

FPGA 硬件架构
知识储备

基本概念
FPGA 是 CLD(Configurable Logic Device,可编程逻辑设备)的一种,一般用于高质量低延迟的视频流处理,硬件加速等,其工作方式与 GPU 类似,将部分在 CPU 上由软件执行的工作 offload 到硬件电路上进行。
FPGA 的结构由可编程输入/输出单元、基本可编程逻辑单元、嵌入式块 RAM、布线资源和 IP 内核单元几部分组成。CLB(Configurable Logic Block,可配置逻辑块) 是 FPGA 的编程部分,也称逻辑单元,配置时可以只对芯片中的部分 CLB 编程,因此一块芯片可以同时执行不同的功能,或以流水线的形式在不同时刻对数据做不同的处理,故 FPGA 拥有很高的并行度。同样由于这一特性,FPGA 的设计目标之一,就是用最少的 CLB 实现需要的逻辑函数。
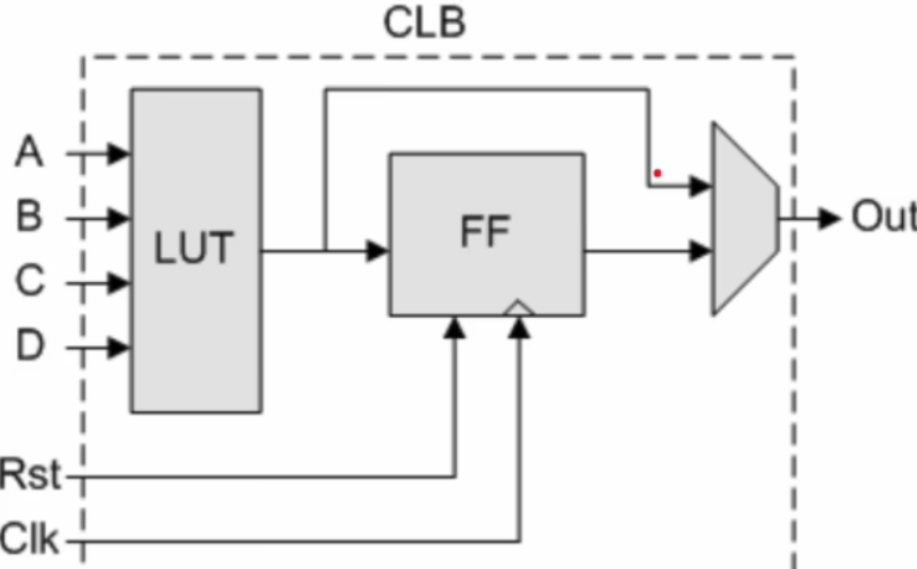
CLB 内部由查找表 LUT(Lookup Table)和触发器 FF(Flip-Flops)构成。LUT 是存储真值表的介质,也可用作分布式 RAM 作为快速高效的 on-chip memory。LUT 通过 SRAM 实现编程,可以反复编程且不用刷新电子。今天的 FPGA,内部除了集成了 LUT 和 FF 外,还集成了 RAM(存储资源)、PLL(高速的时钟信号)、DSP(乘法操作、滤波器、数字信号处理)、SERDES(实现高速接口)、CPU(硬核处理器)、NPU(硬核 AI 推理)等硬核 IP 来满足特定应用场景的需求,这样的架构是解决实际问题和成本效率综合考量后的高度优化的结果。
在 Vivado 综合生成的网表中,FDRE/FDCE 是带时钟使能的触发器,分别支持同步复位和同步清零;LDRE/LDCE 是门控锁存器,分别支持复位或清零;CARRY 是 FPGA 内部的快速进位链,用于加法、计数、比较等。除了这些,FPGA 常见的基本原语还包括 LUT(查找表,实现任意逻辑函数)、MUXF/MUXF7/MUXF8(用于多级逻辑选择)、IOBUF(输入输出缓冲器)、BRAM/URAM(片上存储单元)、DSP48(乘加运算单元)、BUFG/BUFR(全局或区域时钟缓冲) 等,它们构成了 FPGA 的核心逻辑、存储和算术单元。网表是电路连接清单,描述了由哪些逻辑单元(门电路、触发器、LUT、RAM、DSP 等),以及这些单元之间的连线关系(net)。FPGA 芯片就像一张巨大的电路板,除了基本的逻辑单元(LUT、触发器),大部分面积都被布线资源占据,比如可编程导线和开关,用于连接这些基本逻辑单元。
APU 是高性能的应用处理单元,是基于 ARM Cortex-A53(64bit)的四核处理器,通常运行 Linux、Petalinux、Yocto 等操作系统;RPU 是实时处理单元,是基于 ARM Cortex-R5F(32bit)的双核处理器,通常运行 FreeRTOS 和裸机程序。
无论选择哪种启动模式,在 SDK 中运行程序时都会通过 JTAG 接管系统,并按照配置执行初始化,比如先通过 JTAG 对整个系统复位,所有处理器核(A53、R5、PMU、PL)都会被复位,FPGA(PL 部分)被清空,所有寄存器恢复到默认状态;然后重新配置 PL 部分,通过 JTAG 重新下载 bit 文件;然后执行 psu_init 这个板级初始化脚本,完成 CPU、DDR、外设的初始化配置;然后上电激活 PL 端;选择运行的 CPU 核并挂起,下载程序之后运行 elf 文件。
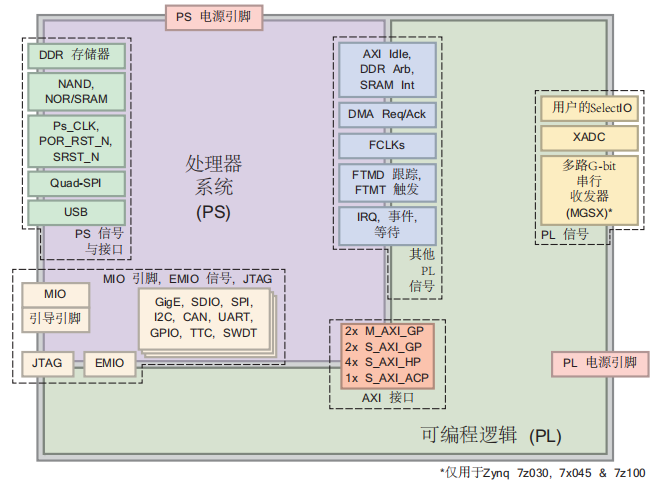
UltraScale+ MPSoC 架构的 PS 端分由 FPD 和 LPD 两个主要电源域/性能域构成,FPD(Full Power Domain)为高性能运算域,包含 APU (Cortex-A53)、GPU、DDR 控制器、FPGA 高性能互联等;LPD(Low Power Domain)为低功耗控制域,包含 RPU (Cortex-R5F)、部分外设(I2C/SPI/UART)、低功耗互联等。
原语是 FPGA 厂商提供的语法糖,对应有专用的底层电路模块,不是标准 Verilog 语法,是介于硬件描述语言和实际硬件电路之间的硬件级命令。
HP 口是 PL 和 PS 之间的 AXI 通道,目的是让 PL 的多个主设备(如 DMA、加速器、视频引擎、网络引擎等)能够高效访问 PS 侧的资源,比如 DDR、AD、DA 等。不同的 HP 口可以配置不同的数据和地址总线宽度以及其它一系列参数。(不同主设备的数据交互接口可能不一样)。
多个 HP 可以用于流量隔离(把不同功能流量分到不同口,避免相互干扰)、QoS 策略、简化仲裁/设计(每个 PL 主控对接固定 HP),或在 PL 侧做 AXI interconnect 后把多个从机合并上 PS。
在 Zynq 里:
- PS 端的 DDR 控制器 是所有主设备(ARM 核、DMA、加速器等)共享的“唯一通道”。
- 但是从 PL 过来的访问(通过 HP 口)都是 AXI Master,会竞争 DDR 控制器的访问机会。
如果你把多个高带宽的模块(例如视频 DMA、网络 DMA、FFT 加速器)都通过同一个 HP 口访问 DDR,会发生:
所有访问请求(AXI 事务)都在一个通道的仲裁器里“排队”。
结果就是:
- 一个模块的突发传输可能长时间占用通道;
- 其他模块被阻塞;
- 不同数据流混杂在一起(读写乱序、延迟不稳定);
- 实际 DDR 带宽利用率下降。
这就是所谓的“流量相互干扰(traffic interference)”。
Zynq(尤其是 Zynq-7000、Zynq Ultrascale+)通常有多个 HP 端口(HP0~HP3,甚至更多),它们的作用可以理解为:
多条独立的 AXI 通道(独立仲裁、独立 FIFO、独立 QoS 设置) 最终再被 PS 内部的 DDR 控制器汇聚、调度。
就像你有一条高速路(DDR 控制器),而 HP0~HP3 是四个不同的匝道入口。 如果你让视频走 HP0、网络走 HP1、AI 加速走 HP2,那么它们的请求在进入 DDR 控制器之前就已经被逻辑隔离开了。
结果:
- 各自的突发访问不会互相阻塞;
- 延迟更稳定;
- DDR 仲裁器可以在更高层次做公平调度;
- 你还可以单独给每条口设置优先级。
这就叫——流量隔离(traffic isolation)。
Zynq 的 PS 内部 AXI interconnect 支持 QoS(Quality of Service)寄存器:
- 你可以对不同的 HP 端口设置不同的优先级;
- DDR 控制器内部仲裁器会根据这些 QoS 值做优先调度。
举例:
- 视频流(HP0)→ 实时性强,设置高 QoS;
- AI 加速器(HP2)→ 吞吐为主,QoS 中等;
- 日志/存储 DMA(HP3)→ 不敏感,QoS 低。
这样 DDR 仲裁器就会“优先保证”高优先级流量。 这就是QoS 策略的应用场景。
如果你 PL 内部设计了多个模块,每个都是 AXI Master:
- 方式 ①:它们都连到一个共享 AXI Interconnect,然后再接 PS 的一个 HP。 → 内部 Interconnect 需要自己做仲裁、ID 管理、带宽控制。复杂度高。
- 方式 ②:每个模块直接接到不同的 HP(HP0~HP3)。 → 每个 HP 都是独立通道,不用在 PL 侧做复杂仲裁,Vivado 自动分配好。 → 你在设计上就能“模块化地”处理它们。
这就是“简化仲裁/设计”的意义: 不用在 PL 侧实现复杂的 AXI 仲裁器,而是直接利用 PS 内部的多通道结构。
Block Design 中的实践建议:用一个 AXI Interconnect / AXI SmartConnect 把多个 PL 主设备连接起来,然后把 Interconnect 的 master 端接到若干个 PS_HP 口(把流量分散到 HP0..HPn)。给流量类型分口:例如 HP0→ 视频 DMA,HP1→ 以太网,HP2→ML 加速器,HP3→ 通用或低优先级流量。配置每个主设备的 AXI ID 与突发深度,调整 PS 端的 QoS/优先级寄存器(如果器件支持)以获得稳定性能。如果需要缓存一致性(例如加速器写入后 CPU 直接读),考虑走 ACP 或在协议层做显式的 cache flush/invalidate。然后做压力测试(多通道同时大量突发传输)来测出瓶颈并决定是否需要把更多 PL 主设备分配到不同 HP。
FIFO Generator 是队列,Block Memory Generator 是随机访问内存。FIFO 用于不同时钟域之间的数据传输(CDC FIFO)、生产者和消费者速度不一致的数据缓冲、流式数据接口缓存;Block Memory 用于需要随机读写的数据存储、查找表、数据缓存等。FIFO 支持异步时钟,只需要告诉它读或写;Block Memory 一般只支持同步时钟,需要管理地址、何时读写。FIFO 更偏向流式、Block RAM 更偏向存储。
FIFO Generator 中的实现资源分时钟域和存储资源两方面,时钟域有同步和异步之分,存储资源可选 BlockRAM、Distributed RAM、Shift Reg、Built-in FIFO。
AXI Infrastructure ├─ AXI-Stream FIFO ├─ AXI4-Stream Data FIFO ├─ AXI Data FIFO └─ AXI Virtual FIFO Controller
Memories & Storage Elements └─ FIFO Generator
它是更完善的 AXIS FIFO
AXI 协议
AXI 全称 Advanced eXtensible Interface,是 ARM 提出的 AMBA 协议标准的一部分,Xilinx 从 6 系列的 FPGA 开始引入这一协议。
AXI 属于片上总线协议,描述主设备和从设备之间的数据传输方式,通过 VALID 和 READY 信号的握手机制建立主从设备之间的连接(VALID 来自主设备,READY 来自从设备)。任意通道上完成一次数据交互都称为一个传输 transfer,当 VALID 和 READY 信号均为高电平时到来时钟上升沿,就会发生传输。一个通道内 VALID 和 READY 信号的建立顺序无关紧要。VALID/READY 机制使得数据的发送和接受方都有能力控制传输速率。
ZYNQ 中使用的主要是 AXI4 协议族,包括 AXI4、AXI4-Lite、AXI4-Stream 三种协议。(注:burst 指一个地址中可发生多次数据传输的传输事务,burst 操作只需要提供首地址)
AXI4:存储器映射总线,采用内存映射控制,支持 burst 传输,高带宽,适合访问块式内存,常用于 DDR 等大量数据读写。
- AXI4-Lite:存储器映射总线,采用内存映射控制,仅支持单数据传输,常用于访问和配置状态寄存器。
- AXI4-Stream:连续流式接口,没有地址的概念,支持 burst 传输,适合访问流式内存,常用于视频流、FFT 数据等流式数据通路。
块式内存和流式内存是两种数据传输模型,块式数据的数据按照地址排列,一次访问一大块数据,典型的访问方式是内存地址+长度,如 DDR / PS 内存存储、CPU 内存搬运等。流式数据的数据不需要地址,一次访问一个元素,一个接一个,典型的方式是按时间按拍数,如 FPGA 内部视频像素流、FFT 数据流等流水线模块处理。
AXI4 和 AXI4-Lite 中,将一次传输事务分为五个独立通道,分别为读地址 AR、读数据 R、写地址 AW、写数据 W 和写响应 B。每个通道各有一组独立的信号线(各信号线的具体含义这里不一一列出),有一个独立的 AXI 握手协议,因此 AXI 协议支持同时进行读写操作。AXI4-Stream 由于没有地址的概念,因此也仅定义了一条通道,完成握手和数据传输。
.png)
ZYNQ 中在 PS 和 PL 之间用硬件实现了九个 AXI 物理接口,包含 AXI-GP0~AXI-GP3、AXI-HP0~AXI-HP3、AXI-ACP 共九个。GP 为 32 位接口,理论带宽 600MB/s,两个 PL 主 PS 从,两个 PS 主 PL 从;HP 接口和 ACP 接口可配置为 32 或 64 位接口,理论带宽 1200MB/s,均为 PL 主 PS 从。一个接口的方向性是固定的,要么能发起事务,要么只能响应事务。每个物理接口支持的协议也是确定的,HP 和 ACP 接口支持 AXI4 协议,GP 接口支持 AXI4 和 AXI4-Lite 协议,而 AXI4-Stream 协议是纯 PL 内部的连接方式,需要用 AXI-DMA 或其它类似模块在 PL 内部实现 AXI4 到 AXI4-Stream 的转换。ACP 与 HP 接口的区别在于 ACP 可以保证与 CPU Cache 的一致性。
ZYNQ 中,PS 端的 ARM 直接有硬件支持的 AXI 接口,而 PL 端需要使用逻辑实现相应的 AXI 协议,Xilinx 提供的现成 IP 如 AXI-DMA、AXI-GPIO、AXI-Datamover、AXI-Stream 都实现了这一接口。
虽然 AXI 协议的五个通道是独立并行的,但并非完全没有逻辑时序约束。AXI 协议要求读通道中读数据位于读地址之后,具体来说是 AR 通道地址有效之后才会返回 R 通道 VALID;类似地,要求写响应位于写通道中地最后一次写入传输之后,具体来说是 B 通道 VALID 只能在最后一个 W 通道地数据拍结束之后才出现。不过,这样的约束是通过 READY 和 VALID 信号实现的,设计时无需考虑地址和数据的先后顺序,较为灵活,只要保证符合 READY 和 VALID 信号的握手机制即可。
AXI 协议的一些特性如下:
- AXI 允许读数据返回之前,又发起一次新的读请求,类似于流水线的概念。延迟较大的情况下,可以做到不影响带宽,将延迟掩盖起来。
- 支持非对齐传输:传输的地址和数据宽度一致时称为对齐传输,地址是字节地址的情况下,假设总线数据宽度为 32bit(4 字节)每次访问的起始地址是 4 的倍数,那么就是对齐的。而 AXI 协议通过 WSTRB 的掩码机制,每一位对应一个字节,可以控制只写入部分字节,因此写传输可以起始于任意地址,不必是 4 字节边界。
- ARSIZE 和 ARBURST 分别规定了单次传输的数据宽度(如 4 字节、8 字节等)和突发类型(FIXED 地址固定、INCR 地址按固定值递增、WRAP 地址递增但循环)。写通道同样有这样的信号。
- 支持不同 ID 之间的乱序传输,同一个 ID 内则是保序的。AXI4 中已经取消了 WID 信号的使用,不再支持写乱序。
- AXI 协议是一个点对点的主从接口,当多个外设需要相互交互数据时,需要加入 AXI Interconnect 模块(Xilinx 提供了相应的 IP),本质上是一个实现交换机制的互联矩阵
DMA 是使用 AXI 总线来读写内存或寄存器的一种方式,也是由 PL 端的逻辑或相应的 IP 实现的。DMA 通过 AXI HP 总线访问内存或 PL,CPU 只负责告诉 DMA 要搬多少数据、源和目的地址,数据搬运完全由 DMA + AXI 高速通道完成。当然,完全可以不用 DMA 机制而直接读写 AXI 总线的数据。
AXI DMA 是一个在 PL 中的硬件 IP,不是 PS 中的外设,通过 AXI 高速接口(如 HP/ACP)与 PS 端的 DDR 交互。AXI DMA 从 BRAM 读写数据的意思是,用 Block Memory Generator 在 PL 中生成一块 BRAM,再用 AXI BRAM Controller 让 BRAM 出现在 AXI 总线上,AXI DMA 就可以让 Master 通过 AXI 总线读写这块 BRAM。
AXI DMA 可以用作成 PL 和 PS 之间的桥梁。PS 端也有 DMA,STM32 中提到的 DMA 就是这种,用于内存和外设之间的数据交互,不支持流式接口。AXI DMA 是 AXI memory-mapped ↔ AXI-Stream 之间的桥梁,负责在地址空间和流式接口之间转化。DMA 通道有 MM2S 和 S2MM,分别负责两个方向。大部分使用 AXI DMA 的场景,都涉及 PL 与 PS 的数据交互,少部分的情况下,纯 PL 也有用到 AXI DMA 的场景,比如 HLS IP 需要一次处理上万点的 FFT 输入,图像处理需要 1280*720 一帧图像作为输入,CNN IP 需要一整块 feature map,即数据并不是逐拍的流式接口能传输的,而是需要将数据存储在一块 Memory 中,这时就需要用到 AXI DMA 来搬运。
除了最常见的 AXI DMA,其它用于 AXI memory-mapped(AXI-MM) ↔ AXI-Stream(AXIS)之间的转换方式还有 AXI DataMover、AXI VDMA、AXI4-Stream to Memory-Mapped / Memory-Mapped to AXI4-Stream(桥接 IP)等。
AXI DataMover 本质上是 AXI DMA 的可编程版本,是 AXI DMA 的底层引擎,HLS、Vitis 以及其它一些 IP 也有使用,比 AXI DMA 更灵活也更复杂;AXI VDMA 是专为二维数据设计的 DMA,支持分辨率、Stride 和 Frame Buffer;AXI4-Stream to Memory-Mapped 用于将 AXIS 写入内存,Memory-Mapped to AXI4-Stream 把内存数据读出来转换成流。
时钟资源
锁相环(PLL)是 FPGA 中的时钟资源资源,通过 PLL 可以由晶振的频率引出许多不同的频率供各种外设使用。FPGA 使用专用的全局和局部 IO 以及时钟资源来管理各种时钟需求。FPGA 中的时钟不能直接裸信号使用,也不能走普通的布线逻辑,而需要经过专用的 buffer 电路驱动到全局或区域的时钟网络,这称为时钟 buffer。buffer 的作用主要是提高驱动能力和保证延迟均衡。
FPGA 内部有大量可编程的互连资源,逻辑单元之间的信号通过这些线段和开关连接,称为布线逻辑 (routing fabric)。普通布线逻辑指这些通用的互连通道,用来传数据/控制信号。它们延迟大、路径长短不一、受布线工具优化影响。时钟如果走普通布线逻辑 → 延迟和 skew 无法保证,会导致严重的同步问题。时钟倾斜 skew 是指同一个时钟信号到达不同触发器的时间差。如果 skew 太大,可能导致 setup/hold 时间被破坏 → 数据寄存错误。因此需要使用专用的时钟 buffer + 全局时钟网络(时钟布线网络),把 skew 控制在几十皮秒的范围内。
全局时钟资源指 FPGA 内部专门布设的低延迟、低偏斜的长距离布线网络,保证一个时钟信号可以同时驱动全芯片的逻辑,对应的 buffer 为 BUFG(Global Clock Buffer),用于驱动全局时钟,如系统主时钟、DDR 时钟等。
区域时钟资源限定在芯片的一部分,对应的 buffer 为 BUFH(Horizontal buffer)和 BUFR(Regional buffer),用于驱动局部时钟,减少功耗和浪费。FPGA 不允许随便用普通布线逻辑来传时钟,因为普通布线延迟大且不均衡,会导致时钟偏移,因此 Xilinx 给时钟单独做了专用的全局和局部 IO 与时钟资源。
CMT(Clock Management Tiles)分布在 FPGA 中的不同位置,提供了时钟合成、倾斜矫正和过滤抖动等功能,每个 CMT 包括一个 MMCM(Mixed Mode Clock Manager)和一个 PLL(Phase Lock Loop)。PLL 通过锁相机制使输出时钟和输入时钟相位一致,可实现分频和倍频,缺点是相位控制粒度有限。MMCM 比 PLL 功能更强,可实现分数分频/倍频和更精准的相移。CMT 的输入可以是 BUFR、IBUFG、BUFG、GT、BUFH 和本地布线,MMCM 或 PLL 输出的是原始时钟信号,要驱动 FPGA 内部逻辑,还需要接入专用时钟网络(BUFG/BUFH)。
时钟 buffer/网络说明:
- IBUFG (Input BUFG):把外部引脚的时钟(从 IO pin 来的时钟)引入到 FPGA 内部,送入全局/区域时钟网络。
- BUFG (Global BUFG):驱动全局时钟网络,确保整个芯片时钟到达几乎同时。
- BUFH (Horizontal Buffer):区域时钟 buffer,只在本 region(一般是一个 clock region,高度 50 CLB 左右)内部传播。
- BUFR (Regional BUFR):区域时钟 buffer,常用于 I/O 时钟(比如串行接口的本地时钟)。
- GT (Gigabit Transceiver):高速收发器自带的时钟输出,可作为 CMT 的时钟源。
- 本地布线 (Local routing):如果你把时钟当普通信号布线,会走 LUT/普通 interconnect,延迟和偏斜不可控。
存储结构
FPGA 中常用的逻辑存储结构有 RAM、ROM 和 FIFO,三种结构 Xilinx 都提供了成熟的 IP,具体使用查阅文档即可。RAM 和 ROM 的 IP 有 Distributed Memory Generator 和 Block Memory Generator 两个,区别在于生成的 Core 所占用的 FPGA 资源不一样,从 Distributed Memory Generator 生成的 RAM/ROM Core 占用的资源是 LUT;而从 Block Memory Generator 生成的 RAM/ROM Core 占用的资源是 Block Memory。
Block Memory 是 FPGA 中片上块状存储资源的统称,是逻辑上的概念。Block Memory 主要由 BRAM 实现,少数型号的 FPGA 也有 URAM 和 HBM。BRAM 即 Block RAM,是 FPGA 中固化的硬件存储单元,固定容量为 18K bits(18432 bits),可以单独使用也可以两个相邻的 18k BRAM 组合成双口 36k BRAM。设计中调用的资源以 BRAM 为最小单位,向上取整。例如存储位宽为 16 位,数据深度为 512,总共占用 16*512=8192 bits = 1KBytes。
RAM 和 ROM 中任意一个存储单元都可以在相同时间内被访问,硬件上由存储单元阵列 + 地址译码器 + 读写电路构成;ROM 由 RAM 配合要预先写入的 coe 文件实现。FIFO 是先进先出队列存储器,内部常用环形缓冲区的结构,由 RAM+读写指针实现。根据读写时钟,可以分为同步 FIFO 和异步 FIFO,同步 FIFO 的读写时钟相同,异步 FIFO 的读写时钟不同。
FIFO 不像 RAM 那样可以随意访问地址,而是写入只能写到队尾,读出只能从队首读取,硬件自动维护顺序,读写顺序固定。FIFO 的容量一般比较小,广泛用于数据的缓存、平衡异步时钟域之间的速度差等。读写对象为读写指针指向的存储单元,读写时操作指针位置,FIFO 内部逻辑负责防止读空或写满。FIFO 不能重复读出数据,也不能覆盖数据,没有地址的概念,由 full、empty 信号进行数据流控制;RAM 则反之。
数据宽度指一个数据占用的 bit 位数,数据深度指可以存放的数据个数。数据深度与地址线宽度有关,如数据深度为 512,则对应的地址线为 9 位,\(2^9=512\)。
Block Memory Generator 本质上是在配置块式存储的接口和访问方式,可以配置 Interface Type 为 Native 或 AXI4,区别在于访问协议,Native 信号简单,延迟低,时序友好,需要自己设计握手逻辑,在 RTL 中自己控制读写逻辑;而 AXI4 Interface 使用 AXI 标准总线协议,一般用于直接连接 MicroBlaze、PS 端、AXI DMA、AXI Interconnect 等,配置为哪个取决于是什么模块访问这块存储(访问的发起者)。
Block Memory Generator 还可以配置 Memory Type 为单口 RAM、伪双口 RAM、双口 RAM、单口 ROM 和双口 ROM。单口 RAM 只有一组地址、数据、读写控制端口,不能同时读写;伪双口 RAM 有两个独立端口,但一个只读一个只写;真双口 RAM 有两个均可读写的独立端口。byte write enable 用于分字节控制写入,不启用则默认写使能控制全位宽。此外还可以配置读写冲突的处理模式,WRITE_FIRST 是当对同一地址同时进行读写操作时,写入的新数据会立即输出到读端口,推荐用于异步时钟可能导致读写同时操作的场景(如跨时钟域数据交互),确保读端口能及时获取最新写入的数据;READ_FIRST 是当对同一地址同时进行读写操作时,读端口输出的是写入前的旧数据,新数据会在之后的周期更新到存储中。该模式能保证无冲突,但功耗较高,适用于需要安全读取 “旧数据” 的场景(如数据备份、状态校验),确保读操作的可靠性。NO_CHANGE 是写操作时,读端口数据保持不变;仅在读操作时才会更新输出。该模式功耗最低,但不保证双端口同时访问同一地址时的冲突问题,适用于对功耗敏感、且能通过外部逻辑避免地址冲突的场景。最后,还可以配置 Primitives Output Register 和 Core Output Register,用于寄存数据,增加时序裕量,适合对输出时序要求更高的场景;不配置的情况下,默认数据之后地址一个时钟周期。
Block Memory Generator 的 IP 配置完成后,剩余的工作就是自己写代码维护数据、地址和读写控制。
FIFO Generator 的配置和 Block Memory Generator 有许多相通之处,同样有 Interface Type,可配置为 Native、AXI Memory Mapped 和 AXI Stream,配置为哪个取决于这块存储的访问者。FIFO Implemetation 可选择时钟域为 common clock 或 independent clock,存储资源可配置为 Block RAM、Distributed RAM、Shift FIFO 和 Builtin FIFO。
Read Mode 可配置为 Standard FIFO 和 First Word Fall Though,前者是标准 FIFO 模式,数据需通过读使能触发后,在下一个时钟周期才能从输出端读取。即读操作存在 1 个时钟周期的延迟,用于对时序控制要求严格的场景(如跨时钟域同步、流水线设计),需明确通过读使能控制数据读取时机。后者是首字直通模式,数据会自动预加载到输出,无需等待读使能触发,FIFO 非空时第一个数据就会直接出现在数据线上,读使能时数据呗消费,下一个数据自动加载,读操作无延迟,适用于低延迟需求的场景(如实时信号处理、高速数据流交互),可减少读操作的等待时间,提升数据吞吐效率。
FIFO Generator 可以配置一系列标志位,除了标配的 full 和 empty 外,还有 almost full、almost empty、overflow、underflow、write ack、read valid。full 的局限性在于,上游模块写入速度快于 FIFO 处理速度时,full 信号发出时已经写入了数据。almost 信号可以通过配置阈值来提前预警。overflow 和 underflow 用于错误检测。很多工程师都踩坑:Empty=1 时读一次,你会读到无效数据,容易造成后端异常。Underflow 就是发现这种情况的保护机制。write ack 用于告诉已经写入成功了,read valid 用于告诉读出的数据是有效的。FIFO 设置默认为采用 safety circuit,此功能是保证到达内部 RAM 的 输入信号是同步的,在这种情况下,如果异步复位后,则需要等待 60 个最慢时钟周期(时钟频率最低的时钟的 60 个时钟周期)。
full 信号和内部状态机共同控制 wr_en 写使能,写使能时更新数据,不使能时保持数据不变(不更新);empty 和内部状态机共同 rd_en 读使能。
实现方式可以选用 Fabric 和 DSP48,前者是 FPGA 通用的逻辑资源,包括查找表、触发器、多路选择器等基础逻辑单元。特点是功能灵活,可实现任意数字逻辑,但运算性能(速度、功耗)相对较低,且复杂运算(如乘法、乘加)会消耗大量 LUT 资源。适用于简单逻辑运算(如小规模加法、逻辑门组合)、控制类电路,或在 DSP48 资源不足时的 “兜底” 实现。后者是专用的硬核数字信号处理器,是 FPGA 内置的专用数字信号处理模块(如 Xilinx 的 DSP48E 系列),集成了乘法器、累加器、ALU 等专用电路。特点是针对高速算术运算(乘法、乘加、滤波、FFT 等)做了硬件优化,具有高频率、低功耗、资源高效的特点(一个 DSP48 可替代数百个 LUT 实现乘法),适用于高性能数字信号处理场景,如 FIR/IIR 滤波器、复数乘法、矩阵运算、神经网络加速等,需要密集算术运算的领域。DSP Slice 是 DSP48 系列硬核的最小功能模块,是构成复杂 DSP 单元的基础,集成了高速乘法器、加法器、累加器、多路选择器和控制逻辑等最核心的算术运算组件。
HP 口和 MIG 控制器访问 DDR 的区别:在 MPSoC 中,通过 HP 接口访问 DDR 是利用 PS 内置的 DDR 控制器,PL 逻辑通过 AXI 总线与 PS 共享同一片 DDR,优点是简单易用、无需配置 DDR 时序,适合与 CPU 协同的数据处理;而使用 MIG IP 则是在 PL 端自建 DDR 控制器,连接独立的外部 DDR,拥有独立带宽和可自定义的时序与参数,性能更高但设计复杂、资源占用更大。简单来说,HP 接口是“借用 PS 的 DDR 控制器”,而 MIG 是“自己造一个 DDR 控制器”,前者易用共享,后者灵活独立。
ILA 逻辑分析仪
ILA 工作原理:ILA IP 被综合进 PL 逻辑电路中,本质上是片上逻辑分析仪,每个时钟沿采样一次所监控的信号;点击 run trigger for this ILA core 时,背后执行操作是从现在开始采样,直到触发条件满足,就把触发点前后的一段波形存下来(不设置触发条件的情况下,将点击 run 的时候视为触发)。ILA 抓取到的数据是运行中 PL 内部信号的采样结果,相当于捕获了那一瞬间的硬件状态,是对信号状态的一次快照,而不是仿真或重启程序。
MIO 和 EMIO
Bank 是可编程逻辑芯片中对芯片内功能相近或关联的硬件资源进行物理分区和管理的单元,一般指 IO Bank。FPGA 芯片的管脚被划分为多个 IO Bank,每个 Bank 有一组外部供电的电源引脚,PS 的 IO 和 PS 的 MIO 都分布在若干个 Bank 中,每个 Bank 有独立的电平标准。在 FPGA 进行引脚分配时,必须先明确每个 IO Bank 的电源电平、支持的接口标准和资源限制(如是否带 PLL)。
MIO (Multiplexed IO)是 PS 端提供的物理 IO 管脚,可以连接诸如 UART、SPI、I2C、GPIO 等,通过 Vivado 软件设置可以将信号通过 MIO 导出。也可以将信号通过 EMIO 连接到 PL 端的 FPGA fabric,再从 PL 的 I/O Bank 的管脚引出。EMIO 是 PS 端的信号(注意不是来自 PS 封装的 MIO 引脚)通过 AXI 接口暴露到 PL 侧的一组逻辑 GPIO 接口,来源是 PS 内部信号,是直接逻辑线,不是直接的物理引脚。这样的逻辑线接入 IOBUF 之后,才成为 PL 端可以实际操作的物理引脚。
AXI GPIO 模块可以定义两个 GPIO 通道独立工作,且使用 Board Interface 可以不用手动添加相应的管脚约束。AXI GPIO 相较于 EMIO 的好处是,可以将多个 GPIO 当作总线一起控制;EMIO 则比较适合单个 GPIO 信号的控制。可以使用 AXI GPIO 的 IP 核,通过 AXI 总线控制 PL 端信号。AXI GPIO 是 xilinx 提供的 PL 侧的外设 IP 核,作用是让 PS 通过 AXI 总线访问 PL 端的 GPIO,因此使得 PS 端可以访问到 PL 端的信号。AXI GPIO 来源是 PL 内部逻辑,PS 通过 AXI 寄存器访问 PL GPIO,读写过程需要 AXI 总线。
ZYNQ 产品线
FPGA 和 SoC 是 Xilinx 的两大主要产品系列。
FPGA 即纯 FPGA 芯片,按照工艺节点分为 UltraScale+(16nm)、UltraScale(20nm)、7 Series(28nm)三大类,类似于 CPU 中第几代的概念。在每个类别中,又分为 Spartan、Artex、Kintex、Virtex 四个子系列,面向不同的应用场景和市场定位,性能依次提升。

除了最新的 Versal ACAP(Adaptive Compute Acceleration Platform,自适应计算加速平台)之外,Xilinx 将 SoC 系列命名为 ZYNQ 计算架构,是 FPGA + Arm 的多处理器系统,集成了 FPGA 的可编程逻辑(PL)与 ARM 处理器核心(PS),两者之间通过 AXI(Advanced eXtensible Interface)总线实现低延迟数据传输。PS 具有固定的架构,包含了处理器和系统的存储器,适合控制或具有串行执行特性的部分以及浮点计算等;而 PL 是完全灵活的,适合并行流处理。
ZYNQ 的 PS 内集成了很多外设控制器模块,如 UART、SPI、I2C、CAN、USB、Ethernet 等,本质上是固化在 ZYNQ 芯片中的硬核外设 IP,是 PS 区域内的逻辑电路。它们存在于 SoC 的 PS 端,与 ARM CPU 核、DDR 控制器、时钟系统等都在同一个芯片中,通过 AXI 总线与 CPU 内核连接,CPU 可以读写寄存器来控制外设。
ZYNQ 架构分为 ZYNQ-7000 SoC、ZYNQ UltraScale+ MPSoC、ZYNQ UltraScale+ RFSoC 三类。ZYNQ-7000 SoC 的 PS 端为 Cortex A9 的 Arm 核心,为 ARMv7-A 架构,32 位;PL 端为 7 Series 的 FPGA。ZYNQ UltraScale+ MPSoC(MultiProcessor)的 PS 端为 Cortex A53 的 Arm 核心,为 ARM-v8-A 架构,64 位,另外还配备 Cortex-R5F 作为协处理器;PL 端为 UltraScale+的 FPGA。ZYNQ UltraScale+ MPSoC 再往下又可以细分为 CG、EG、EV 三类,面向的硬冲场景不同。ZYNQ UltraScale+ RFSoC(Radio Frequency)与 ZYNQ UltraScale+ MPSoC 的区别仅在于配备了高速 ADC 和 DAC 通道,用于射频领域。