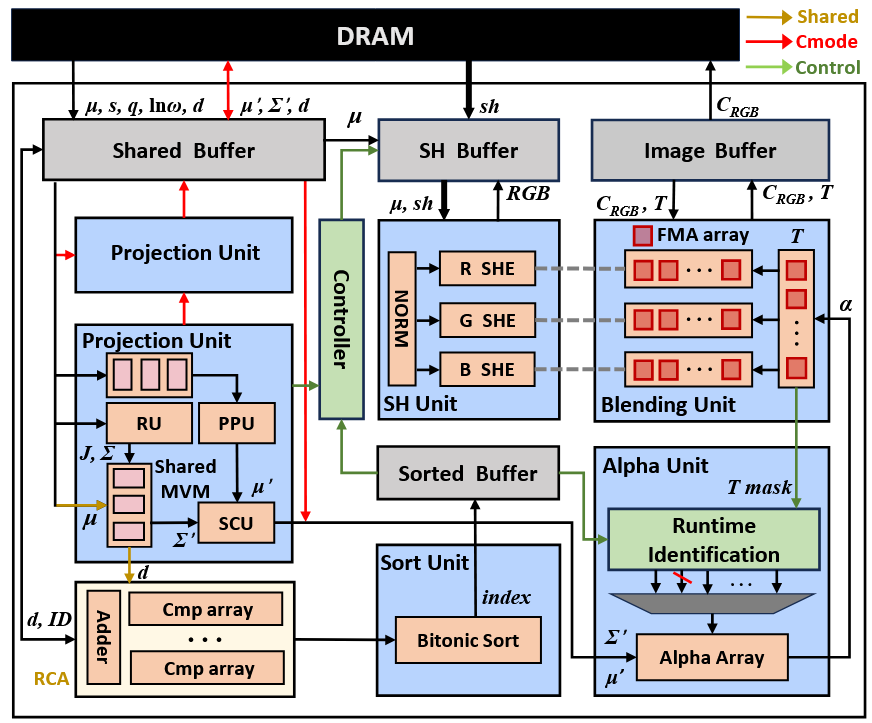
- 一是提出了一种新颖的数据流,其中高斯预处理与渲染交替执行。一旦满足渲染终止条件,剩余高斯的所有后续预处理和渲染操作将被跳过,从而有效消除了因不必要高斯预处理引起的冗余计算和数据移动。
- 二是按高斯而非按 tile 方式的渲染。为了避免在按瓦片渲染中重复对同一高斯加载,从最近的高斯开始,我们完成一个高斯的整个渲染,然后再进入下一个。在该方案中,每个高斯参数仅加载一次,显著降低了数据移动开销。
- 整个数据流梳理一下:所有高斯先按深度分组(按 depth 范围分桶),后面按组按高斯流式执行。在流式过程中动态 early skip,对一个 group 内每个高斯,先做投影看是否还在屏幕内,若还在继续算颜色并进行组内排序,在做 alpha blending,某些像素若已经达到终止条件就跳过。如果当前已经足够不透明,更远的 group 直接整租跳过。中间提出了 ω-σ law 来代替 3σ 来做 early skip。判断高斯影响哪些像素时,没有用 tile 的逻辑,用的是 α footprint 的动态搜索方法(从中心点开始一圈一圈向外扩,遇到 α 条件不满足的边界,就停止往那个方向继续扩展),找出来的候选像素做 alpha blending 计算。深度计算和分组在每个帧开始时作为独立的预处理阶段全局执行。
- 然后实现了上述的架构,里面有一些机制可以学习,具体这里不贴出来了。
ASPLOS
GSCore: Efficient Radiance Field Rendering via Architectural Support for 3D Gaussian Splatting(ASIC 仿真,3DGS 渲染加速)
分析与动机:移动 GPU 部署难。瓶颈在于交集测试,假阳性多。未使用的高斯分布被赋予瓷砖上的不必要赋值,不必要排序。在 tile-based rasterization 中,一个线程块(对应一个 tile)里的所有线程会同步处理同一个 Gaussian。
实验设置与结果:Synopsys 设计编译器与商用 28 纳米技术节点进行合成,1GHz 时钟频率,并且完全流水线。我们还实现了一个周期级模拟器,用于评估芯片外存储器设计的性能。该模拟器通过详细的 DRAM 时序建模 GSCore 架构,仿照 Micron LPDDR4-3200 搭配 Ramulator [26]。使用 FP16 与使用 FP32 相比,除了 α 计算中的指数函数外,并不会导致感知上的差异,所以用 FP16 以提高吞吐量。数据集为 Tanks&Temples、Deep Blending、Synthetic-NeRF、Synthetic-NSVF。对比方案为 Jetson NX。帧率 91.2FPS。
具体方案:
- 一是对长轴/短轴 > 2 的椭圆用轴向包围盒 OBB 代替 AABB。算法是 SAT(分离轴定理)
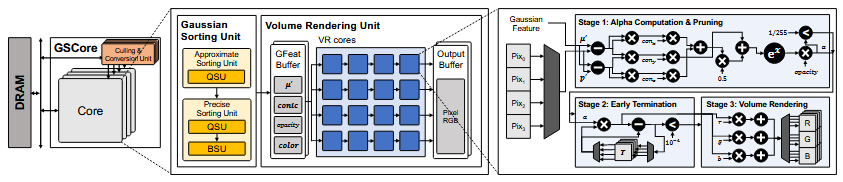
- 二是两阶段排序,先按深度将高斯分组,只保证组间排序,组内不严格排序,然后再真正需要时在对某个组内做精确排序,边排序边渲染。流程时先按 tile 分组高斯,每个 tile 内随机选一个深度,前半更近后半更远,精排序前半,如果提前终止则后面的 chunk 直接跳过,不再排序。硬件实现上用 QSU 多轮划分,知道 chunk 小到可以放入 VRU buffer。对 chunk 的精排序和渲染流式进行。QSU 用于对一个 tile 内的高斯做粗排序,本质是并行分桶。BSU 用双调排序,精排序。BSU 为 16 channels。注意 tile binning 再预处理阶段完成。每个 tile 有自己的 buffer 队列,当队列长度达到 chunk size 就送入 QSU 开始粗排序。tile buffer 只存 index 和 depth,高斯特征需要按需加载。chunk 是同一个 tile 里的一小批高斯。
- 三时 subtile skipping,每个高斯分一个 N-bit 的 bitmap 表示这个高斯是否会影响该 subtile。bitmap 为 0 时则跳过下面的光栅化。
Neo: Real-Time On-Device 3D Gaussian Splatting with Reuse-and-Update Sorting Acceleration(ASIC 仿真,3DGS 渲染加速)
动机与分析:对 GSCore 进行了全面分析,GSCore 缓解了光栅化中的瓶颈,使得排序成为新的瓶颈。排序阶段既“过于频繁(每帧全量排序)”,又“没有利用跨帧相似性”,导致大量冗余计算和严重的内存带宽浪费。
实验设置与结果:用 Synopsys Design Compiler 和 ASAP 7nm 库合成 Neo,对比 Orin 和 GSCore。Neo 相比 Orin AGX GPU 和 GSCore,吞吐量分别提升了 10.×0 和 5.6×,同时将排序引起的内存流量分别降低了 94.4% 和 81.3%。帧率 99.3FPS。
具体方法:
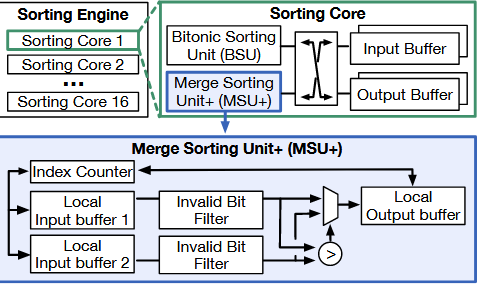
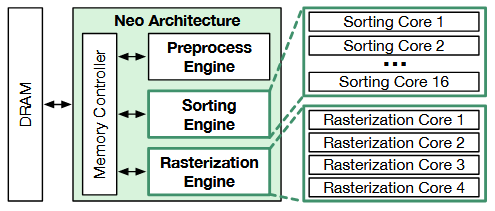
一是帧间复用排序结果,增量更新排序结果,只更新发生变化的部分。具体的算法实现这里省略了。
二是架构上设计专用的排序硬件,采用 partial + global 的 hybrid sorting。
HPCA
GSArch: Breaking Memory Barriers in 3D Gaussian Splatting Training via Architectural Support(ASIC 仿真,加速 3DGS 训练)
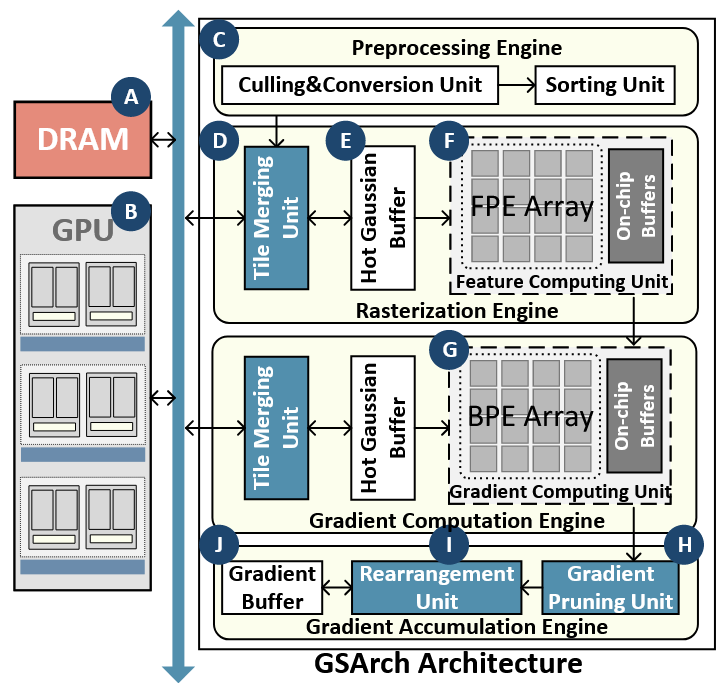
分析与动机:3DGS 训练加速有需求。根本原因在于内存障碍从片外存储器、顺序原子写入到片上存储器,以及在片上存储器读取冲突。由于高斯与 tile 是多对多关系,同一个高斯会被反复加载。面积较大的高斯访问频率高,面积小的访问频率低。atomic 操作太慢,由于多个像素同时更新同一个高斯的梯度必须用 atomic operation,导致串行化和高延迟。但不是所有梯度都重要,来自边缘区域的重要,平坦区域的梯度接近 0。另外再梯度累计阶段,多个 tile 同时请求高斯梯度,这些数据放在 multi-bank SRAM,如果多个情况命中同一个 bank,导致的 bank conflict 必须排队访问处理,延长了时间。
实验设置与结果:用 Verilog 实现,并用 Synopsys 设计编译器合成,使芯片面积和总功耗在 28 纳米技术下实现,频率为 500MHz。数据集有 Tanks&Temples, Deep Blending, Synthetic-Nerf, and MipNerf-360。baseline 有 Jetson AGX Xavier 和 A100 以及 GSCore。训练时间 3min。
具体方案:
- 一是访问频率高的高斯放在片上缓存上,低的仍然放在片外存储。
- 二是只保留 top-k 个大梯度。
- 三是收集一批请求,按 bank 分布筛选,选一组无冲突请求一起发射。
- 硬件实现了上面的架构,文中有详细描述,这里不列举了。
其它
这篇文章干了什么是,贡献点有哪些,做的是 ASIC 仿真还是有真实流片,是独立的 ASIC 加速器还是 FPGA 还是需要依赖 GPU 的协处理器
Accelerating 3D Gaussian Splatting with Neural Sorting and Axis-Oriented Rasterization(ASIC 仿真,3DGS 渲染加速)
动机与分析:边缘设备部署难。每个 pixel → 一个 PE 独立算 alpha,同一行 / 同一列的像素,Y 方向项 → 同一行共享,X 方向项 → 同一列共享。bitonic 排序面积开销大,且排序和光栅化的时间复杂度不匹配。每个 tile 的高斯数量不平衡,因此排序和光栅化的依赖关系导致资源浪费。传统上,排序是确保 α 混合时前后深度顺序正确的,因为透明度依赖于高斯分布的顺序可见性。我们的见解是分选的主要目的是产生一个衰变因子以促进混合,这促使我们探索基于学习的排序方法。我们提出了一种神经排序方法,能够用微小的神经网络预测衰减因子,从而避免了显式深度排序的需求。
实验设置与结果:算法实现和基于 GPU 的推断依赖于 gsplat,数据集为 MipNeRF360 数据集。将神经排序算法与 3DGS 的 SOTA 无排序算法(Sort Free)进行比较。由于这项工作不是开源的,我们会用训练框架仔细复现其结果。采用 SystemVerilog 实现,并通过台积电 28nm CMOS 库与 Design Compiler 合成。该设计采用 FP16 算术进行渲染,该算术通过 DesignWare IP [33] 实现。该设计完全采用流水线,频率为 1GHz。帧率比 NX 快 23.4~27.8 倍。
具体方法:
- 一是沿 X 轴和 Y 轴的常用中间项每轴计算一次。这些预先计算的项会广播给对应的 PE 在磁贴内。每个 PE 只需将广播的项组合起来,完成 α 计算,同时减少 MAC 开销。
- 二是提出通过算法与硬件协同设计的神经排序方法。深度排序的本质是计算衰减因子 T,用 Order-Independent Transparency 来做图像合成就可以,用 MLP 学这个用来代替排序的单调函数。
- 三是跨瓦片渲染轨迹优化。受 Morton 编码和希尔伯特曲线启发,提出了一种广义 π− 轨迹瓦片排程,通过改善瓦片间的数据局部性来最小化外部内存访问。
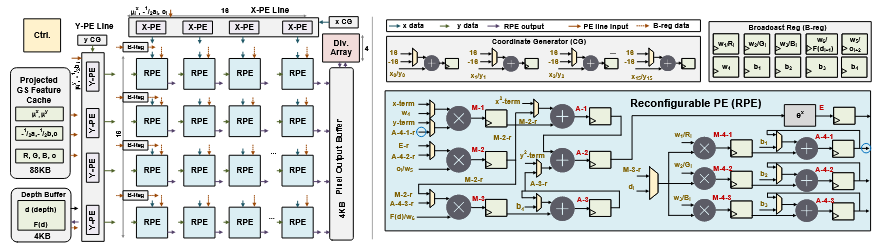
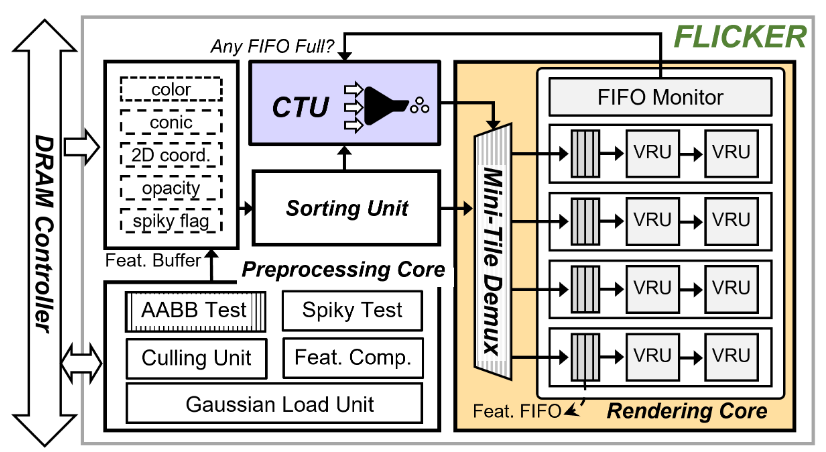
FLICKER: A Fine-Grained Contribution-Aware Accelerator for Real-Time 3D Gaussian Splatting(ASIC 仿真,3DGS 渲染加速)
动机与分析:较大的瓦片尺寸和过度包容的高斯测试导致像素处理大量不必要的高斯分布。努力使候选区域与真实贡献区域完全匹配必然会带来显著的计算复杂性。CAT 的开销较大,边缘设备部署面临挑战。
实验设置与结果:数据集为 Tanks & Temples、Mip-NeRF 360 和 Deep Blending。训练在 FP32 中进行,然后参数量化,用于 FLICKER 上的完整 FP16 渲染。使用了 Trimming the fat: Efficient compression of 3d gaussian splats through pruning 中的剪枝技术。Verilog 中开发,并使用台积电 28nm 工艺的 Synopsys 设计编译器合成,SRAM 通过内存编译器生成。对比 GSCore 和 NX。
具体方法:
- 一是采用贡献感知测试(CAT),通过直接评估每个高斯对像素群中领导者像素的贡献。如果贡献可以忽略,整个像素群可以跳过该高斯的处理。实现近像素级的非贡献高斯分布的精准跳跃。
- 二是引入了一种自适应引导-像素方案,基于高斯形状动态减少引导像素数量。提出了一种新型批处理技术,将引导像素组织成矩形组。通过在每个组内共享中间结果,开销几乎减半,同时不影响图像质量。
- 三是引入了两阶段的分层测试流程,有效过滤高斯算法,降低计算量和内存开销。此外,我们设计了一个混合精密 CAT 引擎,紧密集成于渲染流水线,以最小化面积开销并有效隐藏 CAT 延迟。