

FPGA系列(1)
Vivado + Vitis 使用

vivado + vitis 是 Xilinx FPGA 配套的软件栈。vitis 前身叫 SDK,Xilinx 被 AMD 收购后重构为 vitis,两者在使用上大致相同。虽然 vivado 这头洪水猛兽跑得又慢还偶尔碰到疑似软件本身 bug 的情况,但这已经是所有 FPGA EDA 中最成熟的一个了,并且写写代码跑跑综合布局布线就能改电路结构,想想还是挺神奇挺有意思的。
这套工具链是初学 FPGA 的入手点,跑几个买 FPGA 板卡时赠送的例程或者跟着公开的教程操作几遍大致就能用起来了。vitis 模仿了 VSCode 的界面,快捷键和许多操作也都是相通的,这里主要做一些基本使用之外的补充介绍。
vivado 编译提速
- vivado 吃单核 CPU 性能和内存频率,硬件升级可以带来最大程度的提升。
- 用 set_param general.maxThreads 32 设置最大线程数,并写入 vivado 安装路径的 scripts 文件夹中新建 vivado_init.Tcl 文件中;2024.2 版本的 vivado,最大可以设置到 32。
- linux 比 windows 的编译速度略快。
- 软件版本上,目前 2024.2 是最快的。
- 不同的综合和实现策略上,在设置中选择 Flow_RuntimeOptimized 的综合策略,可以略微提速,但这是以实现性能换编译时间,测试完成或发现时序难以满足要求时,需要换回默认策略。这个方法一般不建议使用。
OOC
在 Vivado 中生成 IP 或模块时,一般会默认选择 Out-of-Context 综合/实现 (OOC),即单独综合/实现一个时序独立、不受外部逻辑影响的模块,因为 IP 模块可能很复杂,如果每次综合整个工程就会非常慢。OOC 相当于提前单独综合好,工程里直接引用已完成的网表。
逻辑分析仪 ILA
ILA IP 被综合进 PL 逻辑电路中,本质上是片上逻辑分析仪,每个时钟沿采样一次所监控的信号;点击 run trigger for this ILA core 时,背后执行操作是从现在开始采样,直到触发条件满足,就把触发点前后的一段波形存下来(不设置触发条件的情况下,将点击 run 的时候视为触发)。ILA 抓取到的数据是运行中 PL 内部信号的采样结果,相当于捕获了那一瞬间的硬件状态,是对信号状态的一次快照,而不是仿真或重启程序。
xdc 文件
xdc 文件用于存放约束,约束分物理约束和时序约束两类。物理约束包括 IO 接口约束、布局约束、布线约束、配置约束;时序约束涉及 FPGA 内部各种逻辑或走线的延时。
xdc 文件中约束的端口需要与顶层模块中的一致,管脚约束是加在顶层的设计文件上的。
在最佳实践中,建议以约束集(一个 constraint 目录)为单位管理 xdc 文件,其中分 pins.xdc 和 timing.xdc,前者用于配置引脚 IO 等物理约束,后者专门用于配置时序约束。除了直接编写 xdc 文件,也可以通过 GUI(Constraint Wizard 和 Edit Timing Contraint)的方式设置约束,后由 EDA 将 GUI 设置的结果自动写入 xdc 文件。实际使用中,往往用 GUI 设置时序约束,而物理约束一般直接修改 xdc 文件。
xdc 文件支持 tcl 语言,文件顺序解析,即针对同一个管脚或同一个时钟时钟的不同约束,只有最后一条约束生效。除了先后顺序之外,约束还有优先级。对于同样的约束,定义越精细则优先级越高。
xdc 是标准的 sdc(synopsys design constrait)的超集,xdc 包含 sdc 和 xilinx 专有的约束。通用的 sdc 约束包括 create clock、create generated clock、set input delay、set output delay、set multicycle path、set max delay、set false path 等,xilinx 专有约束包括 set property 等。
物理约束编写
物理约束相对简单,普通 IO 口只需约束引脚号和电压,注意大小写,端口名称是数组的话用{ }括起来,端口名称必须和源代码中的名字一致,且不能和关键字一样。
- 管脚约束:
set_property PACKAGE_PIN 引脚编号 [get_ports 端口名称] - 电平信号约束:
set_property IOSTANDARD 电平标准 [get_ports 端口名称]。
1
2
3
4
5
6
7
8
9
10
11
12
13
set_property PACKAGE_PIN J16 [get_ports {led[3]}]
set_property PACKAGE_PIN K16 [get_ports {led[2]}]
set_property PACKAGE_PIN M15 [get_ports {led[1]}]
set_property PACKAGE_PIN M14 [get_ports {led[0]}]
set_property PACKAGE_PIN N15 [get_ports rstn]
set_property PACKAGE_PIN U18 [get_ports clk]
set_property IOSTANDARD LVCMOS33 [get_ports {led[3]}]
set_property IOSTANDARD LVCMOS33 [get_ports {led[2]}]
set_property IOSTANDARD LVCMOS33 [get_ports {led[1]}]
set_property IOSTANDARD LVCMOS33 [get_ports {led[0]}]
set_property IOSTANDARD LVCMOS33 [get_ports rstn]
set_property IOSTANDARD LVCMOS33 [get_ports clk]
BOARD_PIN 是 Vivado 板级接口约束(Board Interface Constraint)系统的一部分属性。它不是约束 FPGA 封装引脚的“物理约束”(比如 PACKAGE_PIN), 而是 Vivado 板卡定义(Board Definition)机制中自动生成的“逻辑绑定信息”。Vivado 的 Board 文件系统允许:选择某块开发板(如 ZCU102、ZedBoard、VC707);然后直接把 IP 的接口(如 AXI GPIO、UART、I2C)连接到 板卡接口(Board Interface);Vivado 自动知道这些接口应该连到哪个物理引脚、使用什么 IOSTANDARD。这种自动化的“板卡接口”约束就叫 Board Interface Constraint,它在内部通过命令实现:
1
set_property BOARD_PIN "some_pin_name" [get_ports <port_name>]
tcl 脚本
vivado 是靠 tcl 工作的,GUI 界面是 tcl 的壳子,界面上的每一步操作都等价于在后台执行 tcl 命令。就像命令行和图像界面的关系一样,tcl 脚本的意义在于构建自动化的工程流程(创建工程、添加源文件、生成 IP、设置约束、综合实现、生成比特流、导出硬件),一些应用 tcl 的例子比如工程版本复现、批量生成 IP、根据顶层端口生成约束文件、多版本代码自动测试、不同优化性能下比较性能、快速验证多个参数组合的效果。
Xilinx Tcl Store 是一个开源共享的 tcl 脚本库,其中有一些实用的 tcl 脚本,相当于 vivado 的插件系统,可以扩展 vivado 设计套件的核心功能。在 tcl store 中点击可以查看每个脚本支持的 tcl 命令。可以基于 tcl 脚本创建工程,Tools 选项卡中可以运行 tcl 脚本文件,也可以直接在 tcl console 中交互式运行 tcl 命令。Xilinx 官方关于 tcl 的文档为 UG894 和 UG835。
两种工程
vivado 可以创建 RTL Project 和 Post-synthesis Project,RTL Project 是最常用的完整设计流程项目,覆盖从 RTL 代码生成到比特流生成的全流程;Post-synthesis Project 用于导入已经完成综合的网表,聚焦于后端实现(布局布线、时序优化),适合复用已有的综合结果、快速验证不同实现策略的效果。
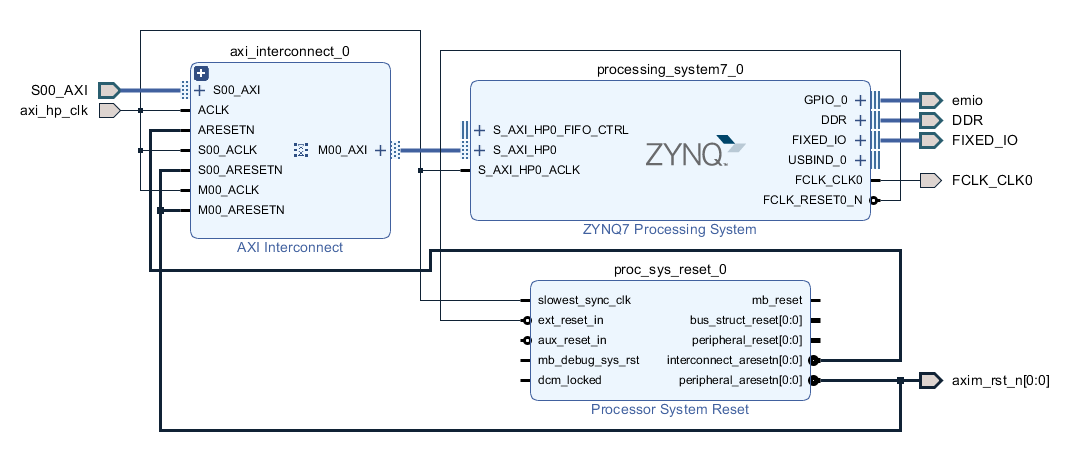
Block Design
Block Design 是 vivado 里的图形化硬件系统设计方式。可以创建多个 bd 文件用于封装多个子系统。Open Block Design 可以选择打开项目中的某一个 Block Design。Generate Output Products 可以选择为某一个 Block Design 内的各个 IP Core 生成 HDL 底层实现文件,修改 BD 中的 IP 时需要重新执行。Create HDL Wrapper 是给 BD 生成一个顶层 HDL 文件,让综合器将 BD 当作一个普通 IP 来使用,生成的 Wrapper 就是综合/仿真时的入口文件,生成时可以选择让 vivado 自动维护,修改 BD 时自动更新。通常先 Generate Output Products,再 Create HDL Wrapper。绑定引脚时以 Wrapper 中的声明为准。
设计规范检查
Report Methodology 可检测 HDL 设计是否符合 Xilinx 推荐的一系列规则和设计实践,并给出优化和修复建议。Report DRC(Design Rule Check)用于检查设计是否违反 FPGA 芯片的硬性约束,例如 IO Bank 电压不兼容、时钟走线错误、跨 Bank 电压冲突、约束冲突等。Report Noise 用于评估 FPGA I/O 信号的噪声,一般用不到。上面说的三个 report,在 RTL Analysis、Synthesis 和 Implementation 中都有,各自会分别给出前端 RTL 代码编写和后端约束和优化的建议。除此之外,Report Utilization 可以报告综合后或实现后使用的逻辑资源量。
Schematic
Schematic 原理图中会显示逻辑连接,右键某个模块,其中的 floorplanning 可以将当前选中的逻辑布置在自定义的 FPGA 中的某个物理区域(Pblock,即 Physical Block)中,相当于创建对布置的空间约束,让实现工具按照设置的约束来放置逻辑,这些逻辑在实现时就会被限制在这个区域里。右键模块,其中的 report timing 可以只对与该模块相关的路径进行时序分析并输出报告,包括输入 → 模块 → 输出的关键路径。另外,schematic 中还可以选择将原理图展开到不同的层级。还可以选择连线并 mark debug,assign 到 debug hub 的某个 probe 上。
布线工具
布线工具指 EDA 的自动布线算法,读取网表(逻辑单元和连接关系)并决定每个逻辑单元放在 FPGA 上的哪个位置(Place),决定用哪些具体的导线 + 哪些开关,把它们连起来(Route)。实现的效果是把抽象的“逻辑连接” → 映射到具体的 物理导线和开关配置。输出的结果是一个 bitstream 配置文件,用来配置 FPGA 内部的 SRAM 控制每个开关的开关状态。
ARM 核心使用
使用 ZYNQ 中的 ARM 核心,需要通过 Block Design 进行配置,配置完成后导出 ARM 核心的端口或连线到其它模块或 IP 上;完成整个 Block Design 的连线后 Generate Output Products,生成 bd 输出文件,再由 bd 文件 Create HDL Wrapper,最后导出硬件信息生成 xsa 文件,这就包含了 PS 端的配置信息。然后在 vitis 中由 xsa 文件创建 platform,并由 platform 创建 application,完成 application 的软件开发后,通过 Run 或 Debug 在板子上运行。
Tools 中的功能
最后,Tools 中有一些入门阶段可能用不到但看起来似乎很实用的功能,先记录下来。Create and Package New IP 用于封装自定义 IP;Create Interface Definition 用于自定义接口标准;Partial Reconfiguration Wizard 用于实现 FPGA 的部分重配置功能,即在系统运行时动态更新 FPGA 部分区域的逻辑,用于自适应计算、多任务切换等需要灵活升级、资源分时复用的场景;Associate ELF Files 用于关联 elf 可执行文件,支持嵌入式程序的调试下载和运行;Generate Memory Configuration File 用于初始化 FPGA 的 BRAM、DDR 等存储器,指定上电初始数据;Compile Simulation Libraries 用于为第三方仿真工具编译 XIlinx IP 和硬件原语的仿真模型,确保第三方工具仿真时能正确调用 FPGA 底层硬件逻辑,保证仿真与硬件行为一致;Custom Commands 用于将自定义工具脚本命令集成到 vivado 界面中;Language Templates 提供 Verilog、VHDL、Tcl 的代码模板;Settings 用于配置 vivado 的全局参数。
vitis 工程说明
xsa 文件包含了导出的硬件平台描述,用 vitis 打开后可以看到一张表格,其中 cell 一列表示 block design 中相应的硬件 IP 实例名,用于在软件层面标识。CPU 访问外设时,是通过 AXI 总线以内存映射寄存器的方式进行的。base address 和 high address 是分配给该外设的一段统一编址后的物理地址空间,每个外设都有一段寄存器空间。
(注:这里用了 SDK 而不是 vitis 的图,不过两者是一样的)
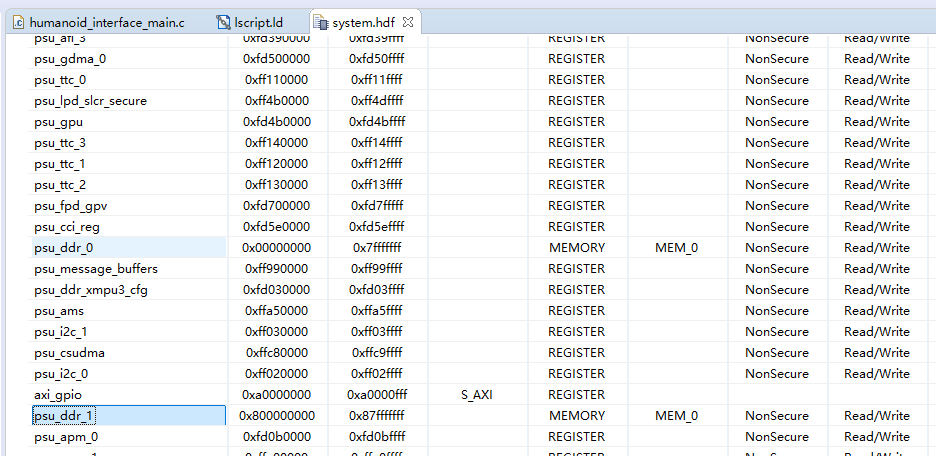
xparameters.h 中定义了各个外设的基地址、器件 ID 和中断等。libsrc 目录下包含了外设函数定义和使用注释说明。lscript.ld 中定义了可用 memory 空间,栈和堆空间大小等,可根据需要修改。lscript.ld 中 psu_ddr_0_MEM_0 和 psu_ddr_1_MEM_0 的值是根据 xsa 文件来的,软件开发时需要注意这两个地址。
Xilinx 原语
原语是 FPGA 厂商提供的对应有专用的底层电路模块,不是标准 Verilog 语法,是介于硬件描述语言和实际硬件电路之间的硬件级命令。
Vivado 综合生成的网表就是由原语描述的。FPGA 常见的基本原语有 LUT(查找表)、MUXF/MUXF7/MUXF8(用于多级逻辑选择)、IOBUF(输入输出缓冲器)、BRAM/URAM(片上存储单元)、DSP48(乘加运算单元)、BUFG/BUFR(全局和区域时钟缓冲) 、FDRE/FDCE(带时钟使能的触发器,分别支持同步复位和同步清零)、LDRE/LDCE(门控锁存器,分别支持复位或清零)、CARRY(快速进位链)。
存储类 IP 配置
存储类功能的开发本质上就是配置相应的存储空间的接口和访问方式,然后写代码维护数据、地址和读写控制逻辑,这里集中对 IP 配置进行说明。
Interface Type 可配置为 Native 或 AXI4 ,区别在于访问协议,Native 信号简单,延迟低,时序友好,需要自己设计握手逻辑,在 RTL 中自己控制读写逻辑;而 AXI4 Interface 使用 AXI 标准总线协议,一般用于直接连接 MicroBlaze、PS 端、AXI DMA、AXI Interconnect 等,配置为哪个取决于是什么模块访问这块存储(访问的发起者)。Data Width 和 Data Depth 分别为数据位宽和数据深度,即单个数据含多少 bit,以及最大可存储的数据个数。
RAM IP 配置
RAM 的 Memory Type 可配置为单口 RAM、伪双口 RAM、双口 RAM、单口 ROM 和双口 ROM。单口 RAM 只有一组地址、数据、读写控制端口,不能同时读写;伪双口 RAM 有两个独立端口,但一个只读一个只写;真双口 RAM 有两个均可读写的独立端口。byte write enable 用于分字节控制写入,不启用则默认写使能控制全位宽。
此外还可以配置读写冲突的处理模式,WRITE_FIRST 是当对同一地址同时进行读写操作时,写入的新数据会立即输出到读端口,推荐用于异步时钟可能导致读写同时操作的场景(如跨时钟域数据交互),确保读端口能及时获取最新写入的数据;READ_FIRST 是当对同一地址同时进行读写操作时,读端口输出的是写入前的旧数据,新数据会在之后的周期更新到存储中。该模式能保证无冲突,但功耗较高,适用于需要安全读取 “旧数据” 的场景(如数据备份、状态校验),确保读操作的可靠性。NO_CHANGE 是写操作时,读端口数据保持不变;仅在读操作时才会更新输出。该模式功耗最低,但不保证双端口同时访问同一地址时的冲突问题,适用于对功耗敏感、且能通过外部逻辑避免地址冲突的场景。
最后,还可以配置 Primitives Output Register 和 Core Output Register,用于寄存数据,增加时序裕量,适合对输出时序要求更高的场景;不配置的情况下,默认数据之后地址一个时钟周期。配置完成后,剩余的工作就是自己写代码维护数据、地址和读写控制。
FIFO IP 配置
FIFO Implemetation 可选择时钟域为 common clock 或 independent clock,存储资源可配置为 Block RAM、Distributed RAM、Shift FIFO 和 Builtin FIFO。
Read Mode 可配置为 Standard FIFO 和 First Word Fall Though。前者是标准 FIFO 模式,数据需通过读使能触发后,在下一个时钟周期才能从输出端读取,即读操作存在 1 个时钟周期的延迟,用于对时序控制要求严格的场景(如跨时钟域同步、流水线设计),需明确通过读使能控制数据读取时机。后者是首字直通模式,数据会自动预加载到输出,无需等待读使能触发,FIFO 非空时第一个数据就会直接出现在数据线上,读使能时数据呗消费,下一个数据自动加载,读操作无延迟,适用于低延迟需求的场景(如实时信号处理、高速数据流交互),可减少读操作的等待时间,提升数据吞吐效率。
FIFO Generator 可以配置一系列标志位,除了标配的 full 和 empty 外,还有 almost full、almost empty、overflow、underflow、write ack、read valid。full 的局限性在于,上游模块写入速度快于 FIFO 处理速度时,full 信号发出时已经写入了数据。almost 信号可以通过配置阈值来提前预警。overflow 和 underflow 用于错误检测。write ack 用于告诉已经写入成功了,read valid 用于告诉读出的数据是有效的。
FIFO 设置默认为采用 safety circuit,此功能是保证到达内部 RAM 的 输入信号是同步的,在这种情况下,如果异步复位后,则需要等待 60 个最慢时钟周期(时钟频率最低的时钟的 60 个时钟周期)。full 信号和内部状态机共同控制 wr_en 写使能,写使能时更新数据,不使能时保持数据不变(不更新);empty 和内部状态机共同 rd_en 读使能。
AXI 桥接类 IP
Xilinx 提供的可实现 AXI / AXI-LITE 与 AXI Stream 的桥接功能的 IP 包括:
- AXI-Stream FIFO:存在 S_AXI、AXI_STR_RXD、AXI_STR_TXD 三组端口,有三种使用模式:AXI_STR_RXD(输入) + S_AXI(输出),此时等价于一个 AXIS → MM 桥接 FIFO;S_AXI(输入) + AXI_STR_TXD(输出),此时等价于 MM → AXIS 桥接 FIFO;AXI_STR_RXD(输入) + AXI_STR_TXD(输出),此时相当于纯 AXI Stream FIFO,与 AXI Stream Data FIFO 一样。
- AXI4-Stream Accelerator Adapter:含有 AXI4-Stream 接口、AXI4-Lite 接口、BRAM/FIFO 接口、标量接口。支持非对称多缓冲数据宽度,允许 AXI4-Stream 和 BRAM/FIFO 接口之间的灵活数据宽度转换(S2M、M2S、M2M、FIFO2S、S2FIFO)。其中 S_AXI 为 AXI4-LITE 接口;S_AXIS_n、M_AXIS_n 均为 AXI-Stream 接口;AP_CTRL 为与加速器握手的信号组;AP_BRAM_IARG_n 和 AP_BRAM_OARG_n 分别为 BRAM 的输入和输出端口,需连接到 Block RAM Controller 或自己设计的 BRAM IP。
- AXI DataMover:通过操作 AXI-stream 接口操作 PS 端 DDR。对于写 DDR(数据由 PL 端产生,通过操作 AXI-stream,AXI-stream 协议转换成 AXI4,AXI4 操作 HP 接口,从而写入 DDR);对于读 DDR(数据通过 HP 接口读出到 AXI4,AXI4 转协议 AXI-stream,PL 读取 AXI-stream 的结果)。与 AXI DMA 的区别在于 DataMover 不需要 CPU 初始化 DMA,PL 为绝对主控。
- AXI Direct Memory Access:AXI4-Lite 用于对寄存器进行配置,M_AXI_MM2S 用于 AXI4 Memory Map Read(读内存写加速器),M_AXI_S2MM 用于 AXI4 Memory Map Write(读加速器写内存)。S_AXIS-S2MM(fifo 往 dma 写数据);M_AXI_S2MM(ddr 从 dma 读数据);M_AXIS_MM2S(dma 往 fifo 写数据);M_AXI_MM2S(dma 从 ddr 读数据 )。AXI DMA 是 AXI memory-mapped ↔ AXI-Stream 之间的桥梁,负责在地址空间和流式接口之间转化。DMA 通道有 MM2S 和 S2MM,分别负责两个方向。大部分使用 AXI DMA 的场景,都涉及 PL 与 PS 的数据交互,少部分的情况下,纯 PL 也有用到 AXI DMA 的场景,比如 HLS IP 需要一次处理上万点的 FFT 输入,图像处理需要 1280*720 一帧图像作为输入,CNN IP 需要一整块 feature map,即数据并不是逐拍的流式接口能传输的,而是需要将数据存储在一块 Memory 中,这时就需要用到 AXI DMA 来搬运。另外,PS 端也有 DMA,STM32 中提到的 DMA 就是这种,用于内存和外设之间的数据交互,不支持流式接口。AXI Multi Channel Direct Memory Access 为 AXI DMA 的多通道版。
- AXI Memory Mapped to Stream Mapper:单方向的 MM2S