

FPGA系列(3)
Xilinx FPGA硬件资源

基本单元
Xilinx FPGA 以可配置逻辑块 CLB 为基本逻辑资源单元。每个 CLB 中包含若干 Slices。最基本的 Slice 包含查找表 LUT 和触发器 Flip-Flop 资源。LUT 是存储真值表的介质,也可用作分布式 RAM 作为快速高效的 on-chip memory。LUT 由 MUX 树和 SRAM 构成,工作时由输入信号控制 MUX 树,从 SRAM 配置位中选中一个值输出。以四输入的 LUT 为例,使用 15 个 MUX2 分为四层(8-4-2-1)来实现十六选一的结构,SRAM 中存储 16 个位对应应该存储的二进制值即可。
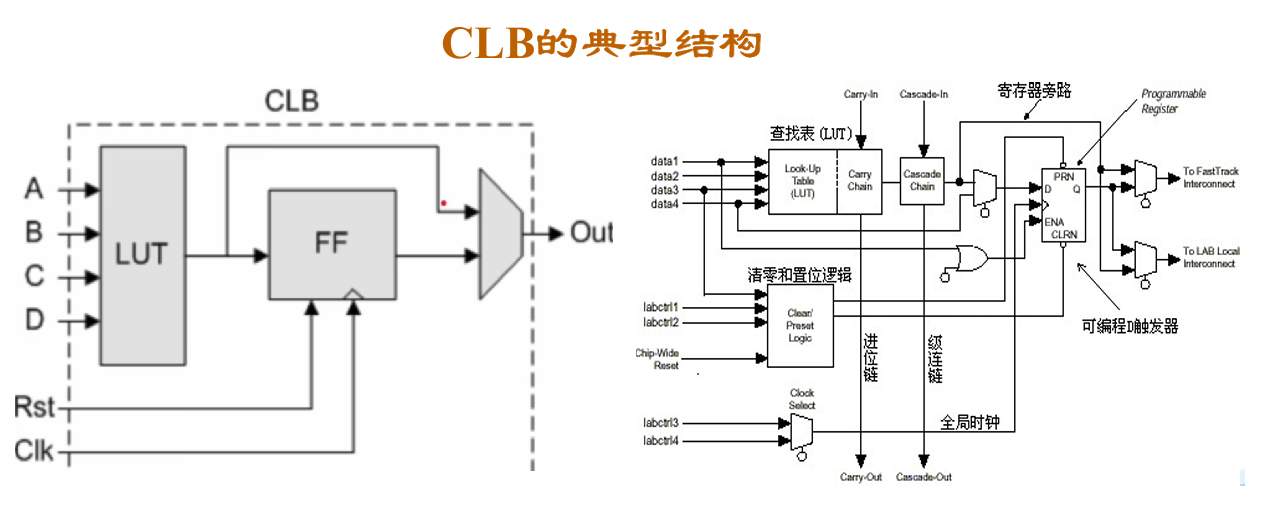
今天的 Xilinx FPGA 中,除了上述基本单元之外,还集成了 IO Blocks(输入输出物理接口)、嵌入式 Block RAM(存储资源)、PLL(高速时钟信号)、Global Clock Buffers(时钟布线资源)、DSP Blocks(数字信号处理)、SERDES(高速接口)、CPU(硬核处理器)、NPU(硬核 AI 推理)以及配套的多路选择器 Mux、进位链 Carry Chain、局部互联资源等。集成这些硬核单元设计出这样的架构,是基于解决实际问题和成本效率综合考量后,高度优化的结果。
存储资源
存储资源分为 Distributed RAM 和 Block RAM,前者使用 CLB 资源,后者是器件上专用的块状存储资源。高端的芯片除了这种中 RAM 之外,还会配备 Ultra RAM 资源。Ultra RAM 是大容量、省 LUT 的片上 RAM,数量少且延迟略高,适合作大缓存使用。
Block RAM(BRAM)是 FPGA 中固化的硬件存储单元,固定容量为 18K bits(18432 bits),可以单独使用也可以两个相邻的 18k BRAM 组合成双口 36k BRAM。设计中调用的资源以 BRAM 为最小单位,向上取整。例如存储位宽为 16 位,数据深度为 512,总共占用 16*512 = 8192 bits = 1KBytes。数据宽度指一个数据占用的 bit 位数,数据深度指可以存放的数据个数。数据深度与地址线宽度有关,如数据深度为 512,则对应的地址线为 9 位,\(2^9=512\)。
这些物理存储结构被抽象为逻辑存储结构,最常用的是 RAM、ROM 和 FIFO。
- RAM 和 ROM 中任意一个存储单元都可以在相同时间内被访问,硬件上由存储单元阵列 + 地址译码器 + 读写电路构成;ROM 由 RAM 配合要预先写入的 coe 文件实现。
- FIFO 是先进先出队列存储器,内部常用环形缓冲区的结构,由 RAM+读写指针实现。FIFO 没有地址的概念,写入只能写到队尾,读出只能从队首读取,硬件自动维护顺序,读写顺序固定。读写对象为内部读写指针指向的存储单元,读写时操作指针位置,由 full、empty 信号进行数据流控制。根据读写时钟是否相同分为同步 FIFO 和异步 FIFO。FIFO 的容量一般比较小,广泛用于数据的缓存、平衡异步时钟域之间的速度差、流式数据接口缓存等。
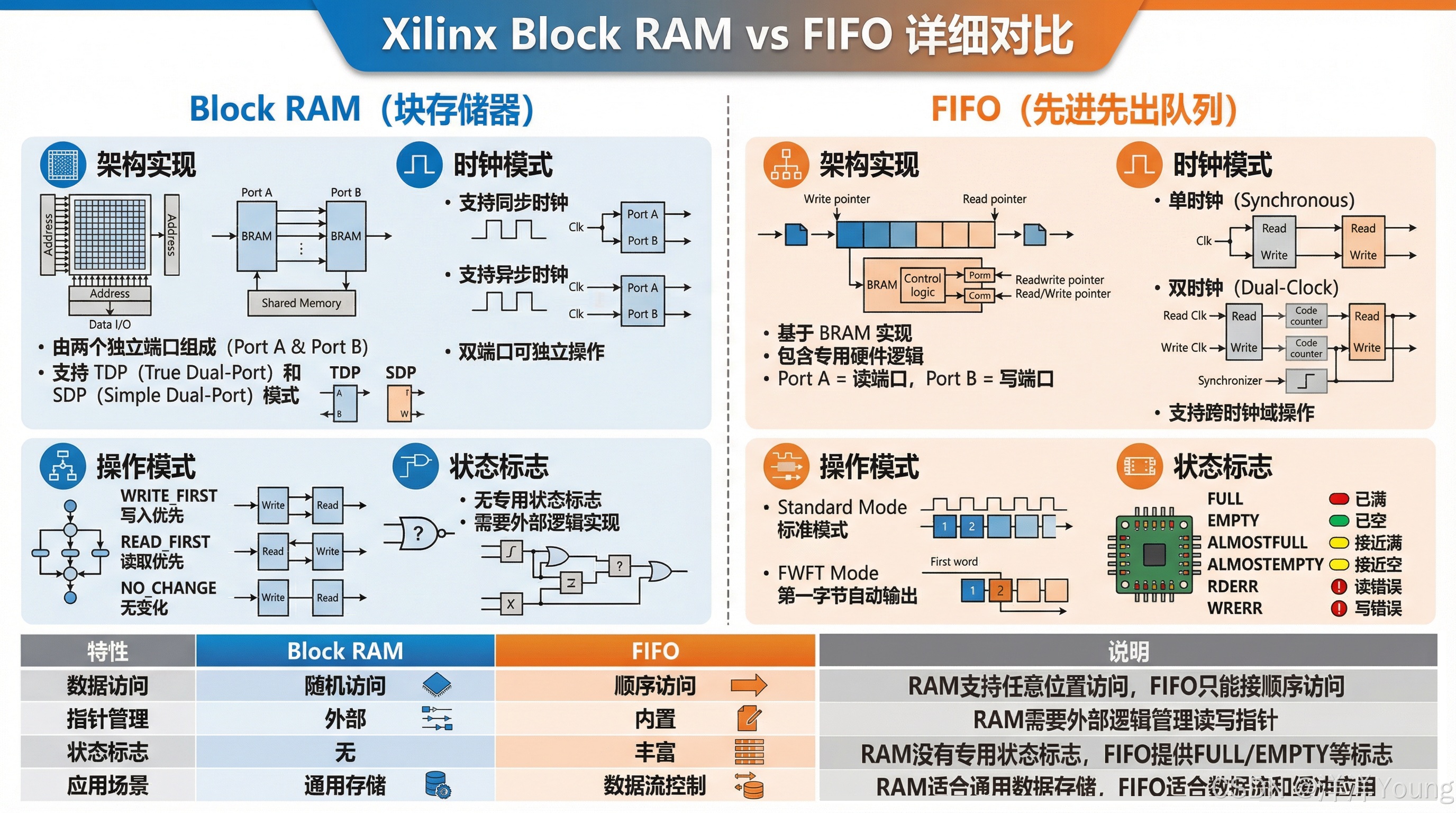
这些逻辑存储结构的实现原理了解即可,Xilinx 对它们均提供了成熟的 IP 供开发者使用。RAM 和 ROM 的 IP 有 Distributed Memory Generator 和 Block Memory Generator 两个,区别在于使用的 FPGA 资源不同,由 Distributed Memory Generator 生成的 RAM/ROM Core 占用的资源是 CLB 中的 LUT;而由 Block Memory Generator 生成的 RAM/ROM Core 占用的资源是专用的存储资源 Block Memory。FIFO 的 IP 有 FIFO Generator,实现资源分时钟域和存储资源两方面,时钟域有同步和异步之分,存储资源可选 BlockRAM、Distributed RAM、Shift Reg、Built-in FIFO。
运算资源
DSP 单元是专用于做高速运算的硬件资源,对乘法和累加操作做了针对性的优化,支持二进制补码操作,运算功能丰富。为了保证运算速度,DSP 单元在芯片上通常会与 Block RAM 对称布置。DSP Slice 是 DSP48 系列硬核的最小功能模块,是构成复杂 DSP 单元的基础,集成了高速乘法器、加法器、累加器、多路选择器和控制逻辑等最核心的算术运算组件。
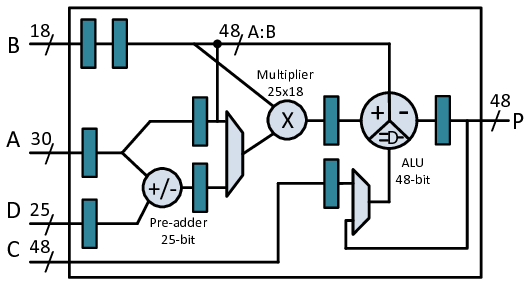
一些运算类的 IP,实现方式可以选用 Fabric 和 DSP48,前者是查找表、触发器、多路选择器等 FPGA 通用的逻辑资源,功能灵活但没有做针对性的优化,适用于简单逻辑运算(如小规模加法、逻辑门组合)和控制类电路。后者是专用的硬核数字信号处理器,针对高速算术运算做了硬件优化,资源高效(一个 DSP48 可替代数百个 LUT 实现乘法),适用于 FIR/IIR 滤波器、复数乘法、矩阵运算、神经网络加速等。
时钟资源
时钟管理模块 CMT(Clock Management Tiles)是专用于产生/处理/分发时钟的硬件资源,提供了时钟合成、倾斜矫正和过滤抖动等功能,用于将外部时钟转化为 FPGA 可用的高质量时钟,CMT 中包含 PLL(Phase Lock Loop) 、MMCM(Mixed Mode Clock Manager)和 Clock Buffers。常见用法是 MMCM 调幅 + PLL 调相。
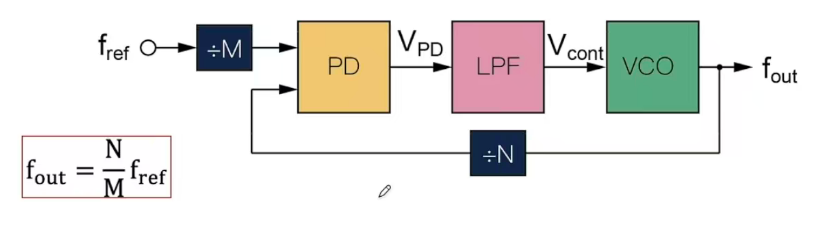
PLL 通过锁相机制使输出时钟和输入时钟相位一致,可实现分频和倍频,缺点是相位控制粒度有限。MMCM 比 PLL 功能更强,可实现分数分频/倍频和更精准的相移。MMCM 或 PLL 输出的是原始时钟信号,不能直接裸信号使用且不能走普通的布线逻辑,而需要经过专用的 buffer 电路并接入全局或区域时钟网络。buffer 电路的作用是提高驱动能力并保证延迟均衡。时钟如果走普通布线逻辑会导致延迟和 skew 无法保证,会导致严重的同步问题。时钟倾斜 skew 是指同一个时钟信号到达不同触发器的时间差。如果 skew 太大,可能导致 setup/hold 时间被破坏而引起数据寄存错误。
时钟资源有以下几种:
全局时钟资源指 FPGA 内部专门布设的低延迟、低偏斜的长距离布线网络,保证一个时钟信号可以同时驱动全芯片的逻辑,对应的 buffer 为 BUFG(Global Clock Buffer)和 BUFGCE(带使能端的 BUFG),用于驱动全局时钟,如系统主时钟、DDR 时钟等。
区域时钟资源限定在芯片的一部分,对应的 buffer 为 BUFH(Horizontal buffer)、BUFR(Regional buffer)和 BUFHCE(带使能端的 BUFH),用于驱动局部时钟,减少功耗和浪费。
此外还有 IBUFG (Input BUFG),用于将外部引脚的时钟(从 IO pin 来的时钟)送入 FPGA 内部的全局/区域时钟网络。
IO 资源
FPGA 芯片的管脚被划分为多个 IO Bank,每个 Bank 有一组外部供电的电源引脚。Bank 是可编程逻辑芯片中对芯片内功能相近或关联的硬件资源进行物理分区和管理的单元,每个 Bank 有独立的电平标准。在进行引脚分配时,必须先明确每个 IO Bank 的电源电平、支持的接口标准和资源限制(如是否带 PLL)。
互联资源
FPGA 内部有大量可编程的互连资源,包含可编程布线网络和可编程交换开关,逻辑单元之间的信号通过这些布线网络和开关连接,称为布线逻辑 (routing fabric),结构如图。
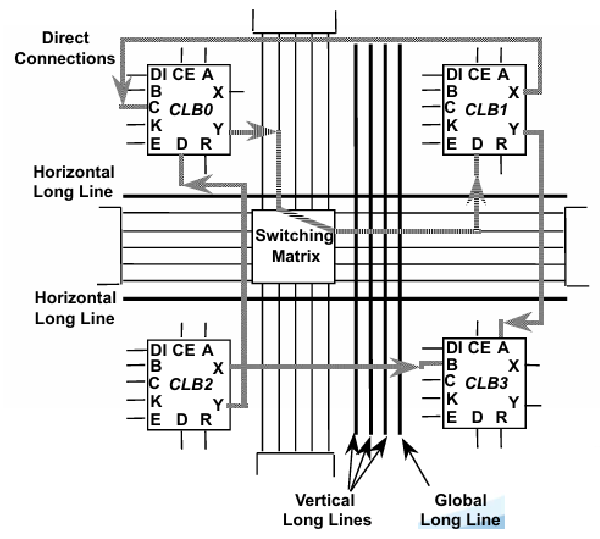
普通布线逻辑指通用的互连通道,用来传数据/控制信号。它们延迟大、路径长短不一、受布线工具优化影响。时钟信号需要使用专用的时钟 buffer 和时钟布线网络来控制 skew。
互联资源用于解决芯片内部连接,而在多颗 FPGA 硅片之间,有堆栈硅互联(SSI)技术来将多颗芯片在封装层面拼成一个超大 FPGA。