

FPGA 开发实践
俗称踩坑记录

基本概念
FPGA 全称 Field-Programmable Gate Array,即现场可编程逻辑阵列,是 PLD(Programmable Logic Device,可编程逻辑设备)的一种,通过编写硬件描述语言的代码就可以改变电路结构。第一块 FPGA 于 1985 年由 Xilinx 正式推出并商用,型号为 XC2064。FPGA 的设计初衷是减少芯片流片的成本,今天 FPGA 最多的应用仍然在于芯片的原型验证。此外,由于其硬件可编程、低延迟、低功耗的优势,FPGA 在航空航天、金融交易等领域也应用广泛。
FPGA 基于查找表技术,采用 SRAM 工艺,其中包含大量的查找表和触发器,适合复杂时序逻辑;另一种可编程逻辑设备是 CPLD,基于乘积项技术,采用 EEPROM、Flash 工艺,分解组合逻辑的功能很强,适合复杂组合逻辑;Xilinx 和 Altrea 对两者的概念区分并不特别明确,了解有这两大类可编程逻辑设备即可。FPGA 可以将部分在 CPU 上由软件执行的工作 offload 到硬件电路上进行。FPGA 的逻辑结构规整,存储及布线资源有限,时钟网络固定;ASIC 逻辑结构千变万化,芯片规模任意;CPU/DSP/MCU 逻辑结构规整,系统资源固化。
以 Xilinx 的 FPGA 为例,芯片以可配置逻辑块 CLB 为基本逻辑资源单元。每个 CLB 中包含若干 Slices,包含组合逻辑 LUT(本质上是一小块 RAM)、触发器 Flip-Flop 资源、多路选择器 Mux、进位链 Carry Chain、局部互联资源。除了 CLB 外,芯片中还有 IO Blocks、Memory、DSP Blocks、Global Clock Buffers、Boundary Scan Logic 等硬件资源。Slices 其实分为 SliceL 和 SliceM 两种,SliceL 即 Logic Slice,是纯逻辑 Slice,不能将其中的 LUT 配置为 RAM 使用,也不能作移位寄存器;SliceM 即 Memory-capable Slice,除了 SliceL 支持的功能外,其中的 LUT 可以配置为 Distributed RAM 和移位寄存器。存储资源分为 Distributed RAM 和 Block RAM,前者使用 CLB 资源,后者是器件上专用的存储器资源。高端的芯片除了这种中 RAM 之外,还会配备 Ultra RAM 资源。Ultra RAM 是大容量、省 LUT 的片上 RAM,数量少且延迟略高,适合作大缓存使用。DSP 单元是专用于做高速运算的硬件资源,对乘法和累加操作做了针对性的优化,支持二进制补码操作,运算功能丰富。为了保证运算速度,DSP 单元在芯片上通常会与 Block RAM 对称布置。时钟管理模块 CMT 是专用于产生/处理/分发时钟的硬件资源,用于将外部时钟转化为 FPGA 可用的高质量时钟,CMT 中包含 MMCM、PLL 和 Clock Buffers。具备了上述这些各个功能模块之外,芯片内还有互联资源,用于连接各个部分的可编程硬件网络,互联资源包含可编程布线网络和可编程交换开关。互联资源用于解决芯片内部连接,而在多颗 FPGA 硅片之间,有堆栈硅互联(SSI)技术来将多颗芯片在封装层面拼成一个超大 FPGA。
FPGA 的结构由可编程输入/输出单元、基本可编程逻辑单元、嵌入式块 RAM、布线资源和 IP 内核单元几部分组成。CLB(Configurable Logic Block,可配置逻辑块) 是 FPGA 的编程部分,也称逻辑单元,配置时可以只对芯片中的部分 CLB 编程,因此一块芯片可以同时执行不同的功能,或以流水线的形式在不同时刻对数据做不同的处理,故 FPGA 拥有很高的并行度。同样由于这一特性,FPGA 的设计目标之一,就是用最少的 CLB 实现需要的逻辑函数。
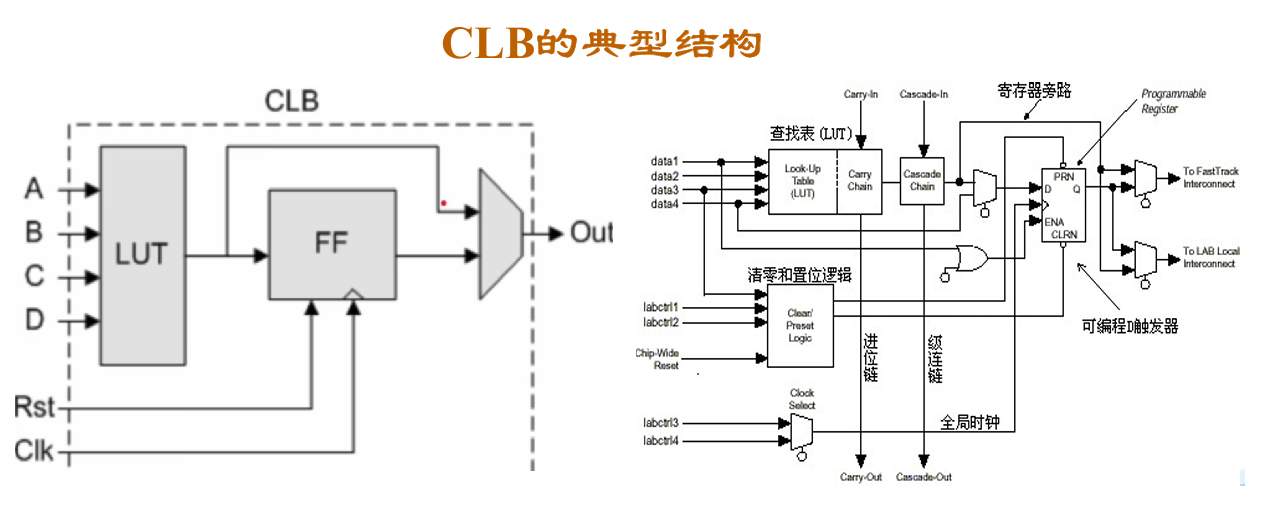
CLB 内部由查找表 LUT(Lookup Table)和触发器 FF(Flip-Flops)构成。LUT 是存储真值表的介质,也可用作分布式 RAM 作为快速高效的 on-chip memory。FPGA 芯片中的 LUT,实际上就是由 MUX 树和 SRAM 存储单元构成的,实际工作时,就是由输入信号控制 MUX 树,从 SRAM 配置位中选中一个值输出。以四输入的 LUT 为例,使用 15 个 MUX2 分为四层(8-4-2-1)来实现十六选一的结构,SRAM 中存储 16 个位对应应该存储的二进制值即可。今天的 FPGA,内部除了集成了 LUT 和 FF 外,还集成了 RAM(存储资源)、PLL(高速的时钟信号)、DSP(乘法操作、滤波器、数字信号处理)、SERDES(实现高速接口)、CPU(硬核处理器)、NPU(硬核 AI 推理)等硬核 IP 来满足特定应用场景的需求,这样的架构是解决实际问题和成本效率综合考量后的高度优化的结果。
IO Block 结构如下
内部互联结构如下
在 Vivado 综合生成的网表中,FDRE/FDCE 是带时钟使能的触发器,分别支持同步复位和同步清零;LDRE/LDCE 是门控锁存器,分别支持复位或清零;CARRY 是 FPGA 内部的快速进位链,用于加法、计数、比较等。除了这些,FPGA 常见的基本原语还包括 LUT(查找表,实现任意逻辑函数)、MUXF/MUXF7/MUXF8(用于多级逻辑选择)、IOBUF(输入输出缓冲器)、BRAM/URAM(片上存储单元)、DSP48(乘加运算单元)、BUFG/BUFR(全局或区域时钟缓冲) 等,它们构成了 FPGA 的核心逻辑、存储和算术单元。网表是电路连接清单,描述了由哪些逻辑单元(门电路、触发器、LUT、RAM、DSP 等),以及这些单元之间的连线关系(net)。FPGA 芯片就像一张巨大的电路板,除了基本的逻辑单元(LUT、触发器),大部分面积都被布线资源占据,比如可编程导线和开关,用于连接这些基本逻辑单元。
ZYNQ 架构
ZYNQ 的 PS 内集成了很多外设控制器模块,如 UART、SPI、I2C、CAN、USB、Ethernet 等,本质上是固化在 ZYNQ 芯片中的硬核外设 IP,是 PS 区域内的逻辑电路。它们存在于 SoC 的 PS 端,与 ARM CPU 核、DDR 控制器、时钟系统等都在同一个芯片中,通过 AXI 总线与 CPU 内核连接,CPU 可以读写寄存器来控制外设。
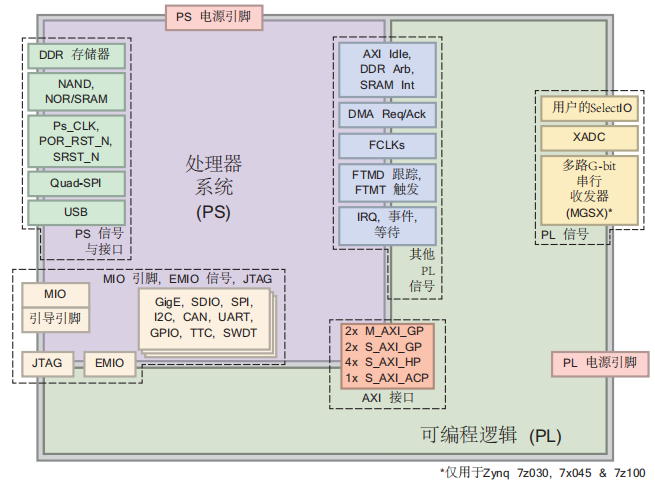
ZYNQ 架构分为 ZYNQ-7000 SoC、ZYNQ UltraScale+ MPSoC、ZYNQ UltraScale+ RFSoC 三类。ZYNQ-7000 SoC 的 PS 端为 Cortex A9 的 Arm 核心,为 ARMv7-A 架构,32 位;PL 端为 7 Series 的 FPGA。ZYNQ UltraScale+ MPSoC(MultiProcessor)的 PS 端为 Cortex A53 的 Arm 核心,为 ARM-v8-A 架构,64 位,另外还配备 Cortex-R5F 作为协处理器;PL 端为 UltraScale+的 FPGA。ZYNQ UltraScale+ MPSoC 再往下又可以细分为 CG、EG、EV 三类,面向的硬冲场景不同。ZYNQ UltraScale+ RFSoC(Radio Frequency)与 ZYNQ UltraScale+ MPSoC 的区别仅在于配备了高速 ADC 和 DAC 通道,用于射频领域。APU 是高性能的应用处理单元,是基于 ARM Cortex-A53(64bit)的四核处理器,通常运行 Linux、Petalinux、Yocto 等操作系统;RPU 是实时处理单元,是基于 ARM Cortex-R5F(32bit)的双核处理器,通常运行 FreeRTOS 和裸机程序。
UltraScale+ MPSoC 架构的 PS 端分由 FPD 和 LPD 两个主要电源域/性能域构成,FPD(Full Power Domain)为高性能运算域,包含 APU (Cortex-A53)、GPU、DDR 控制器、FPGA 高性能互联等;LPD(Low Power Domain)为低功耗控制域,包含 RPU (Cortex-R5F)、部分外设(I2C/SPI/UART)、低功耗互联等。
HP 口是 PL 和 PS 之间的 AXI 通道,目的是让 PL 的多个主设备(如 DMA、加速器、视频引擎、网络引擎等)能够高效访问 PS 侧的资源,比如 DDR、AD、DA 等。不同的 HP 口可以配置不同的数据和地址总线宽度以及其它一系列参数。(不同主设备的数据交互接口可能不一样)。多个 HP 可以用于流量隔离(把不同功能流量分到不同口,避免相互干扰)、QoS 策略、简化仲裁/设计(每个 PL 主控对接固定 HP),或在 PL 侧做 AXI interconnect 后把多个从机合并上 PS。
在 ZYNQ 架构中,PS 端的 DDR 控制器是所有主设备(ARM 核、DMA、加速器等)共享的“唯一通道”,从 PL 过来的访问(通过 HP 口)都是 AXI Master,会竞争 DDR 控制器的访问机会。当多个高带宽的模块(例如视频 DMA、网络 DMA、FFT 加速器)都通过同一个 HP 口访问 DDR 时,多个访问请求(AXI 事务)可能会在一个通道的仲裁器里排队,一个模块的突发传输可能长时间占用通道而其它模块被阻塞,实际 DDR 带宽利用率下降。多个 HP 口的作用在于存在多个独立的 AXI 通道(独立仲裁、独立 FIFO、独立 QoS 设置),各自的突发访问不会相互阻塞,且支持设置优先级。
ZYNQ 中,PS 端的 ARM 直接有硬件支持的 AXI 接口,而 PL 端需要使用逻辑实现相应的 AXI 协议,Xilinx 提供的现成 IP 如 AXI-DMA、AXI-GPIO、AXI-Datamover、AXI-Stream 都实现了这一接口。ZYNQ 中在 PS 和 PL 之间用硬件实现了九个 AXI 物理接口,包含 AXI-GP0~AXI-GP3、AXI-HP0~AXI-HP3、AXI-ACP 共九个。GP 为 32 位接口,理论带宽 600MB/s,两个 PL 主 PS 从,两个 PS 主 PL 从;HP 接口和 ACP 接口可配置为 32 或 64 位接口,理论带宽 1200MB/s,均为 PL 主 PS 从。一个接口的方向性是固定的,要么能发起事务,要么只能响应事务。每个物理接口支持的协议也是确定的,HP 和 ACP 接口支持 AXI4 协议,GP 接口支持 AXI4 和 AXI4-Lite 协议,而 AXI4-Stream 协议是纯 PL 内部的连接方式,需要用 AXI-DMA 或其它类似模块在 PL 内部实现 AXI4 到 AXI4-Stream 的转换。ACP 与 HP 接口的区别在于 ACP 可以保证与 CPU Cache 的一致性。
存储资源
FPGA 中常用的逻辑存储结构有 RAM、ROM 和 FIFO,三种结构 Xilinx 都提供了成熟的 IP,具体使用查阅文档即可。RAM 和 ROM 的 IP 有 Distributed Memory Generator 和 Block Memory Generator 两个,区别在于生成的 Core 所占用的 FPGA 资源不一样,从 Distributed Memory Generator 生成的 RAM/ROM Core 占用的资源是 LUT;而从 Block Memory Generator 生成的 RAM/ROM Core 占用的资源是 Block Memory。
Block Memory 是 FPGA 中片上块状存储资源的统称,是逻辑上的概念。Block Memory 主要由 BRAM 实现,少数型号的 FPGA 也有 URAM 和 HBM。BRAM 即 Block RAM,是 FPGA 中固化的硬件存储单元,固定容量为 18K bits(18432 bits),可以单独使用也可以两个相邻的 18k BRAM 组合成双口 36k BRAM。设计中调用的资源以 BRAM 为最小单位,向上取整。例如存储位宽为 16 位,数据深度为 512,总共占用 16*512 = 8192 bits = 1KBytes。数据宽度指一个数据占用的 bit 位数,数据深度指可以存放的数据个数。数据深度与地址线宽度有关,如数据深度为 512,则对应的地址线为 9 位,\(2^9=512\)。
RAM 和 ROM 中任意一个存储单元都可以在相同时间内被访问,硬件上由存储单元阵列 + 地址译码器 + 读写电路构成;ROM 由 RAM 配合要预先写入的 coe 文件实现。FIFO 是先进先出队列存储器,内部常用环形缓冲区的结构,由 RAM+读写指针实现。根据读写时钟,可以分为同步 FIFO 和异步 FIFO,同步 FIFO 的读写时钟相同,异步 FIFO 的读写时钟不同。
FIFO 不像 RAM 那样可以随意访问地址,而是写入只能写到队尾,读出只能从队首读取,硬件自动维护顺序,读写顺序固定。FIFO 的容量一般比较小,广泛用于数据的缓存、平衡异步时钟域之间的速度差等。读写对象为读写指针指向的存储单元,读写时操作指针位置,FIFO 内部逻辑负责防止读空或写满。FIFO 不能重复读出数据,也不能覆盖数据,没有地址的概念,由 full、empty 信号进行数据流控制;RAM 则反之。
FIFO Generator 是队列,Block Memory Generator 是随机访问内存。FIFO 用于不同时钟域之间的数据传输(CDC FIFO)、生产者和消费者速度不一致的数据缓冲、流式数据接口缓存;Block Memory 用于需要随机读写的数据存储、查找表、数据缓存等。FIFO 支持异步时钟,只需要告诉它读或写;Block Memory 一般只支持同步时钟,需要管理地址、何时读写。FIFO 更偏向流式、Block RAM 更偏向存储。FIFO Generator 中的实现资源分时钟域和存储资源两方面,时钟域有同步和异步之分,存储资源可选 BlockRAM、Distributed RAM、Shift Reg、Built-in FIFO。
时钟资源
锁相环(PLL)是 FPGA 中的时钟资源资源,通过 PLL 可以由晶振的频率引出许多不同的频率供各种外设使用。FPGA 使用专用的全局和局部 IO 以及时钟资源来管理各种时钟需求。FPGA 中的时钟不能直接裸信号使用,也不能走普通的布线逻辑,而需要经过专用的 buffer 电路驱动到全局或区域的时钟网络,这称为时钟 buffer。buffer 的作用主要是提高驱动能力和保证延迟均衡。
FPGA 内部有大量可编程的互连资源,逻辑单元之间的信号通过这些线段和开关连接,称为布线逻辑 (routing fabric)。普通布线逻辑指这些通用的互连通道,用来传数据/控制信号。它们延迟大、路径长短不一、受布线工具优化影响。时钟如果走普通布线逻辑 → 延迟和 skew 无法保证,会导致严重的同步问题。时钟倾斜 skew 是指同一个时钟信号到达不同触发器的时间差。如果 skew 太大,可能导致 setup/hold 时间被破坏 → 数据寄存错误。因此需要使用专用的时钟 buffer + 全局时钟网络(时钟布线网络),把 skew 控制在几十皮秒的范围内。
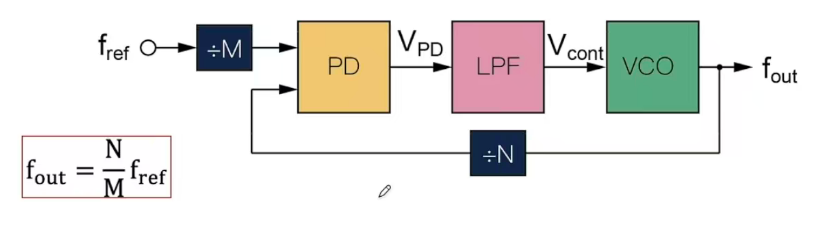
全局时钟资源指 FPGA 内部专门布设的低延迟、低偏斜的长距离布线网络,保证一个时钟信号可以同时驱动全芯片的逻辑,对应的 buffer 为 BUFG(Global Clock Buffer),用于驱动全局时钟,如系统主时钟、DDR 时钟等。
区域时钟资源限定在芯片的一部分,对应的 buffer 为 BUFH(Horizontal buffer)和 BUFR(Regional buffer),用于驱动局部时钟,减少功耗和浪费。FPGA 不允许随便用普通布线逻辑来传时钟,因为普通布线延迟大且不均衡,会导致时钟偏移,因此 Xilinx 给时钟单独做了专用的全局和局部 IO 与时钟资源。
CMT(Clock Management Tiles)分布在 FPGA 中的不同位置,提供了时钟合成、倾斜矫正和过滤抖动等功能,每个 CMT 包括一个 MMCM(Mixed Mode Clock Manager)和一个 PLL(Phase Lock Loop)。PLL 通过锁相机制使输出时钟和输入时钟相位一致,可实现分频和倍频,缺点是相位控制粒度有限。MMCM 比 PLL 功能更强,可实现分数分频/倍频和更精准的相移。CMT 的输入可以是 BUFR、IBUFG、BUFG、GT、BUFH 和本地布线,MMCM 或 PLL 输出的是原始时钟信号,要驱动 FPGA 内部逻辑,还需要接入专用时钟网络(BUFG/BUFH)。
时钟 buffer/网络说明:
- IBUFG (Input BUFG):把外部引脚的时钟(从 IO pin 来的时钟)引入到 FPGA 内部,送入全局/区域时钟网络。
- BUFG (Global BUFG):驱动全局时钟网络,确保整个芯片时钟到达几乎同时。
- BUFH (Horizontal Buffer):区域时钟 buffer,只在本 region(一般是一个 clock region,高度 50 CLB 左右)内部传播。
- BUFR (Regional BUFR):区域时钟 buffer,常用于 I/O 时钟(比如串行接口的本地时钟)。
- GT (Gigabit Transceiver):高速收发器自带的时钟输出,可作为 CMT 的时钟源。
- 本地布线 (Local routing):如果你把时钟当普通信号布线,会走 LUT/普通 interconnect,延迟和偏斜不可控。
在 Utility Buffer 这个 IP 中,可以选择 C Buf Types,这是一系列用于信号缓冲与时钟管理的硬件原语,其中 IBUFDS 为差分输入缓冲器,可将外部差分信号转换为内部单端信号,适用于高速数据或时钟的差分输入;OBUFDS 是差分输出缓冲器,能将内部单端信号转换为差分信号输出,常用于高速接口的信号发送;IOBUFDS 为三态差分 I/O 缓冲器,支持双向差分信号传输;IBUFDSGTE 专为高速收发器设计,用于高速 BANK 的参考时钟输入,具备增益和偏置调整能力;BUFG 是全局时钟缓冲器,可低延迟、低抖动地驱动全局时钟网络;BUFH 用于驱动单个时钟区域内的水平时钟线,实现区域内低偏斜传输;BUFGCE 是带使能端的全局时钟缓冲器,可灵活控制全局时钟输出;BUFHCE 则是带使能端的水平时钟缓冲器,用于单个时钟区域内时钟的使能管理。
IO 资源
MIO 和 EMIO 是 ZYNQ 中 PS 端的 IO 资源。Bank 是可编程逻辑芯片中对芯片内功能相近或关联的硬件资源进行物理分区和管理的单元,一般指 IO Bank。FPGA 芯片的管脚被划分为多个 IO Bank,每个 Bank 有一组外部供电的电源引脚,PS 的 IO 和 PS 的 MIO 都分布在若干个 Bank 中,每个 Bank 有独立的电平标准。在 FPGA 进行引脚分配时,必须先明确每个 IO Bank 的电源电平、支持的接口标准和资源限制(如是否带 PLL)。
MIO (Multiplexed IO)是 PS 端提供的物理 IO 管脚,可以连接诸如 UART、SPI、I2C、GPIO 等,通过 Vivado 软件设置可以将信号通过 MIO 导出。也可以将信号通过 EMIO 连接到 PL 端的 FPGA fabric,再从 PL 的 I/O Bank 的管脚引出。EMIO 是 PS 端的信号(注意不是来自 PS 封装的 MIO 引脚)通过 AXI 接口暴露到 PL 侧的一组逻辑 GPIO 接口,来源是 PS 内部信号,是直接逻辑线,不是直接的物理引脚。这样的逻辑线接入 IOBUF 之后,才成为 PL 端可以实际操作的物理引脚。
AXI GPIO 模块可以定义两个 GPIO 通道独立工作,且使用 Board Interface 可以不用手动添加相应的管脚约束。AXI GPIO 相较于 EMIO 的好处是,可以将多个 GPIO 当作总线一起控制;EMIO 则比较适合单个 GPIO 信号的控制。可以使用 AXI GPIO 的 IP 核,通过 AXI 总线控制 PL 端信号。AXI GPIO 是 xilinx 提供的 PL 侧的外设 IP 核,作用是让 PS 通过 AXI 总线访问 PL 端的 GPIO,因此使得 PS 端可以访问到 PL 端的信号。AXI GPIO 来源是 PL 内部逻辑,PS 通过 AXI 寄存器访问 PL GPIO,读写过程需要 AXI 总线。
运算资源
一些运算类的 IP,实现方式可以选用 Fabric 和 DSP48,前者是 FPGA 通用的逻辑资源,包括查找表、触发器、多路选择器等基础逻辑单元。特点是功能灵活,可实现任意数字逻辑,但运算性能(速度、功耗)相对较低,且复杂运算(如乘法、乘加)会消耗大量 LUT 资源。适用于简单逻辑运算(如小规模加法、逻辑门组合)、控制类电路,或在 DSP48 资源不足时的 “兜底” 实现。后者是专用的硬核数字信号处理器,是 FPGA 内置的专用数字信号处理模块(如 Xilinx 的 DSP48E 系列),集成了乘法器、累加器、ALU 等专用电路。特点是针对高速算术运算(乘法、乘加、滤波、FFT 等)做了硬件优化,具有高频率、低功耗、资源高效的特点(一个 DSP48 可替代数百个 LUT 实现乘法),适用于高性能数字信号处理场景,如 FIR/IIR 滤波器、复数乘法、矩阵运算、神经网络加速等,需要密集算术运算的领域。DSP Slice 是 DSP48 系列硬核的最小功能模块,是构成复杂 DSP 单元的基础,集成了高速乘法器、加法器、累加器、多路选择器和控制逻辑等最核心的算术运算组件。
原语
Verilog 可用 primitive 创建自定义原语(UDP),既可以是组合逻辑,也可以是时序逻辑。原语是 FPGA 厂商提供的语法糖,对应有专用的底层电路模块,不是标准 Verilog 语法,是介于硬件描述语言和实际硬件电路之间的硬件级命令。
xdc 文件和约束
Vivado 支持的 xdc constrait 包括标准的 synopsys design constrait(SDC)和 Xilinx 专有的约束。通用 SDC 约束包括 create clock、create generated clock、set input delay、set output delay、set multicycle path、set max delay、set false path 等,xilinx 专有约束包括 set property 等。xdc 约束支持 tcl 语言;约束文件顺序解析,相同的约束,后读取的约束会覆盖前面的约束。
时序约束的基本步骤为:创建主时钟约束、确定芯片内部时序约束、确定芯片与外部连接的约束、特殊路径的约束。
时钟约束必须最早创建,端口进来时钟以及 GT 输出 RXCLK/TXCLK 都需要使用 create clock 自主创建。如果是差分输入时钟,使用 create_clock 创建约束 P 端即可。
Vivado 工具会自动推导 MMCM/PLL/BUFR 输出作为衍生时钟。create clock 定义的主时钟的起点即时序的“零起点”,在这之前的上游路径延时都被工具自动忽略。
同步时钟的时序需要 STA 分析,异步时钟域的信号切换需要特殊处理,可以通过 set false path 消除异步时钟域的时序检查。
关于复位,有全局复位和局部复位两种。局部的模块化复位寄存器容易被综合器优化,可以用 KEEP 属性强制保留,保证复位逻辑不被优化掉。
1
2
3
4
5
6
7
8
9
(* keep="true" *) reg my_modular_reset1;
(* keep="true" *) reg my_modular_reset2;
(* keep="true" *) reg my_modular_reset3;
always @(posedge clkA) begin
my_modular_reset1 <= synchronized_reset;
my_modular_reset2 <= synchronized_reset;
my_modular_reset3 <= synchronized_reset;
end
FPGA/ASIC 设计中的 IO 时序约束,核心是告诉综合 / 布局布线工具:外部芯片和 FPGA 之间的信号延迟有多少,工具要按这个来算建立 / 保持时间。
建立时间(Setup):数据要在时钟沿到来前稳定多久,用 max 约束(最坏情况)。 保持时间(Hold):数据要在时钟沿到来后稳定多久,用 min 约束(最好情况)。
输入约束举例
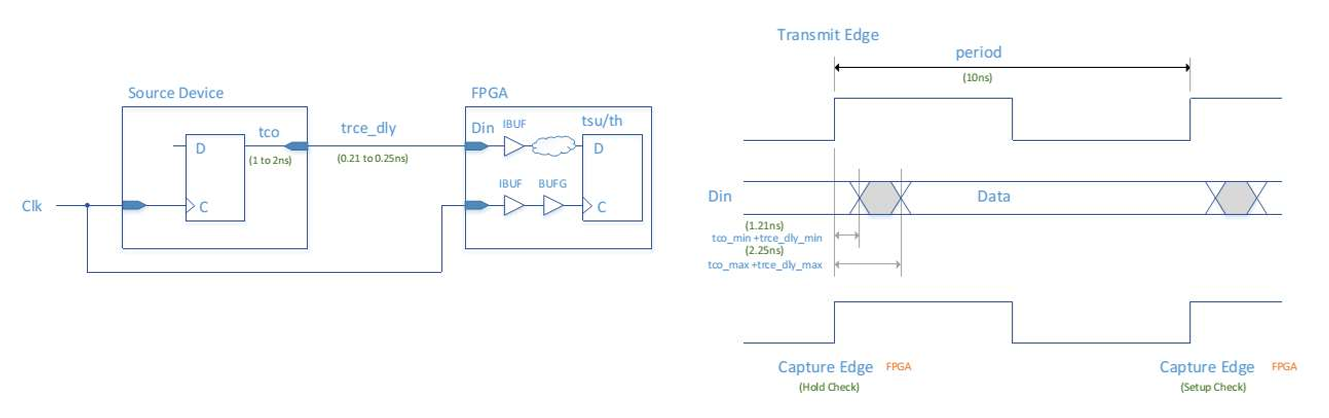
1
2
3
4
5
# 保持时间(min):外部到FPGA的最小延迟
set_input_delay -clock [get_clocks {Clk}] -min -add_delay 1.21 [get_ports {Din[*]}]
# 建立时间(max):外部到FPGA的最大延迟
set_input_delay -clock [get_clocks {Clk}] -max -add_delay 2.25 [get_ports {Din[*]}]
输出约束举例:
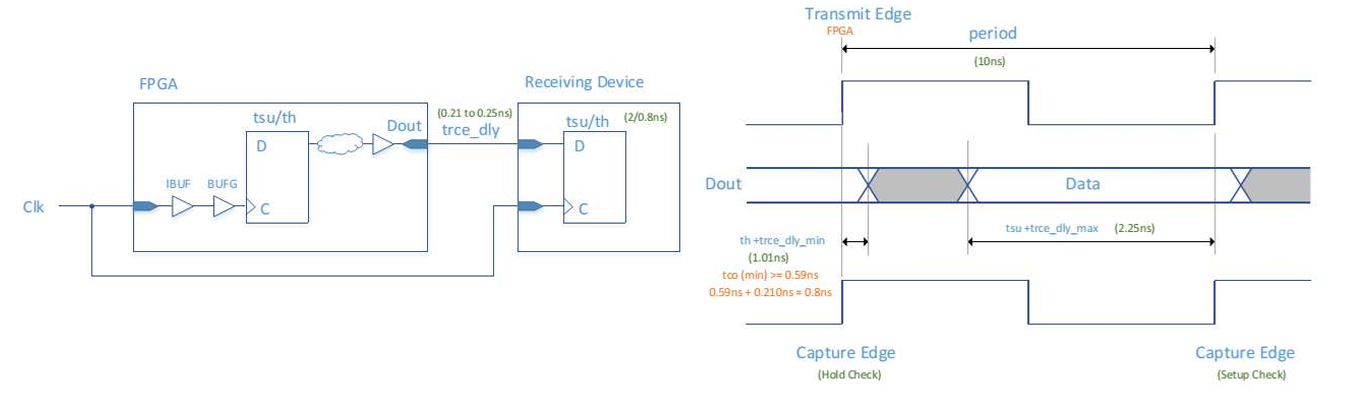
1
2
3
4
5
# 保持时间(min):FPGA到外部的最小延迟(这里是负的,代表提前)
set_output_delay -clock [get_clocks {Clk}] -min -add_delay -0.59 [get_ports {Dout[*]}]
# 建立时间(max):FPGA到外部的最大延迟
set_output_delay -clock [get_clocks {Clk}] -max -add_delay 2.25 [get_ports {Dout[*]}]
set_input_delay:约束外部到 FPGA 的信号延迟,用于 FPGA 内部的建立 / 保持检查。 set_output_delay:约束 FPGA 到外部的信号延迟,用于外部器件的建立 / 保持检查。 -min 给 hold,-max 给 setup,是 IO 时序约束的固定套路。
IO 物理约束:核心是给 FPGA 的 IO 口指定管脚号、电平标准、阻抗匹配,让工具知道 “信号接哪个脚、用什么电平、怎么匹配阻抗”。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 1. 差分时钟 sys_clk_p/n,指定IO标准为DIFF_SSTL12
set_property IOSTANDARD DIFF_SSTL12 [get_ports "sys_clk_p"]
set_property IOSTANDARD DIFF_SSTL12 [get_ports "sys_clk_n"]
# 2. 绑定差分时钟的物理管脚
set_property PACKAGE_PIN AT49 [get_ports "sys_clk_p"]
set_property PACKAGE_PIN AU49 [get_ports "sys_clk_n"]
# 3. 绑定片选信号 mem_cs_n[1] 的物理管脚
set_property PACKAGE_PIN AU51 [get_ports "mem_cs_n[1]"]
# 4. 片选信号用SSTL12_DCI电平标准(带片上终端)
set_property IOSTANDARD SSTL12_DCI [get_ports "mem_cs_n[1]"]
# 5. 片选信号输出阻抗40Ω,做阻抗匹配
set_property OUTPUT_IMPEDANCE RDRV_40_40 [get_ports "mem_cs_n[1]"]
利用最大 / 最小延时约束组合路径延时
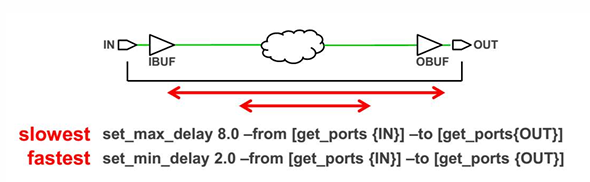
利用虚拟时钟:假设输入或者输出端口接在某一时序器件上,定义该时序器件时钟为虚拟时钟;利用 set_input_delay/set_output_delay 将相应端口归到虚拟时钟时序上
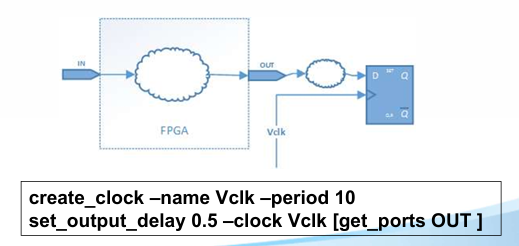
xdc 文件
xdc 文件用于存放约束,约束分物理约束和时序约束两类。物理约束包括 IO 接口约束、布局约束、布线约束、配置约束;时序约束涉及 FPGA 内部各种逻辑或走线的延时。
在最佳实践中,建议以约束集(一个 constraint 目录)为单位管理 xdc 文件,其中分 pins.xdc 和 timing.xdc,前者用于配置引脚 IO 等物理约束,后者专门用于配置时序约束。除了直接编写 xdc 文件,也可以通过 GUI(Constraint Wizard 和 Edit Timing Contraint)的方式设置约束,后由 EDA 将 GUI 设置的结果自动写入 xdc 文件。实际使用中,往往用 GUI 设置时序约束,而物理约束一般直接修改 xdc 文件。
xdc 文件中按照约束的先后顺序依次执行,针对同一个管脚或同一个时钟时钟的不同约束,只有最后一条约束生效。除了先后顺序之外,约束还有优先级。对于同样的约束,定义越精细则优先级越高。
物理约束
物理约束相对简单,普通 IO 口只需约束引脚号和电压,注意大小写,端口名称是数组的话用{ }括起来,端口名称必须和源代码中的名字一致,且不能和关键字一样。
- 管脚约束:
set_property PACKAGE_PIN 引脚编号 [get_ports 端口名称] - 电平信号约束:
set_property IOSTANDARD 电平标准 [get_ports 端口名称]。
1
2
3
4
5
6
7
8
9
10
11
12
13
set_property PACKAGE_PIN J16 [get_ports {led[3]}]
set_property PACKAGE_PIN K16 [get_ports {led[2]}]
set_property PACKAGE_PIN M15 [get_ports {led[1]}]
set_property PACKAGE_PIN M14 [get_ports {led[0]}]
set_property PACKAGE_PIN N15 [get_ports rstn]
set_property PACKAGE_PIN U18 [get_ports clk]
set_property IOSTANDARD LVCMOS33 [get_ports {led[3]}]
set_property IOSTANDARD LVCMOS33 [get_ports {led[2]}]
set_property IOSTANDARD LVCMOS33 [get_ports {led[1]}]
set_property IOSTANDARD LVCMOS33 [get_ports {led[0]}]
set_property IOSTANDARD LVCMOS33 [get_ports rstn]
set_property IOSTANDARD LVCMOS33 [get_ports clk]
BOARD_PIN 是 Vivado 板级接口约束(Board Interface Constraint)系统的一部分属性。它不是约束 FPGA 封装引脚的“物理约束”(比如 PACKAGE_PIN), 而是 Vivado 板卡定义(Board Definition)机制中自动生成的“逻辑绑定信息”。Vivado 的 Board 文件系统允许:选择某块开发板(如 ZCU102、ZedBoard、VC707);然后直接把 IP 的接口(如 AXI GPIO、UART、I2C)连接到 板卡接口(Board Interface);Vivado 自动知道这些接口应该连到哪个物理引脚、使用什么 IOSTANDARD。这种自动化的“板卡接口”约束就叫 Board Interface Constraint,它在内部通过命令实现:
1
set_property BOARD_PIN "some_pin_name" [get_ports <port_name>]
时序分析和时序约束
静态时序分析 STA:采用穷尽的分析方法检查信号的建立和保持时间是否满足时序要求,通过对最大路径延时和最小路径延时的分析,找出违背时序约束的错误并报告。
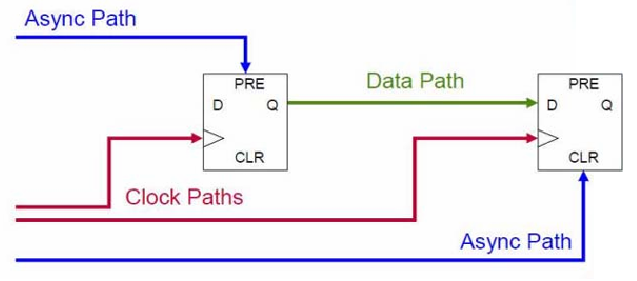
数字电路时序分析中,将路径分为时钟路径、数据路径和异步路径三种。时钟路径是从时钟源到触发器时钟端的路径,决定了时钟到达各触发器的偏斜(skew)和延时(delay);数据路径是从一个触发器的 Q 端,到下一个触发器 D 端的路径,包含了组合逻辑+连线,决定了数据从源触发器到目标触发器的传输延时,是同步时序分析中建立和保持时间检查的核心;异步路径是直接连接到触发器异步控制端的路径,不受时钟控制,容易产生亚稳态、毛刺、复位/置位冲突,需要专门的异步时序分析。同步时序分析需要考虑时钟路径和数据路径,核心是检查建立时间和保持时间关系,确保数据在时钟沿到来前稳定且到来后不提前变;异步时序分析需要考虑时钟路径和异步路径,核心是检察异步控制信号与时钟的时序关系,避免异步信号在时钟沿附近变化导致亚稳态、异步信号宽度不够导致触发器来不及响应、多个异步信号冲突等异常情况。
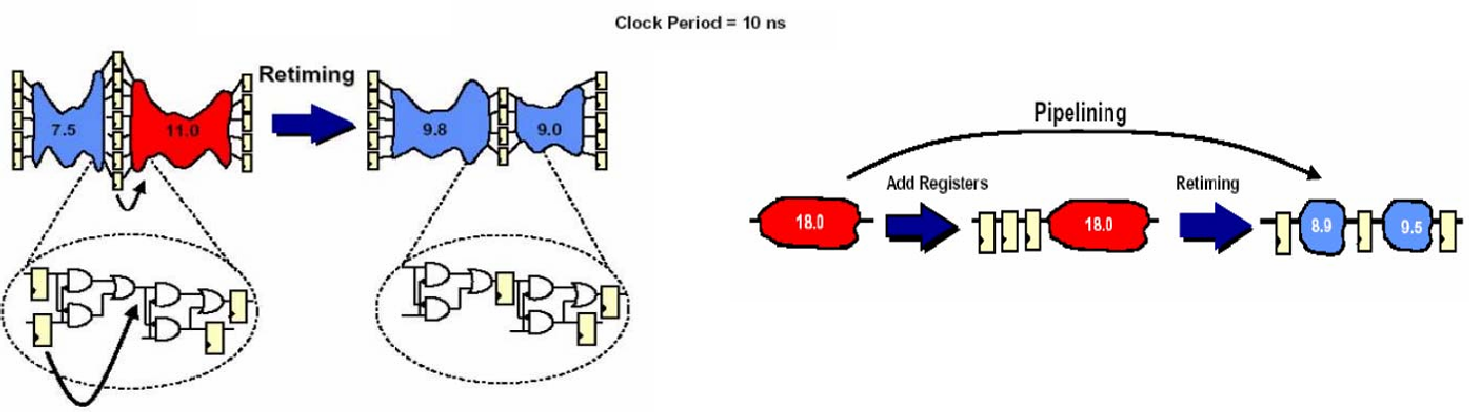
常见的时序优化方法有重定时 retiming 和流水线 pipeling 两种,目标都是锁定关键路径延时,提高电路工作频率。重定时指在不改变电路逻辑的前提下,移动寄存器的位置,将长路径延时分摊到相邻路径,让各段延时更均衡。流水线指在长组合逻辑中插入新的寄存器,将长路径拆分成多条短路径,每条短路径延时更小,提高整体频率。
另外还有两点注意:
(1)一般来讲,IOB 中只有少量的逻辑资源,它会有寄存器,但它几乎没有任何组合逻辑资源,因此需被约束到管脚上的寄存器不能有任何组合逻辑;如果输入一进来就是一驱多,输出是经过组合逻辑后直接输出到管脚上的寄存器,则会出现布线不通的问题;但事实上,如果不是资源或功耗要求很高,我们一般都会采用同步设计方式,而对外接口部分在同步设计中一般被视作异步接口,设计中会对接口做同步处理。
(2)被约束的寄存器除了受组合逻辑影响外,还会受到时钟驱动区域的影响;在设计中为了保证时钟的 Skew 等性能,一般会将时钟加入全局时钟网络或区域时钟网络,如果是全局时钟网络自不必管,它可驱动整个芯片,但如果是区域时钟约束就要注意了。区域时钟顾名思义,即每个时钟分管芯片的部分区域,每个 PLL 都对应几个专用外部输入管脚,如果使用了别的 PLL 则无法保证时序最优。
SDC 中的 clock 是指设计中施加于一个点上的已定义的、重复的信号特征: (1)内部的(internal):在设计中作为时钟指定到特定节点;(2)虚拟的(virtual):没有实际的源或没有直接连接到设计,比如驱动 FPGA 或被 FPGA 驱动的外部器件的时钟。即,如果一个时钟不是设计中的时钟,而仅作为外部器件的时钟源,且外部器件和该设计有输入 / 输出管脚的连接,那么就认为此时钟是虚拟时钟。 使用 create_clock 命令创建一个虚拟时钟时对源选项没有指定。虚拟时钟用于作为输出最大 / 最小延时约束的时钟源。即使用虚拟时钟来约束 set_input_delay 和 set_output delay,即在创建虚拟时钟之后可以执行 FPGA 器件和外部器件的寄存器之间的,register-to-register 的分析报告。
在不做任何时序约束的情况下,无论是 Xilinx 还是 Altrea 的 EDA,都会默认所有时钟均为同步时钟,会对所有路径进行分析,因此存在异步时钟的情况下,需要对其进行时钟约束。
多周期路径是一种时序例外的情况。在同步逻辑设计中,通常都是按照单周期关系考虑数据路径的。但是往往存在这样的情况一些数据不需要在下一个时钟周期就稳定下来,可能在数据发送后几个时钟周期之后才起作用;一些数据经过的路径太复杂,延时太大,不可能在下一个时钟周期稳定下来,必须要在数据发送后数个时钟周期之后才能被采用。针对这两种情况,设计者的设计意图都是:数据的有效期在以 launch edge 为起始到数个时钟周之后的 latch edge。这一设计意图不能被时序分析工具猜度出来,必须由设计者在时序约束中指定;否则,时序约束工具会按照单周期路径检查的方式执行,往往会误报出时序违规。不设置多周期路径约束的后果有两种:一是按照单周期路径检查的结果,虚报时序违规;二是导致布局布线工具按照单周期路径的方式执行,虽然满足了时序规范,但是过分优化了本应该多个周期完成的操作,造成过约束。过约束会侵占本应该让位于其他逻辑的布局布线资源,有可能造成其他关键路径的时序违规或时序余量变小。
在多周期路径的建立时间(Setup Time)检查中,Timequest 会按照用户指定的周期数延长 Data Required Time, 放松对相应数据路径的时序约束,从而得到正确的时序余量计算结果;在保持时间(Hold Time)检查中,Timequest 也会相应地延长 Data Required Time, 不再按照单周期路径的分析方式执行(不再采用 launch edgei 最近的时钟沿,而是采用 latch edge 最近的时钟沿),这就需要用户指定保持时间对应的多周期个数。 Timequest 缺省的 Hold Time 检查公式是需要用户修改的一一针对 Setup Time 多周期路径的设置也会影响到 Hold Time 的检查。究其原因,多周期路径是为了解决信号传播太慢的问题,慢到一个周期都不够,所以要把 Setup Time 的检查往后推几个周期一扩大 Setup Time 检查的时间窗口。而 Hold Time 检查信号是否传播的太快,如果把检查时刻往后推,就缩小了 Hold Time 检查的时间窗口。
时序约束的目的,为了满足建立时间和保持时间的要求,由于 RTL 代码中是不包含时序信息的,因此需要时序约束来告诉 EDA 软件这些时序上的前提条件。时钟过约束或欠约束都可能导致时序难以收敛,因此需要设定合理的时序约束。
FPGA 中的时序路径有四种:一是从输入端口到 FPGA 内部第一级触发器的路径,用 set_input_delay 指令约束;二是 FPGA 内部触发器之间的路径,用 create_clock 指令约束;三是 FPGA 内部末级触发器到输出端口的路径,用 set_output_delay 约束;四是 FPGA 输入端口到输出端口的路径,用 set_max_delay 约束。四种路径中,一般最关心的是第二种,即 FPGA 内部的时序逻辑。
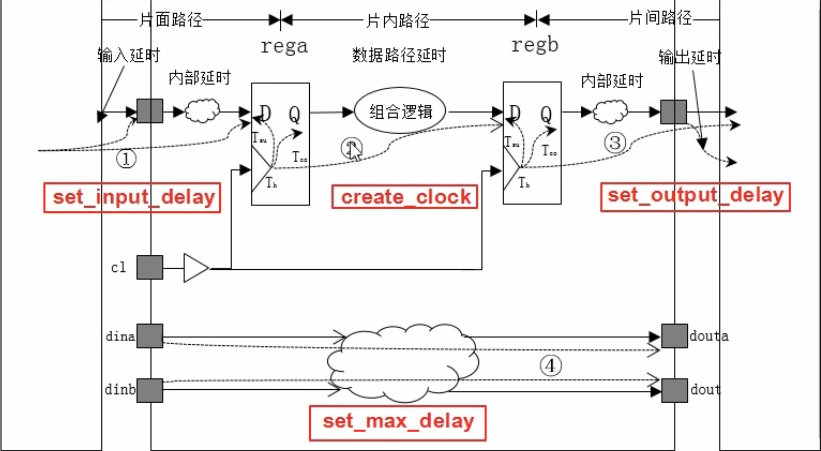
典型的时序模型如下。完整的时序路径包括源时钟路径、数据路径和目的时钟路径,也可以表示为触发器+组合逻辑+触发器的模型。
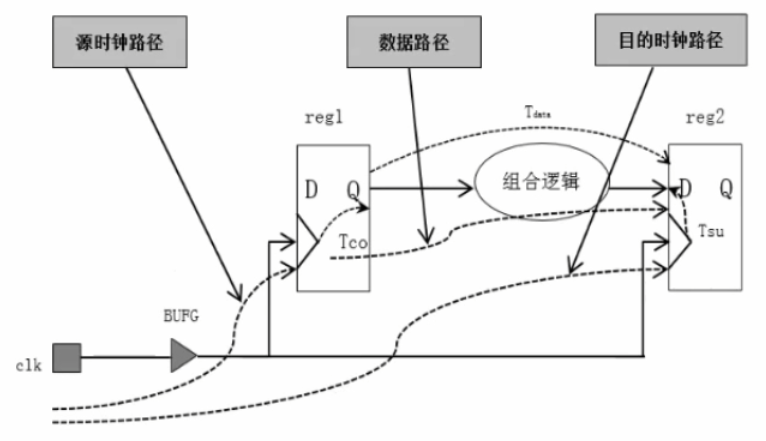
最常用的时序约束是时钟约束,时钟约束又有许多分类。
- 源时钟/主时钟约束用来设置主时钟是多少兆 Hz,用 create clock 指令设置。主时钟通常有两种情况,一种是由外部时钟沿提供,通过时钟管脚进入 FPGA,该时钟引脚绑定的时钟为主时钟;另一种是高速收发器 GT 的时钟 RXOUTTCLK 或 TXOUTTCLK。
- 衍生时钟约束包括自定义时钟和自动生成的时钟,自定义时钟如自己写的分频器、倍频器,需要设置约束;自动生成的时钟如 MMCM、PLL、BUFR、debug_hub 生成的时钟,不需要自己约束。衍生时钟用 create generated clock 指令约束。
- 异步时钟约束和互斥时钟约束用 set clock group 指令设置,其中互斥时钟又分物理互斥和逻辑互斥,物理互斥指引脚不同的时钟,逻辑互斥则是用 mux 组织的时钟。物理互斥可用于验证同一个时钟端口在不同时钟频率下是否获得时序收敛。逻辑互斥是在使用 NUFGMUX 时,会有两个输入时钟,但只会有一个时钟被使用。
设计约束最基本的是核心频率约束,然后是时序例外约束,包括 FalsePath、MulticyclePath、MaxDelay、MinDelay。以上是芯片内部的时序约束。再之后是 IO 约束,IO 约束包括引脚分配位置、空闲引脚驱动方式、外部走线延时(nputDelay、 OutputDelay)、上下拉电阻、驱动电流强度等。加入 I/O 约束后的时序约束,才是完整的时序约束。
FPGA 是整个 PCB 系统时序收敛的一部分,在设计 PCB 时理论上应该阅读并分析其 I/O 时序图。FPGA 的 I/O Timing 可能在设计期间发生变化,可能存在修改设计重新编译后,FPGA 对外部器件的操作出现不稳定的问题,有可能是 IO 时序导致的问题。
输入延迟约束和输出延迟约束分别用 set_input_delay 和 set_output_delay 指令实现,其时钟源可以是时钟输入管脚或虚拟时钟。另外,输入延迟约束和输出延迟约束并不起到延迟的作用,而是对周期的约束。比如输入延迟约束用于用于告诉 vivado 输入数据和输入时钟之间的延迟关系;而想要调节输入信号延迟,则需要使用 IDELAY 硬件资源。最大最小延迟约束用 set_max_delay 和 set_min_delay 实现,最大最小延迟的主要应用场景有二:一是输入管脚的信号经过组合逻辑之后直接输出到管脚;二是异步电路之间的最大最小延迟。下图以输入延迟为例进行说明。
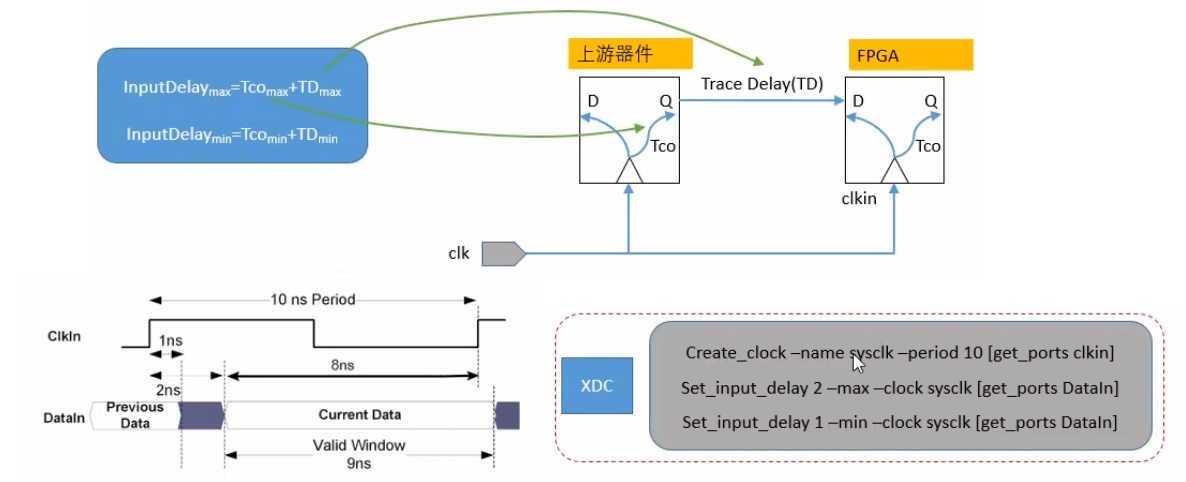
虚拟时钟没有与之绑定的物理管脚,通常用于设定输入和输出的延迟约束,主要用于以下三个场景:一是外部 IO 的参考时钟并不是设计中的时钟;二是 FPGA/IO 路径参考时钟来源于内部衍生时钟,但与主时钟的频率关系并不是整数倍;三是针对 IO 指定不同的 jitter 和 latency。总结来说,之所以要创建虚拟时钟,对于输入来说,是因为输入到 FPGA 数据的捕获时钟是 FPGA 内部产生的,与主时钟频率不同,或者 PCB 上有 Clock Buffer 导致时钟延迟不同。对于输出来说,下游器件只接收到 FPGA 发送过去的数据,并没有随路时钟,要用自己内部的时钟去捕获数据。另外,虚拟时钟必须在约束 IO 之前被定义。
两种时序例外,一种是多周期路径。保持时间的检查,默认是在建立时间的前一个周期进行的。但若出现路径过长或逻辑延长过长需要经过多个时钟周期才能到达目标寄存器;又或者在数据发起的几个周期之后后续逻辑才能使用,此时如果按照单周期路径进行时序检查,就会报时序违规,因此需要使用多周期约束的指令来设置。另一种是伪路径,伪路径指路径存在但该路径的功能不会发生或无需时序约束。创建伪路径可以减少工具运行优化的时间,增强实现结果。伪路径一般用于跨时钟域、一上电就被写入数据的寄存器、异步复位或测试逻辑、异步双端口 RAM,即主要用在异步时钟的处理上。
AXI 协议
AXI 全称 Advanced eXtensible Interface,是 ARM 提出的 AMBA 协议标准的一部分,Xilinx 从 6 系列的 FPGA 开始引入这一协议。AXI 属于片上总线协议,描述主设备和从设备之间的数据传输方式,通过 VALID 和 READY 信号的握手机制建立主从设备之间的连接(VALID 来自主设备,READY 来自从设备)。任意通道上完成一次数据交互都称为一个传输 transfer,当 VALID 和 READY 信号均为高电平时到来时钟上升沿,就会发生传输。一个通道内 VALID 和 READY 信号的建立顺序无关紧要。VALID/READY 机制使得数据的发送和接受方都有能力控制传输速率。
ZYNQ 中使用的主要是 AXI4 协议族,包括 AXI4、AXI4-Lite、AXI4-Stream 三种协议。(注:burst 指一个地址中可发生多次数据传输的传输事务,burst 操作只需要提供首地址)
AXI4:存储器映射总线,采用内存映射控制,支持 burst 传输,高带宽,适合访问块式内存,常用于 DDR 等大量数据读写。
- AXI4-Lite:存储器映射总线,采用内存映射控制,仅支持单数据传输,常用于访问和配置状态寄存器。
- AXI4-Stream:连续流式接口,没有地址的概念,支持 burst 传输,适合访问流式内存,常用于视频流、FFT 数据等流式数据通路。
块式内存和流式内存是两种数据传输模型,块式数据的数据按照地址排列,一次访问一大块数据,典型的访问方式是内存地址+长度,如 DDR / PS 内存存储、CPU 内存搬运等。流式数据的数据不需要地址,一次访问一个元素,一个接一个,典型的方式是按时间按拍数,如 FPGA 内部视频像素流、FFT 数据流等流水线模块处理。AXI 或 AXI Lite 的块式访问和 AXI Stream 的流式访问是 ZYNQ 架构中最常见的桥接,桥接(Bridge)是指将两种不同协议/总线类型互相转换,让它们可以通信。最典型的场景是 PS 端的 DDR 为 AXI 的 Memory Mapped,而算法模块为 Stream。
AXI4 和 AXI4-Lite 中,将一次传输事务分为五个独立通道,分别为读地址 AR、读数据 R、写地址 AW、写数据 W 和写响应 B。每个通道各有一组独立的信号线(各信号线的具体含义这里不一一列出),有一个独立的 AXI 握手协议,因此 AXI 协议支持同时进行读写操作。AXI4-Stream 由于没有地址的概念,因此也仅定义了一条通道,完成握手和数据传输。
.png )
虽然 AXI 协议的五个通道是独立并行的,但并非完全没有逻辑时序约束。AXI 协议要求读通道中读数据位于读地址之后,具体来说是 AR 通道地址有效之后才会返回 R 通道 VALID;类似地,要求写响应位于写通道中地最后一次写入传输之后,具体来说是 B 通道 VALID 只能在最后一个 W 通道地数据拍结束之后才出现。不过,这样的约束是通过 READY 和 VALID 信号实现的,设计时无需考虑地址和数据的先后顺序,较为灵活,只要保证符合 READY 和 VALID 信号的握手机制即可。
AXI 协议的一些特性如下:
- AXI 允许读数据返回之前,又发起一次新的读请求,类似于流水线的概念。延迟较大的情况下,可以做到不影响带宽,将延迟掩盖起来。
- 支持非对齐传输:传输的地址和数据宽度一致时称为对齐传输,地址是字节地址的情况下,假设总线数据宽度为 32bit(4 字节)每次访问的起始地址是 4 的倍数,那么就是对齐的。而 AXI 协议通过 WSTRB 的掩码机制,每一位对应一个字节,可以控制只写入部分字节,因此写传输可以起始于任意地址,不必是 4 字节边界。
- ARSIZE 和 ARBURST 分别规定了单次传输的数据宽度(如 4 字节、8 字节等)和突发类型(FIXED 地址固定、INCR 地址按固定值递增、WRAP 地址递增但循环)。写通道同样有这样的信号。
- 支持不同 ID 之间的乱序传输,同一个 ID 内则是保序的。AXI4 中已经取消了 WID 信号的使用,不再支持写乱序。
- AXI 协议是一个点对点的主从接口,当多个外设需要相互交互数据时,需要加入 AXI Interconnect 模块(Xilinx 提供了相应的 IP),本质上是一个实现交换机制的互联矩阵
Xilinx 产品线
FPGA 和 SoC 是 Xilinx 的两大主要产品系列。
FPGA 即纯 FPGA 芯片,按照工艺节点分为 UltraScale+(16nm)、UltraScale(20nm)、7 Series(28nm)三大类,类似于 CPU 中第几代的概念。在每个类别中,又分为 Spartan、Artex、Kintex、Virtex 四个子系列,面向不同的应用场景和市场定位,性能依次提升。

除了最新的 Versal ACAP(Adaptive Compute Acceleration Platform,自适应计算加速平台)之外,Xilinx 将 SoC 系列命名为 ZYNQ 计算架构,是 FPGA + Arm 的多处理器系统,集成了 FPGA 的可编程逻辑(PL)与 ARM 处理器核心(PS),两者之间通过 AXI(Advanced eXtensible Interface)总线实现低延迟数据传输。PS 具有固定的架构,包含了处理器和系统的存储器,适合控制或具有串行执行特性的部分以及浮点计算等;而 PL 是完全灵活的,适合并行流处理。
开发流程
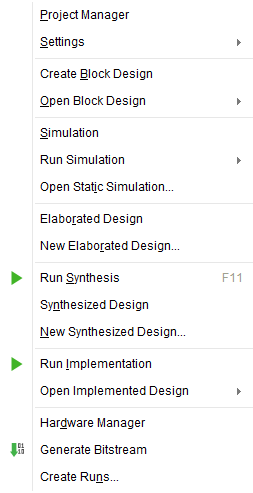
FPGA 开发流程大致可以分为以下步骤:
- 设计(Design):用 HDL 对硬件电路进行建模描述,需要定义电路功能实现、设计约束和测试用例。对于许多常用的功能,有现成的 IP 核作为轮子可以直接使用。测试用例是针对功能仿真的,由.sim 文件管理;设计约束主要由.xdc 文件管理。
- 功能仿真(Simulation):又称前仿真,指在计算机的仿真器上运行 Verilog 代码,在不考虑硬件电路实现和绝大部分约束的情况下,仅验证逻辑功能是否正确。功能仿真是可选步骤。
- 分析和综合(Systhesis):检查 HDL 代码是否符合综合规则,并由 EDA 在厂家提供的标准单元库和设计阶段中的约束下,编译出由 HDL 描述的逻辑网表并进行逻辑优化。逻辑网表是指一个标准的逻辑门或查找表的集合,是一个逻辑层面的结构,可以包括时序触发器、寄存器等时序元素,是逻辑门级别的描述。另外,注意不是所有的 HDL 语句都可以综合出相应的逻辑电路。硬核 IP 已经在芯片流片(制造)时,用晶体管电路实现并固化在硅片中了,不需要综合。对于 FPGA,综合将 RTL 代码映射成 LUT、FF、RAM Blocks 等芯片中固定的硬件资源;而对于 ASIC,综合将 RTL 代码映射成为目标工艺库的网表电路。
- 布局布线(Implementation):分配引脚并确定内部电路的连接关系,进行 layout 和 IO planning,根据设计阶段的约束文件和综合出的逻辑网表,利用厂家提供的标准元件库对门级电路进行布局,在考虑各种约束和优化的情况下,将设计中的门级网表映射到 FPGA 的物理布局上并进行物理优化。完成这一步后就将 HDL 描述的模型电路转化为标准元件库组成的数字电路,且此时的电路已经包含了时延信息。
- 时序分析(Analysis):指时序仿真,又称后仿真,用于检查信号延迟是否满足要求。时序分析有静态时序分析(STA)和动态时序分析(DTA),静态时序分析是通过计算每条路径的延迟来检查是否满足设计的时序约束;动态时序分析是模拟设计的运行,动态检查信号的传播延迟,用于验证时序边界。时序分析是可选步骤。
- 生成比特流和板级调试(Bitstream):生成烧录到板子中的二进制文件.bit,并进行实际硬件的调试。生成比特流之前需要完成设计、综合和布局布线。比特流文件是一种专门为 FPGA 硬件配置而设计的格式,文件内容是经过优化的、以二进制形式存储的配置信息,包含了逻辑元件的映射、时序约束、硬件资源配置等所有信息,能够直接在 FPGA 上加载和执行。
设计约束包括:
- 引脚约束:又称 IO 约束、引脚绑定,将逻辑信号与物理引脚进行对应
- 时序约束:保证各信号按预期的时序顺序传输,在规定时间内到达正确的位置,主要类型包括时钟约束、输入输出延迟约束、时序路径约束等
- 资源约束:又称面积约束,限制 FPGA 资源的使用量来适配目标 FPGA 的可用资源
- 布局约束:用于控制设计中各逻辑单元的物理布局,确保逻辑单元被放置到 FPGA 的指定资源区域内,从而提高时序性能、减少信号延迟并优化资源使用
FPGA / ASIC 的设计常分层为行为级、RTL 级和门级。行为级只写算法逻辑,不考虑硬件细节;RTL 级描述寄存器之间的逻辑运算和数据流,合成工具能直接将 RTL 转换成门级电路;门级为门电路和触发器的连接,是 RTL 综合之后的结果。RTL(Register Transfer Level,寄存器传输级)是硬件描述语言 HDL 对电路行为的一种抽象层级,主要描述寄存器之间的数据传输和逻辑运算,不关注底层由多少与非门、触发器组成,而是更高一层的“时钟边沿+数据流动”。
Vivado 使用
Vivado 可以创建 RTL Project 和 Post-synthesis Project,RTL Project 是最常用的完整设计流程项目,覆盖从 RTL 代码生成到比特流生成的全流程;Post-synthesis Project 用于导入已经完成综合的网表,聚焦于后端实现(布局布线、时序优化),适合复用已有的综合结果、快速验证不同实现策略的效果。
Vivado 是靠 tcl 工作的,GUI 界面是 tcl 的壳子,界面上的每一步操作都等价于在后台执行 tcl 命令。就像命令行和图像界面的关系一样,tcl 脚本的意义在于构建自动化的工程流程(创建工程、添加源文件、生成 IP、设置约束、综合实现、生成比特流、导出硬件),一些应用 tcl 的例子比如工程版本复现、批量生成 IP、根据顶层端口生成约束文件、多版本代码自动测试、不同优化性能下比较性能、快速验证多个参数组合的效果。Xilinx Tcl Store 是一个开源共享的 tcl 脚本库,其中有一些实用的 tcl 脚本,相当于 Vivado 的插件系统,可以扩展 Vivado 设计套件的核心功能。在 tcl store 中点击可以查看每个脚本支持的 tcl 命令。可以基于 tcl 脚本创建工程,Tools 选项卡中可以运行 tcl 脚本文件,也可以直接在 tcl console 中交互式运行 tcl 命令。Xilinx 官方关于 tcl 的文档为 UG894 和 UG835。
Vivado 有工程模式和非工程模式两种流程设计的模式。工程模式指直接用 Vivado 完成一套设计流程,先创建工程,然后让软件管理设计文件,生成报告信息等。非工程模式指用 Tcl 命令或者脚本来控制设计流,Vivado 不再对文件进行自动化管理,也不再报告相关信息,但是在每一个设计的阶段都可以进行新的设计分析以及约束分配,并且将更改后的设计以及约束直接更新到当前的设计流。
Tools 中有一些入门阶段接触不到但看起来似乎很实用的功能,先记录下来。Create and Package New IP 用于封装自定义 IP;Create Interface Definition 用于自定义接口标准;Partial Reconfiguration Wizard 用于实现 FPGA 的部分重配置功能,即在系统运行时动态更新 FPGA 部分区域的逻辑,用于自适应计算、多任务切换等需要灵活升级、资源分时复用的场景;Associate ELF Files 用于关联 elf 可执行文件,支持嵌入式程序的调试下载和运行;Generate Memory Configuration File 用于初始化 FPGA 的 BRAM、DDR 等存储器,指定上电初始数据;Compile Simulation Libraries 用于为第三方仿真工具编译 XIlinx IP 和硬件原语的仿真模型,确保第三方工具仿真时能正确调用 FPGA 底层硬件逻辑,保证仿真与硬件行为一致;Custom Commands 用于将自定义工具脚本命令集成到 Vivado 界面中;Language Templates 提供 Verilog、VHDL、Tcl 的代码模板;Settings 用于配置 Vivado 的全局参数。
Block Design 是 Vivado 里的图形化硬件系统设计方式;大多数情况下一个工程中只有一个 bd 文件,用来把系统全部搭建起来,不过也可以创建多个 bd 文件用于封装多个子系统。Open Block Design 可以选择打开项目中的某一个 Block Design。Generate Output Products 可以选择为某一个 Block Design 内的各个 IP Core 生成 HDL 底层实现文件,修改 BD 中的 IP 时需要重新执行。Create HDL Wrapper 是给 BD 生成一个顶层 HDL 文件,让综合器将 BD 当作一个普通 IP 来使用,生成的 Wrapper 就是综合/仿真时的入口文件,生成时可以选择让 Vivado 自动维护,修改 BD 时自动更新。通常先 Generate Output Products,再 Create HDL Wrapper。绑定引脚时以 Wrapper 中的声明为准。
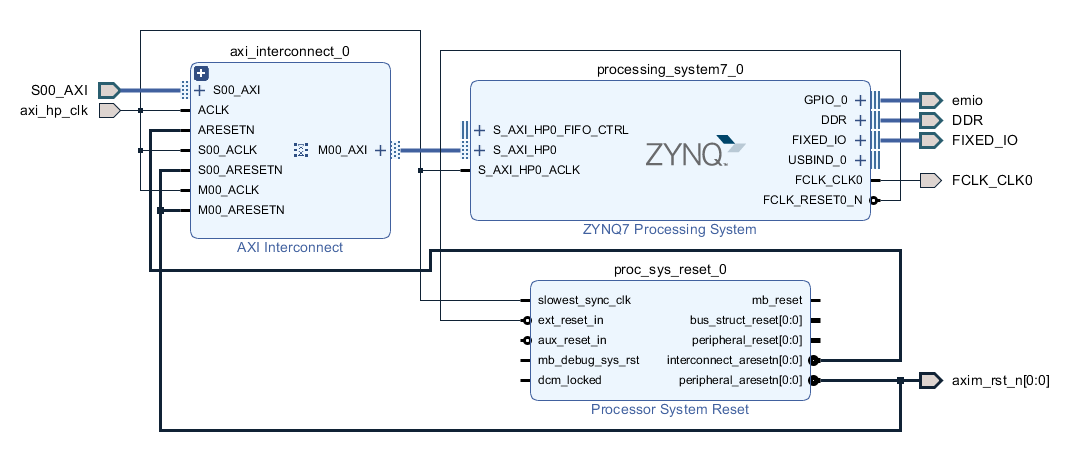
Block Design 中的实践建议:用一个 AXI Interconnect / AXI SmartConnect 把多个 PL 主设备连接起来,然后把 Interconnect 的 master 端接到若干个 PS_HP 口(把流量分散到 HP0..HPn)。给流量类型分口:例如 HP0→ 视频 DMA,HP1→ 以太网,HP2→ML 加速器,HP3→ 通用或低优先级流量。配置每个主设备的 AXI ID 与突发深度,调整 PS 端的 QoS/优先级寄存器(如果器件支持)以获得稳定性能。如果需要缓存一致性(例如加速器写入后 CPU 直接读),考虑走 ACP 或在协议层做显式的 cache flush/invalidate。然后做压力测试(多通道同时大量突发传输)来测出瓶颈并决定是否需要把更多 PL 主设备分配到不同 HP。
Report Methodology 是 Vivado 的“设计规范检查器”(Design Methodology Checker),可检测 HDL 设计是否符合 Xilinx 推荐的一系列规则和设计实践,并给出优化和修复建议。Report DRC(Design Rule Check)用于检查设计是否违反 FPGA 实现、布线、逻辑、IP、XDC、BD 的“硬性规则”,例如 IO Bank 电压不兼容、时钟走线错误、跨 Bank 电压冲突、约束冲突等。Report Noise 是 Vivado / Xilinx 工具中用于评估 FPGA I/O 信号“噪声问题(Noise)”的分析工具。 它主要用于分析地弹(Ground Bounce)、串扰(Crosstalk)、SSO(同时开关输出)噪声等 I/O 电气问题,一般用不到。上面说的三个 report,在 RTL Analysis、Synthesis 和 Implementation 中都有,各自会分别给出前端 RTL 代码编写和后端约束和优化的建议。除此之外,Report Utilization 可以报告综合后或实现后使用的逻辑资源量。
Schematic 原理图中会显示逻辑连接,右键某个模块,其中的 floorplanning 可以将当前选中的逻辑布置在自定义的 FPGA 中的某个物理区域(Pblock,即 Physical Block)中,相当于创建对布置的空间约束,让实现工具按照设置的约束来放置逻辑,这些逻辑在实现时就会被限制在这个区域里。右键模块,其中的 report timing 可以只对与该模块相关的路径进行时序分析并输出报告,包括输入 → 模块 → 输出的关键路径。大型工程里跑整个 timing report 比较杂乱。工程师通常只关心:哪个模块拖慢时序?为什么某个模块无法达到 300MHz?该模块内部是否有深逻辑?跨模块路径是否有 delay?等问题。另外,schematic 的 timing report 基于 post-implementation netlist,如果还在综合阶段,只能看到综合后的估计时序。setup = 数据必须在时钟沿到来之前稳定一段时间;hold = 数据必须在时钟沿之后继续保持稳定一段时间。另外,schematic 中还可以选择将原理图展开到不同的层级。还可以选择连线并 mark debug,assign 到 debug hub 的某个 probe 上。
布线工具是 EDA 的自动布线算法,读取网表(逻辑单元和连接关系)并决定每个逻辑单元放在 FPGA 上的哪个位置(Place),决定用哪些具体的导线 + 哪些开关,把它们连起来(Route)。实现的效果是把抽象的“逻辑连接” → 映射到具体的 物理导线和开关配置。输出的结果是一个 bitstream 配置文件,用来配置 FPGA 内部的 SRAM 控制每个开关的开关状态。
PS 端的工作大致可以分为两部分,一是与 PL 端的交互接口,这部分主要是基于 AXI 协议的开发;二是各种外设的接口,这部分根据例程调用相应的 API 即可,类似于 HAL 库的开发方式。配置完 ZYNQ 核中的 PS 部分之后导出端口、连线;之后 Generate Output Products,生成 block 输出文件,包括 IP、例化模板、RTL 源文件、XDC 约束、第三方综合源文件等,再用 Block Design(bd 文件)Create HDL Wrapper,最后导出硬件信息生成 sdk 文件夹,这就包含了 PS 端的配置信息。SDK 部分通过导出的 hdf 文件启动并建立 App 工程,完成 App 的软件开发后,通过 Run 或 Debug 在板子上运行。
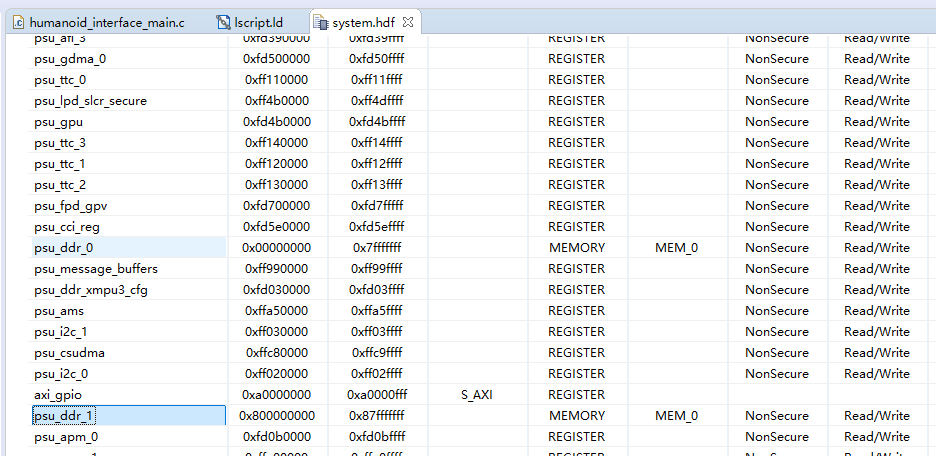
system.hdf 中包含了导出的硬件平台描述,用 SDK 打开后可以看到一张表格,其中 cell 一列表示 block design 中相应的硬件 IP 实例名,用于在软件层面标识。CPU 访问外设时,是通过 AXI 总线以内存映射寄存器的方式进行的,表格中 base address 和 high address 是分配给该外设的一段统一编址后的物理地址空间,每个外设都有一段寄存器空间。bsp 的 include 目录下包含了 xilinx 的各种头文件,其中包含各种宏定义和函数声明。xparameters.h 中定义了各个外设的基地址、器件 ID 和中断等。libsrc 目录下包含了外设函数定义和使用注释说明。lscript.ld 中定义了可用 memory 空间,栈和堆空间大小等,可根据需要修改。lscript.ld 中 psu_ddr_0_MEM_0 和 psu_ddr_1_MEM_0 的值是根据 system.hdf 文件来的,SDK 部分的代码也要与之保持一致。
从 vivado 2019.2 开始,xilinx 以 vitis IDE 替代原来的 SDK,vitis 的使用 SDK 大同小异。在 export hardware 之后会得到包含硬件信息的.xsa 文件,从 vivado-> tool-> launch vitis IDE 启动 vitis。进入 vitis 后将 workspace 定义在工程目录下,用.xsa 文件创建 platform project,后基于创建的 platform 创建 application 即可。
FPGA 通常有多种启动模式,称为 BOOT MODE,常见的包括 JTAG、QSPI、SD 卡;其中从 SD 卡启动需要 SD 卡为 FAT 文件系统,且卡中有 BOOT.bin 文件。无论选择哪种启动模式,在 SDK 中运行程序时都会通过 JTAG 接管系统,并按照配置执行初始化,比如先通过 JTAG 对整个系统复位,所有处理器核(A53、R5、PMU、PL)都会被复位,FPGA(PL 部分)被清空,所有寄存器恢复到默认状态;然后重新配置 PL 部分,通过 JTAG 重新下载 bit 文件;然后执行 psu_init 这个板级初始化脚本,完成 CPU、DDR、外设的初始化配置;然后上电激活 PL 端;选择运行的 CPU 核并挂起,下载程序之后运行 elf 文件。
Vivado 编译提速
- vivado 吃单核 CPU 性能和内存频率,硬件升级可以带来最大程度的提升。
- 用 set_param general.maxThreads 8 设置最大线程数,并写入 Vivado 安装路径的 scripts 文件夹中新建 Vivado_init.Tcl 文件中;2017.4 版本的 vivado,最大只能设置到 8。
- linux 比 windows 的编译速度略快。
- 软件版本上,目前 2024.2 是最快的。
- 不同的综合和实现策略上,在设置中选择 Flow_RuntimeOptimized 的综合策略,可以略微提速,但这是以实现性能换编译时间,测试完成或发现时序难以满足要求时,需要换回默认策略。这个方法一般不建议使用。
IP 和 Module
Module 一般指用户写的 RTL 代码,是纯粹的 Verilog / VHDL / SystemVerilog 模块,完全掌握源码,可综合可仿真;IP(Intellectual Property Core)一般指 Xilinx 或第三方提供的与构建电路,经过了验证和优化,打包成黑盒,在工程中表现为 .xci 配置文件,存储了 IP 名称、参数配置、版本号、生成代码的路径等信息,用于告诉 Vivado 怎么生成这个 IP。Vivado 根据 .xci 文件 Generate Output Product,即生成 RTL、网表.dcp 或.edf、仿真模型、约束文件.xdc、wrapper 文件、资源报告等。有的 IP 只有 netlist(加密,看不到源码,不能直接修改逻辑),IP 可以配置,底层实现可能包含厂商专用的宏元件,用户不能直接手写,有的 IP 甚至包含仿真模型和约束文件。从使用上说,IP 是一个特殊的 Module。可以自定义 ip 或添加第三方 ip。
在 FPGA/SoC 设计语境中,IP 核(Intellectual Property Core)指的是一种可复用的逻辑模块实现,可以是 HDL 描述的、可综合到 FPGA 逻辑中的软核 IP;也可以是直接固化在硅片中、不需要综合的硬核 IP;还可以是固件宏块,类似于硬核 IP 但是核 FPGA 可编程逻辑共享工艺。例如:PS UART 在硬件上是 ZYNQ 芯片 PS 区域的一块 UART 控制电路(硬核 IP);在软件上,它暴露一组寄存器地址,CPU 通过 AXI 总线访问这些寄存器就能控制 UART;在引脚上,它把 TX 和 RX 信号通过 MIO 和 EMIO 引脚输出,连接到板上外设,比如 USB-UART 转换芯片。
Xilinx 提供了功能丰富的 IP,入门阶段接触比较多的有:
- AXI 相关的:AXI Interconnect、AXI Stream FIFO、AXI DMA 等
- FPGA 基本资源相关的:Block Memory Generator、FIFO Generator、Clocking Wizard、SelectIO Interface Wizard、XADC Wizard 等
- 运算相关的:CORDIC、Divider Generator、Floating-point、FFT、DTF 等
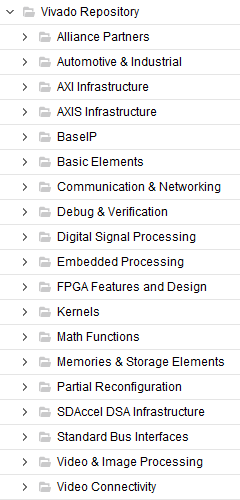
像加法器、乘法器这样 Verilog 代码很容易实现的功能,也有相应的 IP。一行 Verilog 代码和工程级别的 IP 差距巨大,IP 的意义在于高性能的运算器,重要的是底层硬件结构。比如加法有 ripple-carry、carry lookahead、carry select、prefix adder 等实现方式;乘法有 DSP Silce、Booth、Wallace Tree 等实现方式;以及是否支持流水线,流水线级数如何配置;位宽的变化怎么处理;延迟 latency 怎么控制等。Verilog 代码的默认实现存在性能不一定够、时序不一定收敛、资源不一定最优、不确定实现的硬件资源可能是 DSP 或 LUT、跨时钟域和多周期路径无法处理、不支持 pipeline、频率上不去、不支持 ready/valid 的 backpressure 设计等一系列在实际工程中才会考虑的问题。
生成 IP 或模块时,一般会选择 Out-of-Context 综合/实现 (OOC),即单独综合/实现一个时序独立、不受外部逻辑影响的模块,因为 IP 模块可能很复杂,如果每次综合整个工程就会非常慢。OOC 相当于提前单独综合好,工程里直接引用已完成的网表。
常用 IP 配置说明
AXi 协议桥接相关
Xilinx 提供的 IP,有一大类是涉及 AXI 协议的,AXI 协议分 AXI4、AXI3、AXI4-LITE、AXI4-Stream,AXI3 协议基本不再使用,以下说明均针对 AXI4、AXI4-LITE 和 AXI4-Stream,并简称为 AXI、AXI-LITE 和 AXI-Stream。
AXI 和 AXI-LITE 都采用内存映射控制,有地址的概念,有五个独立的通道;而 AXI-Stream 采用连续流式控制,没有地址的概念,只有一个通道。AXI 和 AXI-LITE 的区别在于前者支持单地址多数据的 burst 传输,而后者仅支持单地址单数据传输,一般用于访问和配置寄存器。在一个 ZYNQ 架构的系统中,通常的数据流分布为:PS 端的处理器、DDR、FPGA 侧的 BRAM 等都是块式存储,而 PL 端的加速器、许多数据处理的 IP、FIFO 等都是流式存储,因此需要频繁地在 AXI 和 AXI-Stream 两中协议之间作桥接。
可以实现上述桥接功能的 IP 如下:
- AXI-Stream FIFO:存在 S_AXI、AXI_STR_RXD、AXI_STR_TXD 三组端口,有三种使用模式:AXI_STR_RXD(输入) + S_AXI(输出),此时等价于一个 AXIS → MM 桥接 FIFO;S_AXI(输入) + AXI_STR_TXD(输出),此时等价于 MM → AXIS 桥接 FIFO;AXI_STR_RXD(输入) + AXI_STR_TXD(输出),此时相当于纯 AXI Stream FIFO,与 AXI Stream Data FIFO 一样。
- AXI4-Stream Accelerator Adapter:含有 AXI4-Stream 接口、AXI4-Lite 接口、BRAM/FIFO 接口、标量接口。支持非对称多缓冲数据宽度,允许 AXI4-Stream 和 BRAM/FIFO 接口之间的灵活数据宽度转换(S2M、M2S、M2M、FIFO2S、S2FIFO)。其中 S_AXI 为 AXI4-LITE 接口;S_AXIS_n、M_AXIS_n 均为 AXI-Stream 接口;AP_CTRL 为与加速器握手的信号组;AP_BRAM_IARG_n 和 AP_BRAM_OARG_n 分别为 BRAM 的输入和输出端口,需连接到 Block RAM Controller 或自己设计的 BRAM IP。
- AXI DataMover:通过操作 AXI-stream 接口操作 PS 端 DDR。对于写 DDR(数据由 PL 端产生,通过操作 AXI-stream,AXI-stream 协议转换成 AXI4,AXI4 操作 HP 接口,从而写入 DDR);对于读 DDR(数据通过 HP 接口读出到 AXI4,AXI4 转协议 AXI-stream,PL 读取 AXI-stream 的结果)。与 AXI DMA 的区别在于 DataMover 不需要 CPU 初始化 DMA,PL 为绝对主控。
- AXI Direct Memory Access:AXI4-Lite 用于对寄存器进行配置,M_AXI_MM2S 用于 AXI4 Memory Map Read(读内存写加速器),M_AXI_S2MM 用于 AXI4 Memory Map Write(读加速器写内存)。S_AXIS-S2MM(fifo 往 dma 写数据);M_AXI_S2MM(ddr 从 dma 读数据);M_AXIS_MM2S(dma 往 fifo 写数据);M_AXI_MM2S(dma 从 ddr 读数据 )。AXI DMA 是 AXI memory-mapped ↔ AXI-Stream 之间的桥梁,负责在地址空间和流式接口之间转化。DMA 通道有 MM2S 和 S2MM,分别负责两个方向。大部分使用 AXI DMA 的场景,都涉及 PL 与 PS 的数据交互,少部分的情况下,纯 PL 也有用到 AXI DMA 的场景,比如 HLS IP 需要一次处理上万点的 FFT 输入,图像处理需要 1280*720 一帧图像作为输入,CNN IP 需要一整块 feature map,即数据并不是逐拍的流式接口能传输的,而是需要将数据存储在一块 Memory 中,这时就需要用到 AXI DMA 来搬运。另外,PS 端也有 DMA,STM32 中提到的 DMA 就是这种,用于内存和外设之间的数据交互,不支持流式接口。AXI Multi Channel Direct Memory Access 为 AXI DMA 的多通道版。
- AXI Memory Mapped to Stream Mapper:单方向的 MM2S
选择使用哪个需要根据具体应用场景判断。
存储结构相关
FPGA 开发中最常用的三种存储的逻辑结构是 RAM、ROM 和 FIFO,其中 ROM 由 RAM 配合 coe 文件作为初始化数据实现,这里不再单独叙述。RAM 可由 BRAM 或 LUT 实现,相应的 IP 分别为 Block Memory Generator 和 Distributed Memory Generator;FIFO 可由 RAM 或 Built-in FIFO 实现,IP 为 FIFO Generator。这几个 IP 的配置逻辑很大程度上是类似的,下面一并说明。
首先,存储类功能的开发本质上就是配置相应的存储空间的接口和访问方式,然后写代码维护数据、地址和读写控制逻辑,这里集中对 IP 配置进行说明。
Interface Type 可配置为 Native 或 AXI4 ,区别在于访问协议,Native 信号简单,延迟低,时序友好,需要自己设计握手逻辑,在 RTL 中自己控制读写逻辑;而 AXI4 Interface 使用 AXI 标准总线协议,一般用于直接连接 MicroBlaze、PS 端、AXI DMA、AXI Interconnect 等,配置为哪个取决于是什么模块访问这块存储(访问的发起者)。Data Width 和 Data Depth 分别为数据位宽和数据深度,即单个数据含多少 bit,以及最大可存储的数据个数。
RAM 的 Memory Type 可配置为单口 RAM、伪双口 RAM、双口 RAM、单口 ROM 和双口 ROM。单口 RAM 只有一组地址、数据、读写控制端口,不能同时读写;伪双口 RAM 有两个独立端口,但一个只读一个只写;真双口 RAM 有两个均可读写的独立端口。byte write enable 用于分字节控制写入,不启用则默认写使能控制全位宽。此外还可以配置读写冲突的处理模式,WRITE_FIRST 是当对同一地址同时进行读写操作时,写入的新数据会立即输出到读端口,推荐用于异步时钟可能导致读写同时操作的场景(如跨时钟域数据交互),确保读端口能及时获取最新写入的数据;READ_FIRST 是当对同一地址同时进行读写操作时,读端口输出的是写入前的旧数据,新数据会在之后的周期更新到存储中。该模式能保证无冲突,但功耗较高,适用于需要安全读取 “旧数据” 的场景(如数据备份、状态校验),确保读操作的可靠性。NO_CHANGE 是写操作时,读端口数据保持不变;仅在读操作时才会更新输出。该模式功耗最低,但不保证双端口同时访问同一地址时的冲突问题,适用于对功耗敏感、且能通过外部逻辑避免地址冲突的场景。最后,还可以配置 Primitives Output Register 和 Core Output Register,用于寄存数据,增加时序裕量,适合对输出时序要求更高的场景;不配置的情况下,默认数据之后地址一个时钟周期。配置完成后,剩余的工作就是自己写代码维护数据、地址和读写控制。
FIFO 的 FIFO Implemetation 可选择时钟域为 common clock 或 independent clock,存储资源可配置为 Block RAM、Distributed RAM、Shift FIFO 和 Builtin FIFO。Read Mode 可配置为 Standard FIFO 和 First Word Fall Though,前者是标准 FIFO 模式,数据需通过读使能触发后,在下一个时钟周期才能从输出端读取。即读操作存在 1 个时钟周期的延迟,用于对时序控制要求严格的场景(如跨时钟域同步、流水线设计),需明确通过读使能控制数据读取时机。后者是首字直通模式,数据会自动预加载到输出,无需等待读使能触发,FIFO 非空时第一个数据就会直接出现在数据线上,读使能时数据呗消费,下一个数据自动加载,读操作无延迟,适用于低延迟需求的场景(如实时信号处理、高速数据流交互),可减少读操作的等待时间,提升数据吞吐效率。FIFO Generator 可以配置一系列标志位,除了标配的 full 和 empty 外,还有 almost full、almost empty、overflow、underflow、write ack、read valid。full 的局限性在于,上游模块写入速度快于 FIFO 处理速度时,full 信号发出时已经写入了数据。almost 信号可以通过配置阈值来提前预警。overflow 和 underflow 用于错误检测。很多工程师都踩坑:Empty = 1 时读一次,你会读到无效数据,容易造成后端异常。Underflow 就是发现这种情况的保护机制。write ack 用于告诉已经写入成功了,read valid 用于告诉读出的数据是有效的。FIFO 设置默认为采用 safety circuit,此功能是保证到达内部 RAM 的 输入信号是同步的,在这种情况下,如果异步复位后,则需要等待 60 个最慢时钟周期(时钟频率最低的时钟的 60 个时钟周期)。full 信号和内部状态机共同控制 wr_en 写使能,写使能时更新数据,不使能时保持数据不变(不更新);empty 和内部状态机共同 rd_en 读使能。
IP 功能表
通信和网络、AXI 外设、MicroBlaze 软核 CPU、标准总线(PCI 等)、TMR 三模冗余、数字信号处理、视频和图像处理、视频接口这几类 IP 此处没有列出。
AXI 协议类
- AXI-Stream FIFO:带桥接功能的 FIFO
- AXI4-Stream Accelerator Adapter:AXI4-LITE 协议和 AXI Stream 之间的桥接,支持多个 Stream-to-Memory(S2M)、Memory-to-Stream(M2S)和 Memory-to-Memory(M2M)通道。
- AXI4-Stream Broadcaster:AXI4-Stream 的多路分配器,支持 Remap。
- AXI4-Stream Clock Converter:实现 AXI4-Stream 数据流的跨时钟域(CDC)传输,内部通过 FIFO 或寄存器管道(Register Slice)实现数据同步。
- AXI4-Stream Combiner:AXI4-Stream 的数据选择器。
- AXI4-Stream Data FIFO:AXI4-Stream 的 FIFO。
- AXI4-Stream Data Width Converter:AXI4-Stream 的位宽转换。
- AXI4-Stream Interconnect:用于 Block Design 中,AXI4-Stream 的数据流路由,可配置的多主到多从(最多 16x16)交叉点开关,支持在不同模块之间自动调整数据宽度。
- AXI4-Stream Interconnect RTL:同为 AXI4-Stream 的数据流路由,但为 RTL 固定架构,小型轻量化,占用资源少,不能用于 Block Design 中。
- AXI4-Stream Protocol Checker:实时检测 AXI4-Stream 接口上的协议违规行为,并通过状态寄存器或信号指示具体的违规类型。
- AXI4-Stream Register Slice:为 AXI4-Stream 数据流插入寄存器管道(Register Slice),以优化时序、提高最大时钟频率(Fmax)或隔离时钟域,通过寄存器管道缩短关键路径,提高系统时钟频率,用于时序优化。
- AXI4-Stream Subset Converter:通过增减和重映射 AXIS 辅助信号,实现不同的 AXI4-Stream 协议子集之间的转换。
- AXI4-Stream Switch:支持对多个 AXI4-Stream 数据流进行静态或动态地选择、路由、切换。
- AXI BRAM Controller:以 AXI 接口读写 BRAM,用于 PS 端控制 BRAM。
- AXI Central Direct Memory Access: Memory-to-Memory DMA,不经过 AXI-Stream,用于内存块复制。
- AXI Chip2Chip Bridge:用于将 AXI 总线延伸到另一颗 FPGA 或芯片,实现不同芯片间的 AXI 互联。
- AXI Clock Converter:用于 AXI4 和 AXI4-Lite 协议在不同时钟域之间桥接 AXI 事务,支持同步和异步时钟域的转换。
- AXI Crossbar:将多个 AXI Master 端口连接到多个 AXI Slave 端口,实现任意 Master → Slave 的访问。
- AXI Data FIFO:AXI 的 FIFO。
- AXI DataMover:支持在 AXI4 和 AXI4-Stream 两种不同的接口之间进行数据传输。
- AXI Data Width Converter:AXI 的位宽转换。
- AXI Direct Memory Access:在内存(DDR/BRAM)与 AXI-Stream 外设之间进行高速自动数据搬运,可实现 AXI Memory Mapped (MM) 与 AXI4-Stream (AXIS) 的桥接。
- AXI EMC:AXI 外部存储控制器,用于在 PL 侧外接存储设备;支持 sram,nor flash ,psram,cellularRAM,IP 核使用 AXI4 接口,支持 32bit 和 64bit 的数据位宽。
- AXI Interconnect:用于 Block Design 中,AXI 的数据流路由。
- AXI Interconnect RTL:同为 AXI 的数据流路由,但为 RTL 固定架构,小型轻量化,占用资源少,不能用于 Block Design 中。
- AXI Memory Mapped to Stream Mapper:从 AXI4 内存映射域读取数据,转换为 AXI4-Stream 数据流。
- AXI MMU:Memory Management Unit,内存管理单元;负责在 AXI 系统中执行虚拟地址到物理地址的转换、内存保护和权限管理;本质上就是从 AXI4 内存映射域转换到另一个 AXI4 内存映射域。
- AXI Multi Channel Direct Memory Access:AXI Direct Memory Access 的多通道版本。
- AXI Performance Monitor:通过 AXI-Lite 接口进行配置,用于精确测量 AXI 系统的总线延迟、内存流量、吞吐率等关键指标。
- AXI Protocol Checker:实时检测 AXI 接口上的协议违规行为,并通过状态寄存器或信号指示具体的违规。
- AXl Protocol Converter:用于在 AXI 的子协议 AXI3、AXI4、AXI4-LITE 之间转换。
- AXI Protocol Firewall:实时监控 AXI 接口的事务,检测协议违规、超时或用户触发的软阻塞(Soft Block),并在必要时阻断进一步的事务传输,同时为未完成的事务生成协议合规的响应。
- AXI Register Slice:为 AXI 数据流插入寄存器管道(Register Slice),以优化时序、提高最大时钟频率(Fmax)或隔离时钟域,通过寄存器管道缩短关键路径,提高系统时钟频率,用于时序优化。
- AXI SmartConnect:用于 Block Design 中,AXI Interconnect 的升级版,占用资源也会更多;作为多主多从设备的 AXI 互连中心,动态适配不同的协议、数据宽度、时钟域和突发特性,简化系统设计并优化性能。它集成了多项高级功能,如协议转换、数据宽度转换、时钟域转换和流水线优化。
- AXI Video Direct Memory Access:专为图像视频二维数据设计的 AXI DMA,支持改变帧速率、缓存帧。
- AXI Virtual FIFO Controller:通过 AXI4-Stream 接口将外部内存段组织为多个虚拟 FIFO 块,用于需要大容量数据缓冲的场景。将外部 DRAM(如 DDR3、DDR4)划分为多个虚拟 FIFO 通道(最多 8 个),通过 AXI4 内存映射接口访问内存,并提供 AXI4-Stream 接口进行数据读写操作。
运算类
DSP48 Macro:使用 FPGA 的 DSP Slice 实现高效的数字信号处理运算,通过简单的配置界面自定义 DSP 操作并自动映射到 FPGA 的 DSP Slice 资源。DSP Macro IP 提供了高度灵活的指令集配置,支持动态或静态操作选择。
Adder/Substractor:加法/减法器。
Accumulator:累加器。
Multiply Adder:乘加器。
Multiplier:乘法器。
Complex Multiplier:复数乘法器。
Divider Generator:除法器。
Floating-Point:浮点运算,支持绝对值、比较、累加、加减、乘法、乘加、除法、指数、对数、倒数、平方根、平方根倒数、浮点转定点、定点转浮点、不同精度浮点数转化。
CORDIC:一种不使用乘法器,只用加法器 + 移位器就能高效计算三角函数、平方根、向量旋转等数学运算的算法。支持向量旋转、平移、正弦余弦正切、双曲正弦余弦正切、平方根。
调试类
- ILA:逻辑分析仪,用于 debug 抓取信号波形。
- System ILA:ILA 的升级版,除了 RTL 信号 probe,还可以接 AXI4-Stream 或 AXI-Lite,可以抓取整个系统的高速数据流,支持跨模块同步采集。
- VIO (Virtual Input/Output):作为虚拟 IO 使用,VIO 的输出可以控制模块的输入,VIO 的输入可以显示模块的输出值。正常编译把 bit 文件和 debug 文件下载到 FPGA 中,自动弹出的界面 vio 中右键信号进行设置 toggle button。
- AXI Traffic Generator:用于 FPGA 仿真或验证的 AXI 总线数据流生成器 IP。可以像 CPU 或 DMA 一样在 AXI 总线上发起可控的读/写事务,可以模拟真实应用中的数据流。
- AXI Verification IP:支持用户对 AXI4 和 AXI4-Lite 进行仿真的 IP。它还可作为 AXI Protocol Checker 来使用,只是仿真 IP,将不进行综合。模拟 AXI 主设备、从设备或直通模式,支持 AXI4、AXI3、AXI4-Lite。
- AXI4-Stream Verification IP:支持用户对 AXI4-Stream 进行仿真的 IP(只仿真不综合)。模拟 AXI 主设备、从设备或直通模式。
- Debug Bridge:调试接口桥接 IP,用于将调试流量(Debug Traffic)从 JTAG、AXI、UART、Ethernet 等外部接口,桥接到内部的 Debug Hub,从而访问 ILA/VIO 等调试 IP。在 Debug Bridge 支持下, 可以用 AXI/UART/PCIe/以太网远程调试。
- JTAG to AXI Master:用 JTAG 口直接读写 AXI 总线的工具。允许在 Vivado Hardware Manager 中实时读写 AXI 寄存器,而不需要 CPU、软件驱动、外设,相当于一个指令来自 JTAG 的 AXI Master,允许通过 JTAG 执行 AXI4-Lite 读写寄存器、AXI Memory Mapped 读写内存地址、AXI Master burst 访问(AXI4 接口模式)、外设调试(如 DMA、BRAM、加速器寄存器)。
- Simulation Clock Generator:用于在仿真中生成一个或多个可配置频率、占空比、相位的时钟信号,供仿真设计使用,不参与综合。
- Simulation Reset Generator:用于在仿真中生成一个或多个可配置宽度和时序的复位信号,供仿真设计使用,不参与综合。
实用类
- Block Memory Generator:用 BRAM 实现 RAM、ROM。
- Distributed Memory Generator:用 LUT 实现 RAM、ROM。
- FIFO Generator:生成 FIFO。
- Clocking Wizard:产生不同频率的时钟。
- Processor System Reset:复位管理模块,用于统一产生、同步和分发复位信号。
其它
- Utility Buffer:用于 Block Design 中,负责生成相应的缓冲区,以便将来自芯片外部的信号引入内部电路,或者将内部电路的信号输出到芯片外部,确保信号在穿越芯片边界时的完整性和稳定性。
- Utility Idelay Control:用于 Block Design 中,FPGA 中所有 IDELAY / ODELAY 模块的全局校准与控制器。
- Utlity Reduced Logic:用于 Block Design 中,多位逻辑运算。
- Utility Vector Logic:用于 Block Design 中,归约逻辑运算。
- Concat:用于 Block Design 中,位拼接。
- Slice:用于 Block Design 中,位提取。
- Constant:用于 Block Design 中,常数。
- ECC:对数据添加 ECC 校验位(Encoder),对数据进行 ECC 检查与纠错(Decoder)。
- Memory Interface Generator (MIG 7 Series):Memory Interface Generator,官方提供的 DDR2/DDR3/DDR3L/LPDDR 内存控制器 IP,用来把外部 DDR 内存连接到 FPGA 并提供可直接使用的 AXI 接口。注意“外部 DDR” 指的是连接到 FPGA(PL)I/O 引脚上的 DDR 内存。 PS 端的 DDR 不算 外部 DDR,它属于 PS 内存子系统,由 PS 内部的 DDR 控制器管理,不需要 MIG。
- Binary Counter:计数器。
- Fixed Interval Timer:硬件定时器,用于生成固定时间间隔的事件。
- RAM-based Shift Register:高效的移位寄存器。
- oddr:单时钟沿数据转为双时钟沿数据。
- IO Module:封装 FPGA 外部 IO 接口,实现逻辑与物理 IO 的标准化、可配置管理。
- SelectlO Interface Wizard:将 FPGA 内部逻辑信号映射到外部高速 I/O 引脚(SelectIO),支持高速串行、并行接口、电平标准、延迟控制等功能,用于实现 FPGA 内部逻辑和高速外部引脚的桥接。
- XADC Wizard:配置 FPGA 内置 XADC 模块,用于采集模拟信号、片内电压和温度,并将其数字化输出。
Petalinux
为了在 Xilinx 的硬件平台上运行 Linux,需要使用 Petalinux 工具。Petalinux 不是 Linux 内核,而是一套配置开发环境的工具,降低 uboot、内核、根文件系统的配置的工作量,可以从 Vivado 导出的硬件信息自动完成相关软件的配置。Petalinux 本身基于 Yocto Project(嵌入式 linux 定制框架)构建,内置了针对赛灵思硬件的交叉编译工具链(如 arm-xilinx-linux-gnueabi),支持在 x86 主机上编译针对 ARM 架构的 Linux 内核、驱动和应用程序。Petalinux 编译后会生成嵌入式系统的核心镜像,包括 Linux 内核镜像(定制化的 Linux 内核)、设备树 Device Tree Blob(描述硬件拓扑)、根文件系统 rootfs(包含系统库、命令行工具、应用程序等,Python 就在这里面)、启动加载器 bootloader(默认使用针对 Xilinx 硬件优化的 u-boot)
下面简单记录按照 Alinx 厂家的教用 Petalinux 制作板子镜像并固化到 SD 卡的过程,详细步骤见教程。由于 Petalinux 对系统版本和设置有严格要求,这里按照 Alinx 厂家的教程,在 PC 的虚拟机上安装 ubuntu16.04(或者双系统也行)并在 ubuntu 上面安装 Petalinux2017.4。用 Petalinux 定制 Linux 系统涉及 Vivado 工程和 petalinux 工程,在 Vivado 中编译生成 bit 文件,导出硬件信息并得到包含硬件信息的 hdf 文件,Petalinux 根据 hdf 文件配置 uboot ,内核、文件系统等。
1
2
3
4
5
6
7
8
9
10
11
12
# 创建Petalinux工程
petalinux-create --type project --template zynq --name ax_peta
# 基于Vivado导出的hdf文件,由配置界面配置硬件信息
petalinux-config --get-hw-description ../linux_base.sdk
# 由配置界面配置内核
petalinux-config -c kernel
# 由配置界面配置根文件系统
petalinux-config -c rootfs
# 编译
petalinux-build
# 生成BOOT文件
petalinux-package --boot --fsbl ./images/linux/zynq_fsbl.elf --fpga --u-boot --force
在 PC 的 Linux 上用 disk 工具,分区出 FAT 和 EXT,此时可以把文件放入 SD 卡的 EXT 分区中(Windows 系统是不显示 EXT 分区的,Linux 可以,所以放文件要在 PC 端的 Linux 下操作);然后将工程目录 images –> linux 目录中的 BOOT.BIN 和 image.ub 复制到 SD 卡的 FAT 分区即可。如果需要打包成 img 镜像,使用 imageUSB 工具即可。
Petalinux 的版本和 Python 的版本是绑定的,但 Xilinx 的官方文档中并没有给出对应关系,目前已知 Petalinux2023.1 对应 python3.10.6。如果需要改 Python 版本就需要尝试安装不同的 Petalinux 版本并完成整套的 Linux 系统定制,在板子上运行起来编译出的镜像之后,由 python3 –version 才能查到这个 Petalinux 版本对应的 Python 版本是否符合要求。
另外再多说一句图形界面相关的问题(完全可以不用图形界面拥抱命令行,不过已经问过了相关的情况,这里就一起记录下来了),Petalinux 自带桌面系统 matchbox,但这个系统与 ZYNQ 7000 架构的适配有 bug;Alinx 厂家是自己移特制 Linux 内核和经过移植的 Debian 桌面文件系统,理论上应该也可以自己移植 Linux 其它发行版如 ubuntu 的桌面系统,但移植时涉及文件系统,Python 版本和库也要在此时一并作好处理;不过移植 Linux 在没有接触过的情况下工作量太大坑太多,并且图形界面也不是刚需,这里就不配置了。
Debug 经验
对于时序逻辑和组合逻辑的综合电路,建议分开把组合逻辑部分和时序逻辑部分分开写,遵循组合逻辑用阻塞赋值,时序逻辑用非阻塞赋值的原则。若组合逻辑部分也用非阻塞,会出现因并行导致时序逻辑用的是上一时刻的值(组合逻辑还没更新完,时序逻辑就并行执行了)。而阻塞赋值有
always块中对reg赋值,以及assign中直接对wire赋值两种;具体使用根据变量类型以及要描述的组合逻辑的复杂程度决定。组合逻辑容易出现竞争和冒险现象,而时序逻辑一般不会出现;组合逻辑的时序难以保证,而时序逻辑更容易到达时序收敛,更可控。
状态机分 Moore 和 Mealy 两类:Moore 状态机的输出只与当前状态有关而与当前输入无关,即输入与输出隔离;Mealy 状态机的输出与当前状态和当前输入都有关,输入变化输出立即变化,响应比 Moore 状态机快一个时钟周期。一般使用三段式状态机,三个步骤分别为:传递寄存器状态(时序逻辑、非阻塞);根据当前状态确定下一个状态(组合逻辑、阻塞);由状态确定输出(组合逻辑、阻塞)。另外,可以分别用状态方程和输出方程代替状态机的后两个步骤中冗长的 case 写法。
always块有两种用法:always @ (*)用于对组合逻辑建模,输出对所有输入敏感,这种always块用阻塞赋值;always @ (posedge/negedge xxx)用于对时序逻辑建模,只在时钟上升/下降沿更新输出,这种always块用非阻塞赋值。assign同样是用于组合逻辑的,可以看作是always @ (*)的简便用法,always @ (*)块相较于assign可以表达更复杂的组合逻辑。always @ (*)和case可构成 mux。不指定位宽时,默认为 32 位的位宽,建议显式指定位宽。另外为了方便表示,建议都使用十进制 d 而不用二进制 b 或其它进制表示数值。
模块内部可以声明 wire 作为中间变量来表示中间结果。模块连线时,对于悬空无连接的端口,建议显式
.xxx()来表示悬空,而不要不写这个端口。xdc 文件中约束的端口需要与顶层模块中的一致,管脚约束是加在顶层的设计文件上的
axi_gpio 的中断会在任一 GPIO 接口数值变化时产生一段时间的高电平,无论数值由 0 变 1 还是由 1 变 0
移位需要初始化,如果不初始化默认全 0,移多少位都还是全 0,没有现象的。初始化在可综合的实际电路中一般是靠复位信号实现的,initial 是不可综合的;rst 信号在 7010 上是由 ps_block 给出的。另外,ps_block 还会给出一个 clk,也可以用。
在实例化端口连接时,inout 不能接 output
PS 端的 IO 分配是固定的,自然也不需要在 Vivado 中分配管脚,但需要建立 Vivado 工程中配置 PS 管脚,也需要将 ARM 添加到工程中才能使用。
IOBUF 的 IO 引脚不能被 FPGA 内部逻辑当作信号源。不能把 IOBUF 的 IO 端口(即 .IO)连接到一个非顶层的 inout 信号,哪怕那个信号最终又连接到顶层的 inout。只有顶层 inout 才能合法地驱动 IOBUF 的 IO 端。
打开了 deign 还 implementation 失败就重新 synthesis 一下,即使提示 up-to-date。(重新 setup debug 之后会这样)
FatFs 库函数编译时报错未定义:read_ddr/Debug 目录下的 objects.mk 文件,在 LIBS 中加上-lxilffs。或者换一个有 xiff 库的 bsp 然后再换回来(这样可以刷新一下)
在 AXI Interconnect 中,“哪个 master 通道连接到哪个 slave 通道”, 并不是物理上固定连接,而是通过 Vivado Address Editor 的地址映射 + 连接矩阵 定义的。
DONE pin is not high on target FPGA:这是从 SDK 启动时有时会出现的提示,需要在 SDK 中为所启动程序的 run configuration 中配置 program fpga,让板子在启动时先把 bitstream 加载进去再启动程序。(这是 Vivado 2017 版本的解决方案)。DONE 引脚本身表示 PL 加载成功,FPGA 被正确配置完成后,DONE 引脚电平会被拉高。
多线程编程的消息传递中,两个线程并行对共享的 DDR 地址读写时,不能保证读取在写入之后才发生。为了确保读取到写入的 flag,可以死等。要注意多线程不要访问互斥资源。
verilog 默认以 unsigned 处理数据,对于有符号数需要用 signed 声明,否则会影响对符号位的解释。另外,即使信号声明为
signed,一旦参与运算的表达式中有 unsigned 或默认推断为无符号的部分,Verilog 会 自动把整个表达式转为 unsigned 计算。写$signed()是为了“锁死表达式为有符号运算”,防止 Verilog 自行提升为无符号算术。乘法运算要以两倍扩宽处理,结果要做截断判断处理,否则可能发生溢出。
DUT(Device Under Test)和 testbench 中的信号类型对应关系:DUT 中的 input 需要 tb 来驱动,因此用可以在过程块中赋值的 reg;DUT 中的 output 不由 tb 赋值,只连接 wire 来接受即可;常量也可以用 wire,在声明的时候就设定好值。
仿真中可以使用 real 的数据类型和 task 结构,但不能直接综合到 FPGA 中,因此不能用在设计中。
搞不出来的时候就单独测试模块,输入自己给定值。
AXI 规范要求 AR/R 事务一旦开始,不允许中途中止。一旦在 R 通道阶段突然把状态打回 IDLE,不再给 RREADY(在 IDLE 状态默认 RREADY = 0),但从端仍可能继续送数据。这会导致 RVALID 有数据了,但状态机认为自己“没请求”/“不该收了”,现象是数据在 S_RD_WAIT 就出现,这是因为 slave 正常返回了 RDATA,但主机状态机不在正常处理路径。
状态机的 state_next 是时序逻辑赋值,否则会延后两个周期,甚至卡死在某一个状态。流水线是一种隐式的状态机,由各级数据的 valid 信号来标示状态。
负数的十六进制表示,是正数十六进制的表示取补码
加减法需要对齐 Q,乘除法不用;比较的时候,位宽和精度 Q 要一致
理论上,所有的赋值语句左右位宽都要一致,只不过有的运算会自动扩展扩宽。自动扩展位宽的运算包括加减法、乘法、整数除法、取模、各类比较运算。
符号位扩展要复制最高位(符号位),即正数补 0,负数补 1。
右移的时候,是有可能丢失精度的。
数据不同步时,要么给 backpressure,要么就 buffer 缓存起来,不然会丢数据;方案选择上,能 backpressure 就用,不行就缓存。
入口处通常会配备 skid,用于缓存上游数据已经送来,但下游突然拉低 tready 导致数据送不出去的那一拍数据。中间计算步骤的工作数据和相应的 valid 信号记为 stage_data 和 stage_valid。
SDK 中的 memory 调试界面可以实时显示 DDR 指定地址的数据值。DDR 读写同一时刻只能一个主机,所以实际使用中需要 PL 跟 CPU 设置握手信号,避免读写错误的数据。
ILA IP 被综合进 PL 逻辑电路中,本质上是片上逻辑分析仪,每个时钟沿采样一次所监控的信号;点击 run trigger for this ILA core 时,背后执行操作是从现在开始采样,直到触发条件满足,就把触发点前后的一段波形存下来(不设置触发条件的情况下,将点击 run 的时候视为触发)。ILA 抓取到的数据是运行中 PL 内部信号的采样结果,相当于捕获了那一瞬间的硬件状态,是对信号状态的一次快照,而不是仿真或重启程序。
找不到问题的时候,可以试试单元测试,把其它的都注释掉,只测试某一个模块。
IP 中的 Simulation Clock Generator 给的时钟,结果波形是红 XXXX,换用自己写 tb 给时钟激励就好了。
起初的 axi_interface 中,地址只赋值了低 32 位,在 S_AXI 的地址宽度设置为 49 之后,高位没有赋值,在仿真的时候呈 Z 高阻状态,地址送不过去,ARADDR 是错误的,ARREADY 一直没有拉高,握手失败,因此起初读不到数据;把地址改为全位赋值就好了。
真正开发的时候,ILA 是三思之后再使用的,一般都是先仿真、先仿真、先仿真!要用逻辑分析仪的 synthesis、setup debug、implementation 是及其耗时间的。关于 DDR 的仿真,Verification IP 要 2.0 版本之后才支持自定义存储器内容,老版本的方法是用 BRAM+AXI BRAM Controller 模拟,用 coe 文件写入要初始化的内存。coe 文件是 xilinx 专用的储存初始化文件格式。与 coe 文件类似的还有 mem 文件,mem 是 FPGA 通用的内存初始化文件,但 Vivado2017.4 的 Block Memory Generator 似乎并不支持 mem 文件,所以还是用 coe 文件吧。
目前发现,笔记本上生成比特流之后要导出硬件并且勾选 include bitstream 时会提示报错(不 include 就不会),大体意思是找不到比特流或者找不到 block design;但是同样的工程复制到台式机上就没问题,目前暂不清楚原因。(已经排除过路径中含有空格的问题了,不是这个原因)。
把计算流水线和 valid/ready 的流控逻辑分开写,是一个不错的规范。
一切直接拿来用的模块和 AI 给的代码,都要自己充分从第一性原理弄明白之后再用,而且还不能是那种想当然的理解,一定是充分理解,否则不是可能会出问题,是一定会出问题!
axi interconnect 的所有端口都要连接 axi interface,不然就会握手失败,读不到数据;之前注释掉其它的 axi_interface,只留一个 read xyz 和 axi hp1 读不到数据,就是这个原因。
除法器 IP 在配置为结果以商和余数的形式输出的情况下,出来的低 16 位是余数,剩下的高位才是商。
signed 真正的作用是决定如何对操作数进行位宽扩展,有符号数和无符号数的加法器和乘法器对于硬件电路来说是一样的,区别只在于使用需要扩位时用零填充还是符号位填充。加法和乘法操作前会先对操作数扩位成相同的位宽。在调试 sh2color 模块时,出现了 000A 被扩展成 000A0000000000000000 而不是 0000000000000000000A 的情况,AI 的解释说是有的仿真器会把原数挤到高位去,但其实这个 bug 只在下面这类情况出现,并不是所有的数字都有问题。目前尚不清楚原因,暂时当成仿真器的 bug 吧。解决方法是把每个操作数都用$signed 包裹,说是这样可以显式扩展位宽。
1 2 3 4 5 6 7 8
localparam signed SH_C2_3 = 32'shFFEE8312; reg signed [79:0] sh5_temp; wire signed [15:0] sh5; reg signed [31:0] xz; // 其中xz为0000_0000, sh5为000A, 从数学上结果显然应该是0,但是发现下面这样写会得到000A_0000_0000 sh5_temp <= SH_C2_3 * xz * sh5; // 写成下面这样就好了 sh5_temp <= SH_C2_3 * $signed(xz) * $signed(sh5);
数对不上的时候,先静态检查代码的 valid 信号有没有写错,数据的时序有没有对上,写了一些之后,计算步骤出错的概率远小于 valid 弄错的概率(除非公式自己弄错了,比如 cov2d 手推计算结果推错了啊啊啊啊啊啊),所以先查 valid 信号。
sd 有符号十进制数,sh 有符号十六进制数。
四个 HP 口都打开之后,HP0 读取的 cam 数据会错位 4 拍(m10~m13 读取到的数据是 DDR 中 w2c 矩阵的第一行),但是 xyz 的读取没问题。目前的解决方案是让 cam_valid 作为 xyz 的 ready 信号,也就是强行让 cam 读取完之后再读取 xyz。
fifo 的读写使能需要连接上 full 和 empty 信号
compute_rgb 在改的时候遇到两个问题,一是 fifo 的深度需要设置 32 才能不漏后面的数据,通过看 data count 发现的;另一个是 xyz 和 sh 没有对上导致只有第一次的三个结果是对的,后面的 rgb 的前一组 sh 用的是上一组的 y。后来又发现了一次深度不够导致只有第一个 burst 的三个高斯的数据正确以及第二个 burst 的第一个高斯数据正确,后面全乱了,fifo 深度改到 64 就对了。
仿真里 fifo 深度够用,实际板子上不一定,目前看来,仿真里的 AXI 似乎模拟不了和实际硬件的握手过程,因此数据来的会快一些。实际板子上会花费几排用来握手,这个期间的数据如果超过了 fifo 深度,后面就全乱了。所以目前在追求完成度的情况下,仿真正确而板子数据错位的时候,先检查一下 fifo 的 data_count,多半都是 fifo 深度不够导致的。
fifo 中 rd_en 拉高表示切下一组数据,需要 fifo_valid 且上一个计算步骤出结果之后拉高。
仿真是可以仿真出 IP 中设置的 latency 的,只有器件延迟是仿真不出来的,所谓器件延迟,指的是经过一个门电路延迟多少,这种无法仿真,但是正常的 reg 和 always 块赋值,以及 ip 中的这种 latency 配置,是可以仿真的。(不要眼瞎看别的波形上去呜呜呜)。
多位数除法,一拍算完,时序大概率是会出问题的,在还没有设置时序约束的情况下,可以给 6~7 的 lantency,大概率能跑,但是后面是一定要认真研究时序约束的东西的,真正上板子用起来的时候,是一定需要做时序约束的,不然就只能是每次碰运气,可能这次恰好能布出一个能用的电路,下次换个板子换个代码写法,可能就不行了。
数据线不用进行复位和使能赋值,这会增加额外的硬件负担,没有必要。当然,累加器是需要清零的。
不管做过任何改动,跑综合和实现之前,一定一定一定先跑一遍仿真看没问题了,再上板子,因为综合和实现跑一遍的时间成本真的太高了,所以无论改啥了,都先仿真!
来自知乎的建议:dcdc 的手册一定要读,否则分配信号容易错 bank。第一次设计一定要想着参数化或者触发式,不要写数值做时序。一次错会次次错,以后就转换不过来思路了。工具一定要选好,我是 sublime+iverilog+插件,一键整理格式排版,强迫症特别舒服。selectio 手册 clocking resource 一定要看。能用 xpm 和原语就用,别 ip catalog。过手一个项目源码就要搞透所有模块。
现在设计中用的 fifo,全都是首字直通模式,改成 standard FIFO 会出现问题;在配置 fifo 的时候要记得选成首字直通。
vitis 中报找不到头文件,到 BSP 界面 regenerate BSP,然后重新打开文件就好了。
new example 之后,hellowolrd.c 改文件名之后,要全局搜索 hellowolrd.c 并相应替换,这一步是将 cmake 编译链中的 hellowolrd 换掉,因为 vitis 中这些文件不会随着重命名文件自动更新。
在 FIFO 配置为 FWFT 首字预取时,valid 信号表示数据有效,并不是非空就行的。wr_en 有效后会立即反映在 data_count 上,但 fifo_valid 信号需要在两个时钟周期之后才有效。
端序只在字节解释成数值时才有意义,即需要先确定以什么类型解释这段内存。
因为 DDR 只有一个口,所以要保证各个读请求和写请求分别的互斥。不然会出现诸如在 rd_req3 发起的时候,rd_data3 数据线上出现的是 rd_data1 的数据。
Xilinx 官方推荐使用同步高电平复位,复位尽量是局部复位而不要全局复位。异步复位会导致 BRAM 和 DSP 资源跑不快。改成同步复位之后,由于除法和根号的 IP 用的是 AXI-Stream 的接口,需要启用 aresetn 信号并接入 rstn,否则在仿真里会无驱动,实际板子没试过。
时钟结构一般是 MMCM 调幅+PLL 调相,PLL 调相信号可以作为局部复位。
计数器位数不要大于 16 位。
一个 always 块最好只写一个寄存器的赋值。
自保持用时序逻辑而不是组合逻辑,否则会综合出锁存器。锁存器的坏处在于时序敏感,有毛刺,容易出现误动作。
PL 和 PS 的 DDR 之间横亘着 DCache,PL 从 PS 读取需要先 Xil_DCacheFlushRange,PS 打印 PL 写进来的数据需要先 Xil_DCacheInvalidateRange。
代码的逻辑级数不要过高,一般一级 LUT 就是一个逻辑等级。
跨时钟域(CDC)直接赋值会导致亚稳态问题,不能保证每次赋值都是正确的。处理方式有:电平同步器、脉冲同步器、FIFO/RAM。设计的模块包括复位处理模块(比如异步复位同步释放)、慢到快同步器、快到慢同步器、双沿检测器。同步器用打两拍的方式实现,这是概率上的处理方式,根据乘法原理,打两拍会使得亚稳态的概率会大大降低。(_ ASYNC_REG = “TRUE” _)用于声明寄存器能够接收相对于时钟源的异步数据,或者说寄存器是一个同步链路上正在同步的寄存器。
模块输入的输出分别以 i 和 o 开头,这样在例化的时候不用翻模块源码就知道哪些输入哪些输出。
从 CUDA 中保存数据到 txt 时记得把测试集的渲染注释掉,不然相机视角对不上全乱了。
一个, v 文件的代码模板可以分为参数、状态机、寄存器、网表型、组合逻辑、例化、进程。
RAM 中 inst 的再下一级中,能够找到
memory[0:255][0:15]这个寄存器组,可以通过这个来查看其中每个寄存器地址的值。每次从 github 仓库拉下来之后,要 reset 并重新 generate 一些两个 block design,不然仿真会报警告说有同名 IP 但是不同内容,以及综合会失败(因为没有 gen 那个目录)。
加法器有行波进位加法器、超前进位加法器、线性进位选择加法器。
在数字电路设计中,关键路径(Critical Path) 是指从输入到输出的所有信号传输路径中,延迟最大的路径,其延迟时间直接决定了整个电路的最高工作频率。
Module 的输出尽量为 reg 输出;同一条组合路径中的代码放在一个 module 中描述;“时序要求严格的关键路径逻辑” 和 “时序要求宽松的非关键路径逻辑”,分到不同的 module 里。
各个功能段所需时间应尽量相等,否则时间长的段会成为瓶颈,造成流水线堵塞或断流。
Verilog 还支持其他编程语言接口(PLI)进行进一步扩展,PLI 允许外部函数访问 Verilog 模块内部信息。PLI 是 Verilog 提供的一套接口规范,让 Verilog 仿真器在运行时,去调用外部用 C/C++ 写的程序,这些程序还能反过来读取 / 修改 Verilog 里的信号和模块。不过华为的开发规范中要求不使用 PLI 函数。
Verilog 是硬件描述语言,在有一定熟练度之后,写之前最好是先设计好电路大概长什么样(到加法器、ram、fifo 这个 hier 就可以),然后再用 verilog 实现。另外,Verilog 开发遵循自顶向下的模块化设计,模块划分要功能单一,且要留出使能、复位等接口以便系统搭建。有可能的话,把握编译器的理解方式也有助于开发,写出编译器能清晰理解的代码可以大大降低错误率。
一个 always 块可以看作一个电路或者实物上的一个芯片。
非阻塞赋值在触发时是同时赋值的,很符合触发器在上升沿到来后将 D 输出到 Q 的实际情况。时序 always 块中左侧变量被综合成触发器,右侧的表达式用逻辑电路实现后连接到触发器的 D 端。与 if 复位配对的 else if 中的变量会被综合成使能信号。
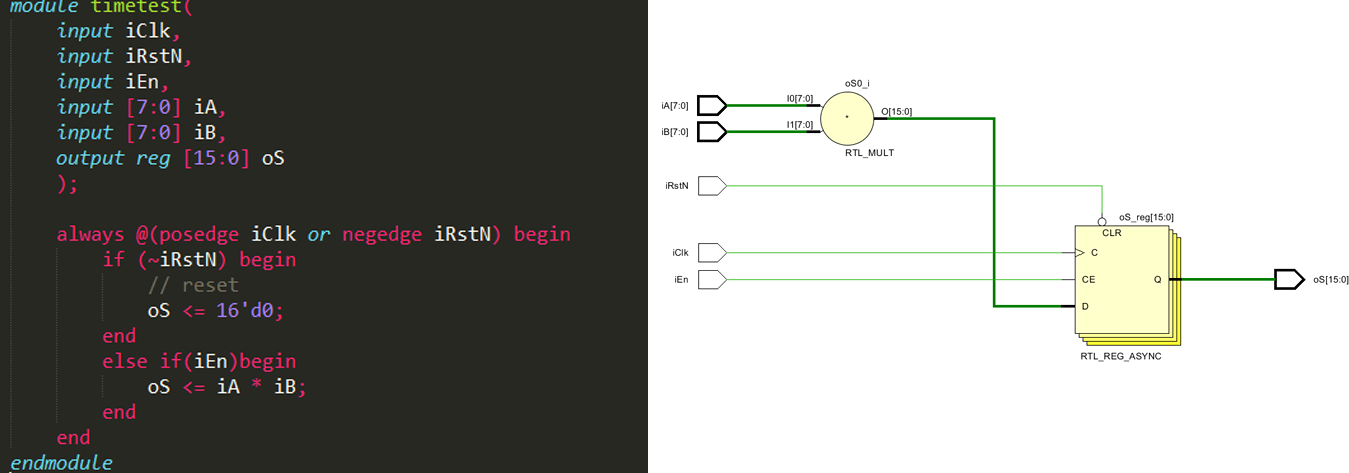
相较于 case,if else if 是有优先级的,会综合出多个 MUX2 来实现。
组合逻辑如果有分支没有输出则会综合出锁存器,因为没有时钟但是又需要存储的功能。锁存器会占用大量资源且时序上不稳定。
模块输入端口命名以 i 开头,输出端口以 o 开头,这样在例化时输入输出一目了然。
if 中不要省略条件,不写 if(a),写成 if(a == 1’b1)
关于复位,数据路径不需要复位逻辑,因为其正确性会由伴随的控制信号保障,加上复位没有必要反而会增加硬件负担。其它信号推荐设计成局部复位。
一般情况下信号变量不要直接使用乘法 *、除法 /、求余数 % 等操作。这些操作符被综合后,结构和时序往往不易控制。应该使用相关优化后的 ip 模块或工艺库中的集成模块。但是 parameter 类型的常量就可以使用此类操作符,因为在编译之初编译器就会计算出常量运算的结果,不会消耗多余的硬件资源。
参考资料
建模篇
建模强调的思想是,用 Verilog 去建立清晰可理解的硬件结构,模块是始终运行的硬件,顺序仅存在于观察结果而不是结构本身。在实现上,一个模块只允许承担一个功能。功能模块只干具体的事,控制模块只负责调度,组合模块只负责拼装,它们之间的关系必须通过结构本身一眼就能看出来,而不是靠注释解释。建立了正确的建模直觉,后续的接口封装、系统组合、高级抽象都会变得顺理成章。你是否真的知道自己在描述什么硬件资源,你的设计是否能被画成结构图,你的模块是否在并行地、各司其职地运行。先拆、再分、再并行、再封装、最后组合成系统。
功能模块 = 自己知道“怎么做”,但不知道“什么时候做”;控制模块 = 自己知道“什么时候做”,但不知道“具体怎么做”。
- 功能模块是一种高度自洽的、近似“硬件器件”的存在。它的最大特点是:只要输入条件满足,它就自然地、持续地工作,而不需要外部有人一步一步指挥。功能模块通常具备自己的时序、自己的计数器、自己的寄存器状态,但这些状态都是为了完成“它这一件事”,而不是为了配合系统流程。它们的行为可以脱离“系统上下文”而存在。从设计风格上看,功能模块往往是“条件驱动”的,而不是“步骤驱动”的。也就是说,它更像是在回答:“当某个条件成立时,我该输出什么”,而不是:“现在轮到我做第几步了”。
- 控制模块更像一个时序协调者、流程调度者,最大的特征是:它本身不干具体活,它只决定谁在什么时候该干活。控制模块关心的不是“这个模块内部怎么算”,而是“它什么时候开始”“它什么时候结束”“下一个该谁上”。因此,控制模块往往非常依赖外部模块的反馈信号,比如 done、busy、valid、ready 一类信号。从结构上看,控制模块通常是“强顺序感”的,是可以合理使用状态机思维的地方。控制模块只负责状态切换和调度决策,而不会把具体的功能逻辑塞进去。
顺序操作有步骤的概念,前后行为具有依赖关系;并行操作则是独立执行互不影响,各自在固定的时间执行操作。顺序操作的语言很多都是高级语言,一些调用的指令都是被隐性处理,如函数的调用指令和返回指令等。
低级建模讲究资源的分类,分为功能模块、控制模块、组合模块,一个完整的系统都是由这三种基本资源模块组合再组合。一个功能模块仅有一个功能,模块之间以连线表达关系 ,功能过多会使得图形绘制更加复杂。
晶振频率 50MHz,1 秒 50M 个时钟周期,即计数器从 0 计数到 50M-1 时表示过去了一秒。根据计数器的值对应改寄存器的值,再用这些寄存器驱动 LED,就可以实现各种花式点灯。
电平检测同样也是利用计数器计时,100us 延迟 isEn 用于过滤复位时电平不稳定的状态。两级寄存器用于检测电平变化,最后 assign H2L_Sig = isEn ? (H2L_F2 & !H2L_F1) : 1'b0 就可以检测下降沿了。10ms 延迟模块采用了仿顺序操作写法,用 i 寄存器控制执行的步骤,根据 H2L_Sig 或 L2H_Sig 进入不同的步骤,步骤内检测 10ms 标志位并进行对应操作即可。这个寄存器 i 的仿顺序写法,其实就是状态机。
所谓的控制模块,就是用来产生 enable 信号的模块,其它功能模块中加入使能信号的设计,这样就可以由控制模块来调度功能模块。同时,功能模块起到沟通协调的作用,可以灵活调整,以接收各种功能模块的输入,产生各种功能的使能信号,保证了可扩展性。
这些外设的编写逻辑,其实都是晶振脉冲计时输出标志位,然后状态机根据计时标志位进行状态转换和相应动作。
SMG 码/段选码/七段码是数码管的段码,行扫描和列扫描,其实就是根据计时标志位,使能不同的数码管并将对应的段码寄存器输出。
PS2 是一种老式的人机输入接口协议,最典型的用途是:键盘、鼠标。PS/2(Personal System/2)接口 / 协议,最早是 IBM 给 PC 键盘和鼠标设计的通信接口。不是 USB 或 UART,是单独的一个同步串行通信协议。PS2 协议对数据的读取是“Clock 的下降沿”有效。PS2 时钟的频率比较慢,大约是 10Khz 左右。所有拥有 PS2 接口的设备,一般上都是“低速”设备。PS2 的一帧是 11 位,开始位 1 位+数据位 8 位+检验位 1 位+结束位 1 位。PS 键盘的解码,也是寄存器 i 这个仿顺序写法,用 i 控制步骤。
采样和被采样的频率如果相差越大,采样方可执行的空余的时间就越多,在设计上就越轻松。 键盘的编码有“通码”( Make)和“断码”( Break)之分。看得简单一点就是,“通码”是某按键的“按下事件”,“ 断码”是某按键的“释放事件”。编码键盘还有一个老规则,就是一次只能有一个输出 (多个按键同时按下,只有其中一个有效)。编码键盘虽然很方便,但是在两个键同时按下的时候,仅有按下最迟的一方才有输出的权利。相反独立按键是完全“并行”执行, 不会出现对输出争先恐后的事件。独立键盘是指每一个按键,都有一根独立的信号线,互不影响,可同时被检测。编码键盘是多个按键共享线路,通过“编码 / 扫描”的方式来识别按下的是哪一个键,比如行列扫描的矩阵键盘,串行输出的 PS2、I2C、USB 键盘。在矩阵键盘中,如果没有二极管,就存在键冲突的问题,同时按三个键就可能冒出一个不存在的键。日常生活中用的绝大部分都是编码键盘,独立键盘只有在工业控制、安全相关按键等特殊工况场景下使用。
VGA 驱动分为 VGA 硬件接口和 VGA 协议,硬件接口没什么好说的,主要是协议。VGA 协议主要由 HSYNC Signal, VSYNC Signal, RGB Signal 五个信号组成,前两个分别是列和行的(以扫描方向命名,Horizontal Sync 是一行扫描的同步,列号变化;Vertical Sync 是一帧所有行扫描的同步,行号变化)HSYNC 控制列填充,指示一行扫描的边界。控制换行;VSYNC 控制行扫描,指示一帧扫描的边界,控制换帧。填充/扫描是显示控制器的工作,同步信号是节拍标志,不是控制信号。
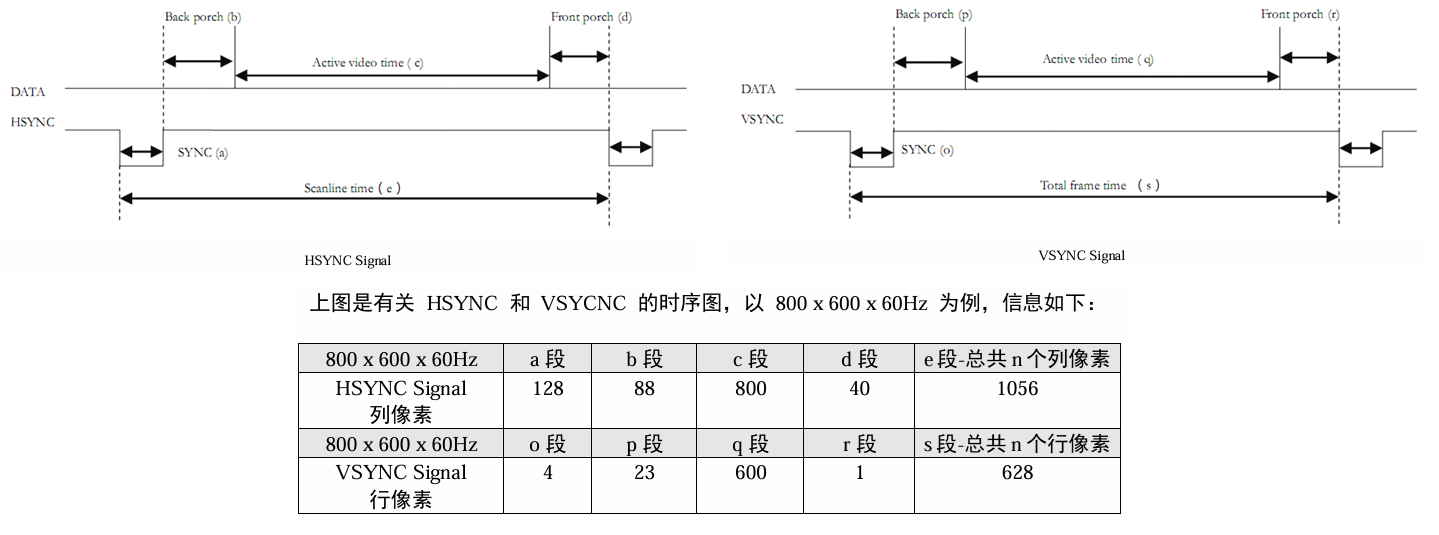
VGA 的扫描是固定的,一帧的屏幕由 m 行扫描和 n 列填充组成,扫描次序为从左到右、从上到下。在显示时序里,像素只存在于水平方向,以像素时钟为单位;垂直方向的单位是行,以行数为单位。
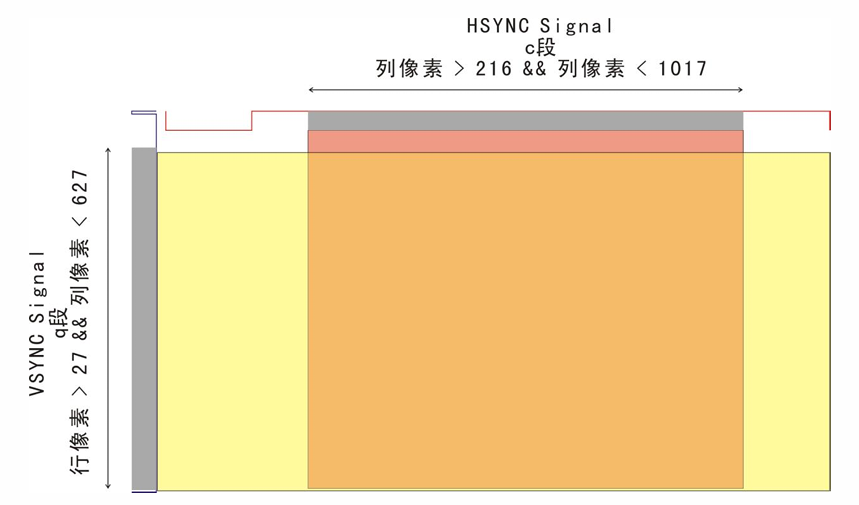
如果要驱动 VGA 为 800 x 600 x 60Hz 显示标准,1056 x 628 x 60 = 39,790,080,至少需要 40MHz 的时钟频率,一个时钟周期为 25ns。
模块设计上,分为 PLL 模块、同步模块和 VGA 控制模块。PLL 模块输出时钟信号;同步模块向外输出同步信号、并输出行列地址以及是否在有效区域内三个信号给 VGA 控制模块,VGA 控制模块接收这三个信号并输出 RGB 信号。同步模块根据计数器的值和显示标准给对应寄存器赋值即可。VGA 控制模块根据接收到的行列地址和准备的数据给 RGB 信号赋值即可。
点阵编码的方式是“逐行式”+“高位在前”。“ 逐行式”也就是逐行扫描的意思。LED 点阵的扫描次序可以完全自定义,点阵编码方式也是用户自定义的,直接使用 VGA 的扫描次序也可以。

驱动点阵可以拆分成上面的 VGA 驱动+ROM 存储图案即可,而与 ROM 的交互只需要根据控制模块给出的像素地址在 ROM 中寻址即可。如果图片是 16x16 像素,那么很建议在 vga 控制模块里定义图片每一行信息的常量。如果图片是超过这样 16 x 16 像素,那么还是建立一个 rom 来存放图片信息。不要像 C 语言那样,建立一个库文件,然后调用。Verilog HDL 语言不适合这一套。如果要显示动画,需要引入帧的概念,在 ROM 中存储多幅图片,通过帧偏移来索引到不同帧的图片。每次更换图片就加上这个帧偏移量。
串口通讯在传统的单片机串口实验中一般都是堆寄存器进行配置和查询。使用 Verilog 对串口建模可以从底层窥探传输期间的所有细节。串口传输的时序如下。串口传输数据“从最低位开始, 到最高位结束”。
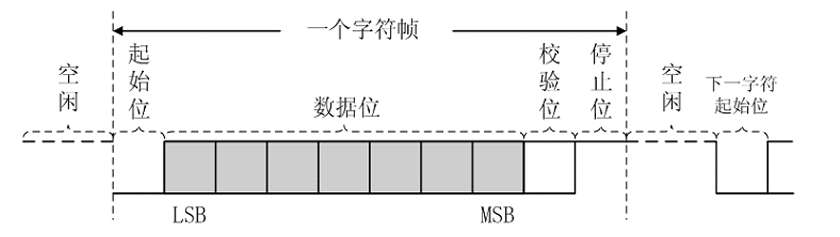
串口总线上,高电平是默认的状态,一帧数据的开始需要先拉低电平,这就是第 0 位的作用。串口中的波特率从宏观上来说代表传输速率,在微观上其实是传输中一个位的周期,即一个位逗留的时间。由此可以算出一秒可以传输的理论帧数。串口接收,本质上就是采样的操作。
串口接收在模块划分上分为电平检测模块、波特率定时模块和控制接收模块。电平检测模块与前述一致,检测下降沿。波特率定时模块负责根据设置的波特率设置计数阈值,根据计数器寄存器的值在数据中间产生采样的采集脉冲。控制接收模块根据输入的信号按仿顺序写法的状态机产生对应信号。
串口发送在模块划分上分为波特率定时模块和发送控制模块。波特率定时模块负责根据设置的波特率设置计数阈值,根据计数器寄存器的值产生定时发送的脉冲。控制发送模块根据输入的信号按仿顺序写法的状态机产生对应信号。
仿顺序操作的模块构造有标志性的 start sig 和 done sig,已经控制执行步骤的 i 出现。
if else if 综合出的每一个选择器都需要一个“默认状态”,如果没有添加这一行,会出现很多编译警告。选择器在组合模块中很多时候是必要的,因为仿顺序操作的模块有时会多个模块使用同一个输出,需要选通一个模块输出。
ST7565P 液晶(LCD)驱动(128*64)是一块点阵屏,CGRAM 是显存,保存了点的亮灭情况。扫描次序解释了液晶是按什么顺序把 CGRAM 里的点显示到屏幕上的。64 高 128 宽的屏幕空间由芯片分为 8 个 8 高 128 宽的页,扫描次序与四个命令有关系,0xA0 是从左向右进行列填充,0xA1 是从右向左进行列填充;0xC0 是从下到上进行页扫描,0xC8 是从上到下进行页扫描。无论从上到下还是从下到上,每一页的列填充都是低位开始高位结束。一页是由一个字节数据,列填充 128 次组成。

CGRAM 的建立不是 8 page x 8 bits x 128 words 那么完美的,虽然说完成一次列填充,列地址会自动递增,然而 ST7565P 对于列地址的控制显得很笨蛋。 每一次完成 128 次的列填充,就要手动“重新设置列起始地址和下一个页地址”。关于设置页地址的命令很简单,就是 0xb?。其中“?”就是页地址的设置处。假设输入 0xb0, 也就是页地址 0。 关于设置列地址的命令是 0x1?, 和 0x0?。命令 0x1?的“ ?”是列地址的“高四位”,而 0x0?的“?”是列地址的“低四位”。假设输入 0x10, 0x00, 也就是说列地址是 8’b0000_0000, 亦即 0。
对于串行模式的液晶来说,重要的引脚有 P/S,CS,A0,DB6(SCL)和 DB7(SI)而已。ST7565P 芯片可以支持 3 种传输模式,当然最简单的传输模式还是 SPI 模式,控制“传输模式的引脚”就是 P/S 。 当 P/S 被拉低时就是表示“串行传输模式”。 CS 是使能信号(低电平有效)。A0 是命令或者数据决定信号(0 = 命令,1 = 数据 )。 SCL 是串行时钟信号,SI 是串行输入信号。在 SPI 传输中有分为主机和从机之分。主机的定义是有 CS 使能权,产生串行时钟;反之从机的定义是 CS 被使能,接收串行时钟。SPI 传输是从最高位开始,最低位结束。
这里只需要主机(FPGA)向从机(液晶资源)写数据,SI 端,SCL 端和 CS 端都是由主机输出,从机输入(液晶读入数据)。从机读取(锁存)数据都是 CS 被拉低,并且发生在 SCL 信号的上升沿。

SPI 设备在传输都有一个规则,SCL 时钟信号在“上升沿”的时候是“锁存数据”, SCL 时钟信号在“下降沿”是“设置数据”。在这里我们 SPI 主机(FPGA),写操作要干的工作就是在“拉高 SCL 时钟信号之前”设置数据(移位数据),设置数据之后,再拉高时钟信号。
SPI 发送模块接收 10 位的 SPI 原始数据,输出 4 位的信号位,分别为 CS/A0/SCL/SI。以计时标志位定时拉高或拉低 SCL 信号产生主机时钟,然后根据 SPI 的传输规范对应在下降沿设置数据,上升沿锁存数据即可。
为了配合 CGRAM 的分配方式,存储在 ROM 中的图片数据也可以采用 8 pages x 8 bits x 128 words 的组织方式。
命令式的仿顺序操作,本质上就是把 start sig 变成多位,然后不同的值用 case 启动不同的仿顺序操作罢了。
DS1302 是一个“实时时钟芯片(RTC)”,专门用来计时、记日期,就算单片机断电,它也不会忘。RTC 的关键在于传输时序和芯片本身的寄存器分配。DS1302 的读写时序如下,写时序中,第一个字节是“访问寄存器的地址”,第二字节是 “写数据”。在写操作的时候,都是“上升沿有效”,然而还有一个条件,就是 CE(/RST) 信号必须拉高。(数据都是从 LSB 开始发送,亦即是最低位开始至最高位结束)。读操作和写操作的时序图大同小异,区别的地方就是在第二个字节时“读数据”的动作。第二字节读数据开始时,SCLK 信号都是“下 降沿有效”。CE(/RST)信号同样是必须拉高。(第一节数据是从 LSB 开始 输出,第二节数据是从 LSB 开始读入)

在时序图中,第一个字节都是“访问寄存器的地址”,这一字节数据有自己的格式。BIT 7 固定。BIT 6 表示是访问寄存器本身,还是访问 RAM 空间。BIT 5 .. 1 表示是寄存器或 RAM 空间的地址。BIT 0 表示是访问寄存器本身是写操作,还是读操作。芯片中每一个寄存器的配置查阅芯片资料可得。
操作 RTC 的模块这里使用所谓的命令式仿顺序操作,拆分成命令控制模块和函数模块,函数模块中包含写字节函数和读字节函数两个函数。两个函数同样用状态机构建,根据 2bit 的 start sig 的值选择运行哪一个函数,即进入哪一个状态机。命令控制模块根据输入的高位 start sig,控制运行哪一个函数即可。
一个 IO 口的硬件设计如下,如果要使 IO 输出,isOut 必须拉高,同时间 Data_Out 的数据就会输出。如果要使 IO 为输入,这时候需要拉低 isOut,然而三态门会输出高阻 态将“输出”载止 , 从 IO 口输入的数据就会经向 Data_In。assign IO = isOut ? Data_Out : 1'bz; 和 assign Data_In = IO;
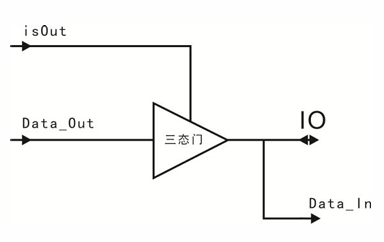
仿顺序操作的本质是时间点,即各个模块在规定的时间点进行相应的运行。
在针对某一个硬件资源的封装之前,不同的硬件资源有不同的考虑。比如开发板上有五个独立按键,需要考虑的问题包括:按键的功能(按下消抖、按下产生脉冲、释放消抖)、按键的数目。在单个按键模块齐备了所有的按键功能后,实例化五个模块并封装成 interface 就完成了针对开发板的按键资源封装。
PWM 占空比的调节从实现上说,一个寄存器保存计数器的值,另一个保存高电平阈值,两个寄存器的值比较输出高低电平就是 PWM 波了,改变高电平时间的阈值即可调节占空比。
多加一级寄存器打一拍可以有效消除输出的毛刺。
对基础的封装,定义为某个基础的最后建模工作,以及封装过后的模块具有独立性。
FIFO 是特殊的双口 RAM,先入先出,没有地址,可同时读写。在前面的设计中,当一个下层模块被使能后,上层模块必须等待下层模块完成工作才能执行下一个操作。为了消除这个依赖关系,引入了 FIFO 来将操作信息缓冲到 FIFO 中,摆脱反馈的束缚。下层模块完成内部工作后,可以直接从 FIFO 中读取操作信息而不用等待上层模块等到下层反馈后下达新的指令。事实上,FIFO 是用来缓冲两个时钟域不同的访问,可以利用 FIFO 这个仓库作为接口的输入,使得接口具备独立性。上层模块调用某个接口时,只需要把信息写入仓库即可,上层模块不用与接口互动而被束缚,如果发现仓库有信息则处理即可。
完整来说应该是,对于接收上游模块指令的模块,可以在最初环节之前引入 FIFO,而对于向下游模块发出指令的模块,可以在最后环节之后引入 FIFO,使得封装之后的接口具有独立性。不过理论上说,基本上所有模块都需要接收上游指令并向下游模块发出指令,所以在最开头还是最末尾引入 FIFO 也是相对的,还是根据具体需求来设计。

这样,上层模块只管往 FIFO 中写入操作信息,不用等待下层模块的反馈信息就可以执行其它操作。控制模块接收到反馈模块后再从 FIFO 读取信息。
VGA 模块的封装,将 VGA 模块内部由 ROM 提供图像,改为由外部提供,存储到 RAM 中,即利用 RAM 成为独立化的接口。
LCD 的封装和 VGA 的封装原理上一样,不同的只是液晶显示驱动的方法而已。
对 RTC 接口的封装,DS1302 芯片本身已经做好了驱动的工作,封装需要完成配置的工作。
一个简单的系统可以由几个接口和控制模块建立而成。
SystemVerilog:功能仿真和验证,系统级的硬件描述语言
时序分析:寄存器级的世界
NIOS II:软核
补充
吞吐量 thoughput 指的是,IP 在稳定工作时,每个时钟周期能够处理或输出的数据量,比如,如果 IP 每个 clock 都能输出一个新的除法结果 → 吞吐量 = 1 result/cycle,如果要每 4 个 clock 才能输出一个结果 → 吞吐量 = 1/4 result/cycle。延迟 latency 指的是,从输入有效到得到第一个结果需要的周期数,在流水线的设计中,即使 latency 很大(比如几十个周期),只要 pipeline 深度够大,throughput 可以依旧是 1 个结果/周期。non-blocking 指的是,一个通道的数据缺失不会导致另一个通道的数据被缓存。另外,non-blocking 不支持背压,因为这个模式没有 tready 信号。
溢出限制:真正工作起来应该是选择合适的位宽使得不会溢出,而不是靠溢出保护来避免异常值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
localparam signed [15:0] MAX_16 = 16'sd32767;
localparam signed [15:0] MIN_16 = -16'sd32768;
localparam signed [31:0] MAX16_TH = , MAX_16};
localparam signed [31:0] MIN16_TH = , MIN_16};
always @ (posedge clk or negedge rstn) begin
if (!rstn) begin
x_w2c <= 0;
y_w2c <= 0;
z_w2c <= 0;
end
else if (valid_d3) begin
x_w2c <= (rx > MAX16_TH) ? 16'h7FFF : ((rx < MIN16_TH) ? 16'h8000 : rx[15:0]);
y_w2c <= (ry > MAX16_TH) ? 16'h7FFF : ((ry < MIN16_TH) ? 16'h8000 : ry[15:0]);
z_w2c <= (rz > MAX16_TH) ? 16'h7FFF : ((rz < MIN16_TH) ? 16'h8000 : rz[15:0]);
end
end
慢到快的跨时钟域传输:相对简单,一般采用延迟打拍法,或延迟采样法。
最常用的同步方法是双级触发器缓存法,俗称延迟打拍法。异步信号从一个时钟域进入另一个时钟域之前,将该信号用两级触发器连续缓存两次,可有效降低因为时序不满足而导致的亚稳态问题。一般设计中使用两级触发器进行缓存即可满足设计时序需求。大量实验表明,三级触发器缓存可解决 99% 以上的此类异步时序问题。
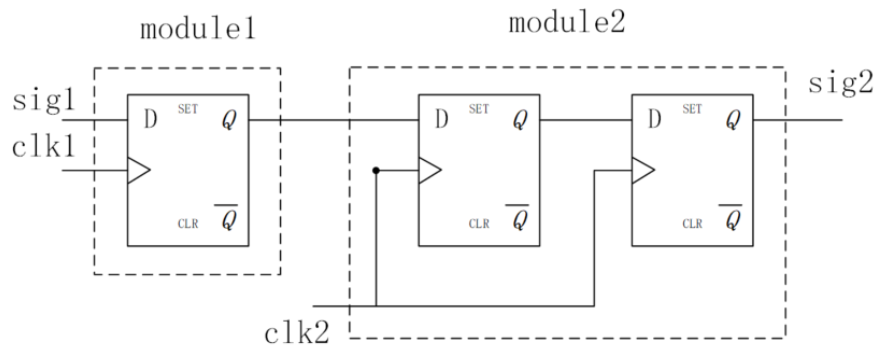
1
2
3
4
5
6
7
8
9
10
11
12
13
14
module delay_clap(
input clk1, //异步慢时钟
input sig1, //异步信号
input rstn, //复位信号
input clk2, //目的快时钟域时钟
output sig2); //快时钟域同步后的信号
reg [2:0] sig2_r ; //3级缓存,前两级用于同步,后两节用于边沿检测
always @(posedge clk2 or negedge rstn) begin
if (!rstn) sig2_r <= 3'b0 ;
else sig2_r <= {sig2_r[1:0], sig1} ; //缓存
end
assign sig2 = sig2_r[1] && !sig2_r[2] ; //上升沿检测
延迟采样法主要针对多位宽的数据传输。例如当两个异步时钟频率比为 5 时,可以先用延迟打拍的方法对数据使能信号进行 2 级打拍缓存,然后再在快时钟域对慢时钟域的数据信号进行采集。该方法的基本思想是保证信号被安全采集的时刻,而不用同步多位宽的数据信号,可节省部分硬件资源。利用打拍的方法进行延迟采样的 Verilog 描述如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
//同步模块工作时钟为 100MHz 的模块
//异步数据对来自工作时钟为 20MHz 的模块
module delay_sample(
input rstn,
input clk1,
input [31:0] din,
input din_en,
input clk2,
output [31:0] dout,
output dout_en);
//sync din_en
reg [2:0] din_en_r ;
always @(posedge clk2 or negedge rstn) begin
if (!rstn) din_en_r <= 3'b0 ;
else din_en_r <= {din_en_r[1:0], din_en} ;
end
wire din_en_pos = din_en_r[1] && !din_en_r[2] ;
//sync data
reg [31:0] dout_r ;
reg dout_en_r ;
always @(posedge clk2 or negedge rstn) begin
if (!rstn)
dout_r <= 'b0 ;
else if (din_en_pos)
dout_r <= din ;
end
//dout_en delay
always @(posedge clk2 or negedge rstn) begin
if (!rstn) dout_en_r <= 1'b0 ;
else dout_en_r <= din_en_pos ;
end
assign dout = dout_r ;
assign dout_en = dout_en_r ;
endmodule
快到慢的跨时钟域同步:需要根据信号的特点来进行同步处理。对于单 bit 信号,一般可按电平信号和脉冲信号来区分。
电平信号:同步逻辑设计中,电平信号是指长时间保持不变的信号。保持不变的时间限定是相对于慢时钟而言的。只要快时钟的信号保持高电平或低电平的时间足够长,以至于能被慢时钟在满足时序约束的条件下采集到,就可以认为该信号为电平信号。既然电平信号能够被安全的采集到,所以从快时钟域到慢时钟域的电平信号也采用延迟打拍的方法做同步。
脉冲信号:同步逻辑设计中,脉冲信号是指从快时钟域输出的有效宽度小于慢时钟周期的信号。如果慢时钟域直接去采集这种窄脉冲信号,有可能会漏掉。
假如这种脉冲信号脉宽都是一致的,在知道两个时钟频率比的情况下,可以采用”快时钟域脉宽扩展+慢时钟域延迟打拍”的方法进行同步。
如果有时窄脉冲信号又表现出电平信号的特点,即有时信号的有效宽度大于慢时钟周期而能被慢时钟采集到,那么对此类信号再进行脉冲扩展显然是不经济的。此时,可通过”握手传输”的方法进行同步。
假设脉冲信号的高电平期间为有效信号期间,其基本原理如下。(1) 快时钟域对脉冲信号进行检测,检测为高电平时输出高电平信号 pulse_fast_r。或者快时钟域输出高电平信号时,不要急于将信号拉低,先保持输出信号为高电平状态。(2) 慢时钟域对快时钟域的信号 pulse_fast_r 进行延迟打拍采样。因为此时的脉冲信号被快时钟域保持拉高状态,延迟打拍肯定会采集到该信号。(3) 慢时钟域确认采样得到高电平信号 pulse_fast2s_r 后,再反馈给快时钟域。(4) 快时钟域对反馈信号 pulse_fast2s_r 进行延迟打拍采样。如果检测到反馈信号为高电平,证明慢时钟域已经接收到有效的高电平信号。如果此时快时钟域自身逻辑不再要求脉冲信号为高电平状态,拉低快时钟域的脉冲信号即可。此方法实质是通过相互握手的方式对窄脉冲信号进行脉宽扩展。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
//同步模块工作时钟大约为 25MHz 的模块
//异步数据对来自工作时钟为 100MHz 的模块
module pulse_syn_fast2s
#( parameter PULSE_INIT = 1'b0
)
(
input rstn,
input clk_fast,
input pulse_fast,
input clk_slow,
output pulse_slow);
wire clear_n ;
reg pulse_fast_r ;
/**************** fast clk ***************/
//(1) 快时钟域检测到脉冲信号时,不急于将脉冲信号拉低
always@(posedge clk_fast or negedge rstn) begin
if (!rstn)
pulse_fast_r <= PULSE_INIT ;
else if (!clear_n)
pulse_fast_r <= 1'b0 ;
else if (pulse_fast)
pulse_fast_r <= 1'b1 ;
end
reg [1:0] pulse_fast2s_r ;
/************ slow clk *************/
//(2) 慢时钟域对信号进行延迟打拍采样
always@(posedge clk_slow or negedge rstn) begin
if (!rstn)
pulse_fast2s_r <= 3'b0 ;
else
pulse_fast2s_r <= {pulse_fast2s_r[0], pulse_fast_r} ;
end
assign pulse_slow = pulse_fast2s_r[1] ;
reg [1:0] pulse_slow2f_r ;
/********* feedback for slow clk to fast clk *******/
//(3) 对反馈信号进行延迟打拍采样
always@(posedge clk_fast or negedge rstn) begin
if (!rstn)
pulse_slow2f_r <= 1'b0 ;
else
pulse_slow2f_r <= {pulse_slow2f_r[0], pulse_slow} ;
end
//控制快时钟域脉冲信号拉低
assign clear_n = ~(!pulse_fast && pulse_slow2f_r[1]) ;
endmodule
当多位宽数据进行同步时,如果该数据各 bit 位都可以看作电平信号,即相对一段时间内各 bit 位数据均可以保持不变以至于能被慢时钟采集到,可以消耗一些触发器资源对多位宽数据进行简单的延迟打拍同步。但如果数据变化速率过快,就不能再使用延迟打拍采样的方法。因为此时数据各 bit 位不再是电平信号,变化的时间也参差不齐,用异步时钟进行打拍采样,可能会采集到因路径延迟不同而导致的错误数据。解决此类异步问题的常用方法是采用异步 FIFO (First In First Out)。
FIFO(First In First Out)是异步数据传输时经常使用的存储器。该存储器的特点是数据先进先出(后进后出)。其实,多位宽数据的异步传输问题,无论是从快时钟到慢时钟域,还是从慢时钟到快时钟域,都可以使用 FIFO 处理。FIFO使用现成的IP即可,没有到大后期都不建议自己实现。
为确保系统上电后有一个明确、稳定的初始状态,或系统运行状态紊乱时可以恢复到正常的初始状态,数字系统设计中一定要有复位电路模块。复位电路异常可能会导致整个系统的功能异常,所以在一定程度上,复位电路的重要性也不亚于时钟电路。复位电路可分类为同步复位和异步复位。
同步复位
1
2
3
4
5
6
7
8
9
10
11
12
13
module sync_reset(
input rstn, //同步复位信号
input clk, //时钟
input din, //输入数据
output reg dout //输出数据
);
always @(posedge clk) begin //复位信号不要加入到敏感列表中
if(!rstn) dout <= 1'b0 ; //rstn 信号与时钟 clk 同步
else dout <= din ;
end
endmodule
对于没有同步复位端的寄存器,会综合出以下电路
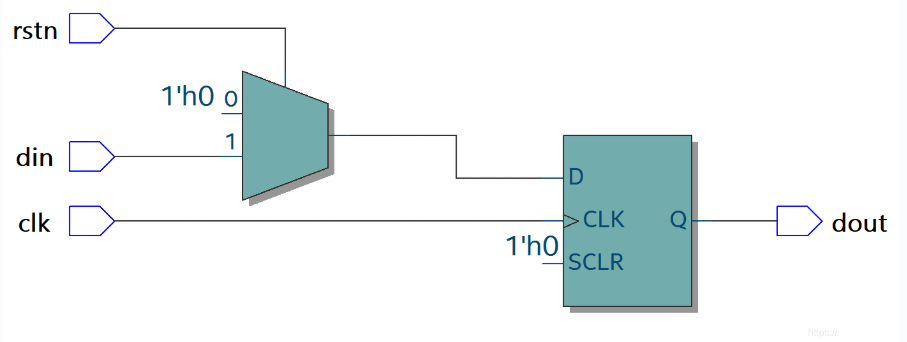
异步复位
1
2
3
4
5
6
7
8
9
10
11
12
13
14
module async_reset(
input rstn, //异步复位信号
input clk, //时钟
input din, //输入数据
output reg dout //输出数据
);
//复位信号要加到敏感列表中
always @(posedge clk or negedge rstn) begin
if(!rstn) dout <= 1'b0 ; //rstn 信号与时钟 clk 异步
else dout <= din ;
end
endmodule
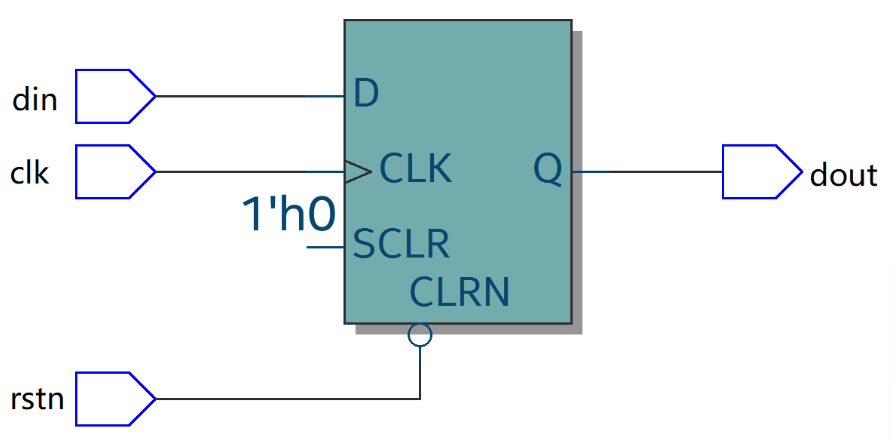
同步复位的优点:信号间是同步的,能滤除复位信号中的毛刺,有利于时序分析。
同步复位的缺点:大多数触发器单元是没有同步复位端的,采用同步复位会多消耗部分逻辑资源。且复位信号的宽度必须大于一个时钟周期,否则可能会漏掉复位信号。(然而xilinx的FPGA是有同步复位端的,并且官方也建议采用同步复位而不是异步复位)。
异步复位的优点:大多数触发器单元有异步复位端,不会占用额外的逻辑资源。且异步复位信号不经过处理直接引用,设计相对简单,信号识别快速方便。
异步复位的缺点:复位信号与时钟信号无确定的时序关系,异步复位很容易引起时序上 removal 和 recovery 的不满足。且异步复位容易受到毛刺的干扰,产生意外的复位操作。
一般数字系统设计时都会使用异步复位。为消除异步复位的缺陷,复位电路往往会采用”异步复位、同步释放”的设计方法。即复位信号到来时不受时钟信号的同步,复位信号释放时需要进行时钟信号的同步。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
module areset_srelease(
input rstn, //异步复位信号
input clk, //时钟
input din, //输入数据
output reg dout //输出数据
);
reg rstn_r1, rstn_r2;
always @ (posedge clk or negedge rstn) begin
if (!rstn) begin
rstn_r1 <= 1'b0; //异步复位
rstn_r2 <= 1'b0;
end
else begin
rstn_r1 <= 1'b1; //同步释放
rstn_r2 <= rstn_r1; //同步打拍,时序差可以多延迟几拍
end
end
//使用 rstn_r2 做同步复位,复位信号可以加到敏感列表中
always @ (posedge clk or negedge rstn_r2) begin
if (!rstn_r2) dout <= 1'b0; //同步复位
else dout <= din;
end
endmodule
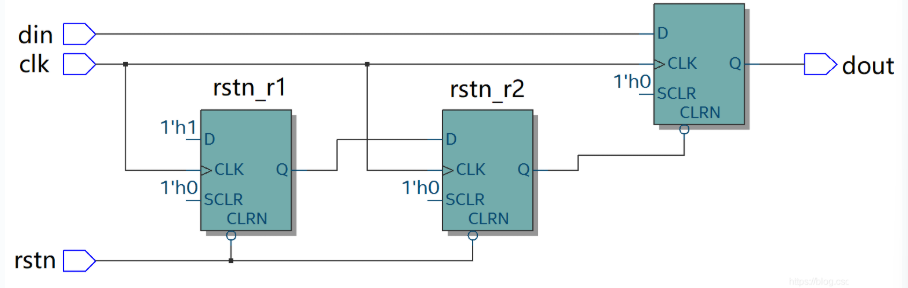
需要说明的是,复位电路会消耗更多的硬件逻辑和面积资源,增加系统设计的复杂性。不带复位端的触发器也具有相对较高的性能。所以在一些初始值不影响逻辑正确性的数字设计中,例如数据通路中一些数据处理的部分,高速流水线中的一些寄存器,可以考虑去掉复位以达到最佳性能。
为方便、快速的仿真非复位逻辑的其他功能,教程所有数字设计中的复位都是从 testbench 中引入异步复位,没有考虑复位电路的时序问题。实际设计数字系统时,一定要对复位电路进行单独、仔细、慎重的设计。