

Verilog 语法
知识储备

Verilog HDL(简称 Verilog)是一种硬件描述语言,用于数字电路的系统设计和仿真,同一语言可用于生成模拟激励,以及指定测试的约束条件。Verilog 可对算法级、门级、开关级等多种抽象设计层次进行建模,使用模块实例化可描述任何层次;主要有三种建模的描述风格:行为级描述——使用过程化结构建模;数据流描述——使用连续赋值语句建模;结构化方式——使用门和模块例化语句描述。
Verilog 可用 primitive 创建自定义原语(UDP),既可以是组合逻辑,也可以是时序逻辑。Verilog 还支持其他编程语言接口(PLI)进行进一步扩展,PLI 允许外部函数访问 Verilog 模块内部信息。Verilog 的语法与 C 语言很类似,相同的语法只在此处简单罗列:区分大小写。空格没有实际意义。每个语句以分号结束。注释用双斜线。标识符的第一个字符必须是字母或者下划线。关键字是预留的用于定义语言结构的特殊标识符,Verilog 中关键字全部为小写。表达式由操作符和操作数构成,可以在出现数值的任何地方使用。操作符及其优先级顺序同 C 语言。
数值表示
Verilog 有下列四种基本的值来表示硬件电路中的电平逻辑:
- 0:逻辑 0 或 “假”
- 1:逻辑 1 或 “真”
- x 或 X:未知,信号数值的不确定
- z 或 Z:高阻,常见于信号没有驱动时的逻辑结果,其逻辑值和上下拉的状态有关系
声明数值的规范格式为位宽(二进制位的数量) + 基数 + 数值。
位宽:声明数值可选择是否指明位宽,建议显式指明位宽(尤其是负数)以降低调试难度。指定位宽时注意不要让结果溢出,如无符号数乘法的结果变量位宽应该声明为 2 个操作数的位宽之和。
基数:不指定时默认为十进制。数值相同的情况下,不同基数格式完全等效。
1
2
3
4
1'b0;
4'd3;
6'sd-15; // 负数建议显式指定位宽; s表示有符号数。
6'b11_0001; // 较长的数值建议每四位加下划线
数据类型
wire 和 reg
在 verilog 中,变量分为网线型(net)和过程型(variable)两类。net 用于表示信号的物理连接,必须由驱动源(门、模块输出、连续赋值 assign)来驱动;variable 只能在过程块中被赋值,有阻塞赋值=和非阻塞赋值<=。最常用的网线型变量和过程型变量分别是 wire 和 reg,其余类型可以理解为这两种数据类型的扩展或辅助,并且在入门阶段均不常见,此处不作介绍。
- wire 表示硬件单元之间的物理连线,用于连接驱动源(提供值的地方)和被驱动端口(接收值的地方),抽象为电路中的导线。wire 由其连接的器件输出端连续驱动,即驱动源变化,wire 立即变化。典型的驱动源包括原语/模块的输出、连续赋值语句 assign 等。没有驱动元件连接到 wire 型变量时,其缺省值为 “Z”。wire 可以在定义时赋值或定义后用 assign 赋值;但无论哪种方式,由于 wire 型变量由其它电路驱动,每个 wire 变量最多只能有一个驱动源,因此只能被赋值一次。不声明数据类型时,wire 为默认的数据类型,可以设置
default_nettype none来强制提醒编程时显式声明变量类型,降低 debug 难度。 - reg 表示存储单元,会保持数据原有的值直到被改写,不需要驱动源。reg 只能在过程块中被赋值,初始化的 reg 在仿真开始为 X,默认为无符号数。reg 在时钟敏感表的过程块中赋值时被综合为触发器,而在组合敏感的过程块中赋值且所有分支对它都有输出时,被综合成组合逻辑网络(即门电路+导线)。
向量
变量可以被声明为向量的形式,可以通过索引或指定 bit 位后固定位宽的向量域选定向量的某一位或若干相邻位进行操作,语法为[bit+: width]或[bit-: width],表示从起始 bit 位开始递增或递减 width 位。此外,Verilog 支持可变的向量域选择。
1
2
3
4
5
6
7
8
9
10
11
// 向量声明
reg [31:0] data1;
output reg [0:0] y; // 1-bit 也是向量类型
input wire [3:-2] z; // 6-bit 的向量,允许负数向量域
wire [0:7] b; // b[0]为最高权重位,但一个程序中的大小端最好保持一致,以免出现奇怪的bug
// 指定向量域
A = data1[31:24];
A = data1[31-:8];
B = data1[0:7];
B = data1[0+:8]
拼接和重复:Verilog 支持对操作数位宽的自动扩展,以及对运算结果的合理拼接,这使得可以用assign {cout, sum} = a + b + cin; 这样简单直观的方向实现加法器,但另一方面,也需要注意自动扩展的位宽可能导致的潜在问题。拼接操作符用大括号表示,操作数必须指定位宽。拼接时需要注意位宽和顺序;一般拼接右值,左值按完整变量写,除非左值同时赋值多个变量意义明确,如这里举例的加法器。
1
2
3
4
5
6
7
8
9
// 用大括号可将信号组合成向量
wire [31:0] temp1, temp2;
assign temp1 = {byte1[0][7:0], data1[31:8]};
assign temp2 = {32{1'b0}};
// 可以用常数数字表示重复,注意被重复的部分和整个结果都需要加大括号
{5{1'b1}}
{2{a,b,c}}
{3'd5, {2{3'd6}}}
数组
在 Verilog 中允许声明 reg, wire, int, time, real 及其向量类型的数组。数组维数没有限制。数组中的每个元素都可以作为一个标量或者向量,形如:<数组名>[<下标>]。多维数组需要说明其每一维的索引。数组与向量的访问方式在一定程度上类似,但两者是截然不同的数据结构。向量是一个单独的元件,位宽为 n;数组由多个元件组成,其中每个元件的位宽为 n 或 1,比如存储器变量就是用于描述 RAM 或 ROM 行为的寄存器数组。
1
2
3
4
5
integer flag[7:0];
reg [3:0] counter[3:0];
wire [7:0] addr_bus[3:0];
wire data_bit[7:0][5:0];
reg [7:0] mem [255:0]; // 256 个数据,每个数据为8-bit的reg
整数和实数
整数用关键字 integer 或 int 声明,是有符号数,声明时位宽和编译器有关(一般为 32 bit)。实数用关键字 real 声明,可用十进制或科学计数法来表示,默认值为 0,不能指定位宽,因为 real 在计算机内部为双精度浮点数,位宽固定为 64 位。如果将一个实数赋值给一个整数,则只有实数的整数部分会赋值给整数。
1
2
3
4
5
6
7
8
9
10
real data1;
integer temp;
initial begin
data1 = 2e3;
data1 = 3.75;
end
initial begin
temp = data; // temp = 3
end
时间
time 型变量为 Verilog 中特殊的时间寄存器,用于保存仿真时间,其宽度一般为 64 bit,通过调用系统函数 $time 获取当前仿真时间。
1
2
3
4
5
time current_time
initial begin
#100
current_time = $time;
end
参数
参数用来表示常量,用关键字 parameter 声明,只能赋值一次,可以在实例化时覆盖,作为模块的可配置参数。与之类似的还有 localparam,用于定义不可被覆盖的常量,作为模块内部的固定值,作为辅助计算的局部常量。
1
2
3
parameter data_width = 10'd32;
parameter i=1, j=2, k=3;
parameter mem_size = data_width * 10;
字符串
字符串是由双引号包起来的单字节(8bit) ASCII 字符队列,保存在 reg 类型的变量中。注意寄存器变量的宽度应该足够大以保证不会溢出,如果寄存器变量的宽度大于字符串的大小,则使用 0 来填充左边的空余位;如果寄存器变量的宽度小于字符串大小,则会截去字符串左边多余的数据。
1
2
3
4
reg [0:14*8-1] str;
initial begin
str = "www.runoob.com";
end
操作数和操作符
只介绍 C 语言中没有或存在差异的部分。
操作数可以是任意的数据类型,只是某些特定的语法结构要求使用特定类型的操作数,比如过程块中不能为 wire 类型变量赋值。
算术操作符和关系操作符中,如果操作数某一位为 x,则计算结果为 x。
逻辑操作符的计算结果是一个 1bit 的值。如果一个操作数不为 0,则等价于逻辑 1;如果一个操作数等于 0,则等价于逻辑 0。如果它任意一位为 x 或 z,则等价于 x。
推荐使用更安全的===来减少 bug 风险(判断前不作类型转换)。全等比较时,如果按位比较有相同的 x 或 z,返回结果也可以为 1,因此全等比较的结果一定不包含 x。
按位操作符对 2 个操作数的每 1bit 数据进行按位操作。如果 2 个操作数位宽不相等,则用 0 向左扩展补充较短的操作数。
归约操作符只有一个操作数,作用是对单个向量操作数进行逐位操作,最终得到 1 位结果 ,常用来判断向量中某些位的整体特征(如是否全 1、是否有 1 等)。
1 2 3
& a[3:0] // AND: a[3]&a[2]&a[1]&a[0]. Equivalent to (a[3:0] == 4'hf) | b[3:0] // OR: b[3]|b[2]|b[1]|b[0]. Equivalent to (b[3:0] != 4'h0) ^ c[2:0] // XOR: c[2]^c[1]^c[0]
部分逻辑操作符、按位操作符和归约操作符使用相同的符号表示,由作用的操作数数量和计算结果(即上下文)加以区分。
“左移” 一般默认指逻辑左移,逻辑左移和算术左移的区别在于对有符号数符号位的处理。逻辑左移将二进制数当无符号数处理,所有位包括最高位均左移,右侧补 0;算术左移将二进制数当有符号数处理,保留符号位不变仅对数值位左移,右侧补 0。逻辑右移和算术右移类似,逻辑右移时左边高位补 0;算术右移时左边高位补符号位,以保证数据缩小后值的正确性。
赋值方式
Verilog 中有连续赋值和过程赋值两类赋值方式。连续赋值即使用assign,过程赋值即在过程块中用阻塞赋值=或非阻塞赋值<=。
连续赋值
简单的组合逻辑用连续赋值建模。连续赋值代表并行的硬件,任何操作数的改变都影响表达式的结果,适合建模硬件导线关系,始终生效。过程赋值必须驱动 wire 类型。
过程赋值
复杂的组合逻辑或时序逻辑用过程赋值建模。过程赋值只有在语句执行的时候,才会起作用。过程赋值必须驱动 reg 类型变量,这些变量在被赋值后,其值将保持不变,直到重新被赋予新值。但一些综合工具存在隐式类型转换特性,当输出端口被声明为 wire,但在 always 块中被赋值时,综合工具会自动将 out 视为 reg 类型。
过程赋值分阻塞赋值与非阻塞赋值两种。阻塞赋值=属于顺序执行语句,即下一条语句执行前,当前语句一定会执行完毕。在过程块中会立即更新目标变量的值。非阻塞赋值<=属于并行执行语句,即下一条语句的执行和当前语句的执行是同时进行的,它不会阻塞位于同一个语句块中后面语句的执行。在时钟沿触发的过程块中,非阻塞赋值不会立即生效,而是将所有触发所有满足触发条件的always块的所有非阻塞赋值语句放入队列中,然后统一按队列顺序执行更新。
不要在一个过程块中混合使用阻塞赋值与非阻塞赋值,因为时序不易控制,容易得到意外结果。always @ (posedge/negedge clk) 时序逻辑块中使用非阻塞赋值,always @ (*) 组合逻辑块中使用阻塞赋值;initial 块用阻塞赋值。另外还有过程连续赋值,综合工具不支持,只在仿真中使用,初学阶段一般接触不到,此处不作介绍。
过程块
过程块包括initial ... end、always @ (posedge/negedge clk)、always @ (*)三种,在特定条件触发时执行一次块中的语句。一个过程块产生一个独立的控制流,执行时间均从 0 时刻开始。initial 执行一次,多用于初始化;always 重复执行,多用于仿真时钟的产生,信号行为的检测等。过程块中括号部分的内容称为敏感表,用于明确哪些信号发生变化时需要触发执行这个过程块。
过程块不支持嵌套,但一个module中支持多个过程块。各个过程块并行执行且相互独立,因此一个变量不能在多个 always 块中被赋值,否则导致多重驱动冲突。
语句块
过程块中可以使用顺序块和并行块两种类型的语句块。顺序块用关键字 begin 和 end 表示,其中的语句串行执行(非阻塞赋值除外),每条语句的时延与前面语句执行的时间相关。并行块用关键字 fork 和 join 表示。其中的语句并行执行(即使是阻塞赋值),每条语句的时延与块语句开始执行的时间相关。顺序块和并行块可以嵌套使用。
命名块
可以给语句块命名,命名块中可以声明局部变量,并可以通过层次名引用的方法访问。
1
2
3
4
5
6
7
8
9
10
11
`timescale 1ns/1ns
module test;
initial begin: runoob //命名模块名字为runoob
integer i ; //此变量可以通过test.runoob.i 被其他模块使用
i = 0 ;
forever begin
#10 i = i + 10 ;
end
end
endmodule
disable 可以终止设计中任何一个命名块的执行,用于从循环中退出、处理错误等,与 C 语言中的 break 类似。disable可退出当前的 while块,但 disable 在 always 或 forever 块中使用时只能退出当前回合,下一次语句还是会在 always 或 forever 中执行,类似 C 语言中的 continue。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
`timescale 1ns/1ns
module test;
initial begin: runoob_d
integer i_d ;
i_d = 0 ;
while(i_d<=100) begin: runoob_d2
# 10 ;
if (i_d >= 50) begin
disable runoob_d3.clk_gen ;//stop 外部block: clk_gen
disable runoob_d2 ; //stop 当前block: runoob_d2
end
i_d = i_d + 10 ;
end
end
reg clk ;
initial begin: runoob_d3
while (1) begin: clk_gen
clk=1 ; #10 ;
clk=0 ; #10 ;
end
end
endmodule
控制流语句
控制流语句的使用和 C 语言基本相同,在过程块中使用。对于任何控制流语句,建议使用 begin 与 end 关键字,编译器一般按就近原则编译,不加 begin 与 end 关键字可能导致不安全的行为。
条件语句
1
2
3
4
5
6
7
8
9
if (condition1) begin
true_statement1;
end
else if (condition2) begin
true_statement2;
end
else begin
default_statement;
end
多路分支语句
条件选项是并发比较的,执行效果为谁在前且条件为真谁被执行,因此条件选项不要求互斥。default 语句可选,但建议加上以避免隐式引入锁存器增加 debug 难度;另外,一个 case 语句中不能有多个 default 语句。多个条件选项下需要执行相同的语句时,条件选项之间用逗号分开,放在同一个语句块的候选项中。
case 语句中的条件选项表单式不必都是常量,也可以是 x 值或 z 值,但 case 语句中的 x 或 z 的比较逻辑是不可综合的,所以一般不建议在 case 语句中使用 x 或 z 作为比较值。casex、 casez 语句是 case 语句的变形,用来表示条件选项中的无关项。casex 用 “x” 来表示无关值,casez 用问号 “?” 来表示无关值。两者功能是完全一致的,语法与 case 语句也完全一致。但是 casex、casez 一般是不可综合的,多用于仿真。
1
2
3
4
5
6
7
8
9
10
11
12
13
case (case_expr)
condition1: begin
true_statement1;
end
condition2, condition3: begin
true_statement2;
end
default: begin
default_statement;
end
endcase
循环语句
有 while,for,repeat,和 forever 循环四种类型,只能在 always 或 initial 块中使用,可以包含延迟表达式。
while 和 for 的用法同 C 语言。
repeat 的功能是执行固定次数的循环,不能像 while 循环那样用一个逻辑表达式来确定循环是否继续执行。repeat 循环的次数必须是一个常量、变量或信号。如果循环次数是变量信号,则循环次数是开始执行 repeat 循环时变量信号的值。即便执行期间,循环次数代表的变量信号值发生了变化,repeat 执行次数也不会改变。
forever 语句表示永久循环,不包含任何条件表达式,一旦执行便无限的执行下去,系统函数 $finish 可退出 forever。forever 相当于 while(1) 。通常,forever 循环是和时序控制结构配合使用的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
while (condition) begin
…
end
for(initial_assignment; condition ; step_assignment) begin
…
end
repeat (loop_times) begin
…
end
forever begin
…
end
避免锁存器
语法正确的代码未必能生成合理的电路(组合逻辑 + 触发器),核心原因是未明确指定所有条件下的输出结果,比如组合逻辑中存在没有赋值的分支。在 Verilog 中,当代码未覆盖所有输入情况时,工具会默认保持输出不变,即需要电路存储当前状态而引入时序逻辑,隐式地综合处锁存器。锁存器是电平触发的存储单元,使能信号有效时相当于导线,容易引起竞争和冒险,在现代数字电路设计中被认为存在潜在危险;除非锁存器是刻意设计的,否则通常意味着代码存在 bug。组合电路必须确保所有输出在所有输入条件下都有确定值,具体实现方式包括:必须使用 else 子句、为输出设置默认值等。
模块和端口
模块声明
结构建模方式有三类描述语句: Gate(门级)例化语句,UDP (用户定义原语)例化语句和 module (模块) 例化语句,此处介绍最常用的 module,module 定义的语法格式如下
1
2
3
4
5
module module_name
#(parameter_list)
(port_list);
// Declarations and Statements;
endmodule
对模块的调用通过端口连接进行。模块的定义中包含一个可选的端口列表,建议在声明端口时完整描述端口类型和端口数据类型。端口类型按照端口信号的方向分为 input、output 和 inout 三种。input 和 inout 由外部信号驱动,需要实时反映外部信号变化,不能声明为只在过程赋值时才更新的 reg 类型;output 则可以声明为 wire 或 reg 数据类型。另外,一个模块如果和外部环境没有交互,则可以不用声明端口列表。
1
2
3
4
5
6
7
module pad(
input wire DIN, OEN,
input [1:0] wire PULL,
input wire PAD,
output reg DOUT);
// Statements
endmodule
模块例化
在一个模块中引用另一个模块并对其端口进行连接,叫做模块例化。信号端口可以通过位置或名称关联(建议使用名称关联)。
顺序端口连接:将需要例化的模块端口按照声明时的顺序与外部信号连接。代码不易维护,不建议采用。
命名端口连接:将需要例化的模块端口与外部信号按端口名字连接,端口顺序随意。如果某些端口不需要在外部连接,例化时可以悬空不连接(.()留空)。
1
2
3
4
5
6
full_adder u_adder0(
.Ai(a[0]),
.Bi(b[0]),
.Ci(c==1'b1 ? 1'b0 : 1'b1),
.So(so_bit0),
.Co(co_temp[0]));
端口连接规则:
输入端口:从模块外部来讲, input 端口可以连接 wire 或 reg 型变量,但模块声明时必须是 wire 型变量。
输出端口:从模块外部来讲,output 端口必须连接 wire 型变量,但模块声明时可以是 wire 或 reg 型变量。
输入输出端口:从模块外部来讲,inout 端口必须连接 wire 型变量,模块声明时同样。
悬空端口:不需要与外部信号进行连接交互的信号可以悬空,即端口例化时留空。output 端口悬空时甚至可以删除;input 端口悬空时,悬空信号的逻辑功能表现为高阻状态(逻辑值为 z),但不能删除。建议 input 端口不要悬空,无其他外部连接时赋值为常量即可。
例化端口与连续信号位宽不匹配时,端口会通过无符号数的右对齐或截断方式进行匹配。
generate 例化
当例化多个相同的模块时,使用 generate 语句进行多个模块的重复例化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
module full_adder4(
input [3:0] a , // adder1
input [3:0] b , // adder2
input c , // input carry bit
output [3:0] so , // adding result
output co // output carry bit
);
wire [3:0] co_temp ;
// 此处第一个例化模块格式有所差异,需要单独例化
full_adder1 u_adder0(
.Ai (a[0]),
.Bi (b[0]),
.Ci (c==1'b1 ? 1'b1 : 1'b0),
.So (so[0]),
.Co (co_temp[0]));
genvar i ;
generate
for(i=1; i<=3; i=i+1) begin: adder_gen
full_adder1 u_adder(
.Ai (a[i]),
.Bi (b[i]),
.Ci (co_temp[i-1]), // 上一个全加器的溢位是下一个的进位
.So (so[i]),
.Co (co_temp[i]));
end
endgenerate
assign co = co_temp[3] ;
endmodule
带参数例化
当一个模块被另一个模块引用例化时,高层模块可以对低层模块的参数值进行覆盖。这样在编译时可将不同的参数传递给多个相同名字的模块,而不用单独为只有参数不同的多个模块再新建文件。参数覆盖有两种方式:第一种是用关键字 defparam 通过模块层次调用的方法,在例化时改写低层次模块的参数值;第二种是例化模块时,将新的参数值写入模块例化语句,以此来改写原有 module 的参数值。建议使用第二种方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// module defination
module ram
#( parameter AW = 2 ,
parameter DW = 3 )
(
input CLK ,
input [AW-1:0] A ,
input [DW-1:0] D ,
input EN ,
input WR ,
output reg [DW-1:0] Q
);
// 省略内部逻辑
endmodule
// instantiation
ram #(.AW(4), .DW(4)) u_ram(.CLK(clk), .A(a[AW-1:0]), .D(d), .EN(en), .WR(wr), .Q(q));
函数和任务
Verilog 中用函数和任务的机制来提取封装重复的行为级设计,避免重复代码的多次编写。
函数只能在模块中定义,位置任意,可在模块的任何地方引用,作用范围也局限于此模块。函数有以下特点:不含有任何延迟、时序或时序控制逻辑,也不含有非阻塞赋值;至少有一个输入变量且输入端口声明不能包含 inout,有且只有一个返回值(函数名本身对应的值),没有输出;函数可以调用其它函数,但不能调用任务;函数总在零时刻就开始执行;函数不能单独作为一条语句出现,而只能作为赋值语句的右值。下面是一个用函数实现数据大小端转化的例子。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
module endian_rvs
#(parameter N = 4)
(
input en, //enable control
input [N-1:0] a ,
output [N-1:0] b
);
reg [N-1:0] b_temp ;
always @(*) begin
if (en) begin
b_temp = data_rvs(a);
end
else begin
b_temp = 0 ;
end
end
assign b = b_temp ;
// function entity
function [N-1:0] data_rvs (
input [N-1:0] data_in
);
parameter MASK = 32'h3;
integer k;
begin
for(k=0; k<N; k=k+1) begin
data_rvs[N-k-1] = data_in[k];
end
end
endfunction
endmodule
常数函数是指在仿真开始之前,在编译期间就计算出结果为常数的函数。常数函数不允许访问全局变量或者调用系统函数,但是可以调用另一个常数函数。这种函数能够用来引用复杂的值,因此可用来代替常量。
1
2
3
4
5
6
7
8
9
10
parameter MEM_DEPTH = 256 ;
reg [logb2(MEM_DEPTH)-1: 0] addr ; //可得addr的宽度为8bit
function integer logb2;
input integer depth ;
//256为9bit,我们最终数据应该是8,所以需depth=2时提前停止循环
for(logb2=0; depth>1; logb2=logb2+1) begin
depth = depth >> 1 ;
end
endfunction
一般函数的局部变量是静态的,即每次调用时,函数的局部变量都使用同一个存储空间。若某个函数在两个不同的地方同时并发的调用,那么两个函数调用行为同时对同一块地址进行操作,会导致不确定的函数结果。使用关键字 automatic 修饰函数,调用时可以自动分配新内存空间。automatic 函数中声明的局部变量不能通过层次命名进行访问,但是 automatic 函数本身可以通过层次名进行调用。
1
2
3
4
5
6
7
8
wire [31:0] results3 = factorial(4);
function automatic integer factorial ;
input integer data ;
integer i ;
begin
factorial = (data>=2)? data * factorial(data-1) : 1 ;
end
endfunction
任务也用于描述共同的代码段,在模块内任意位置定义和调用,作用范围局限于此模块。函数一般用于组合逻辑的各种转换和计算,而任务则是一个过程,不仅可实现函数的功能,还可以包含时序控制逻辑。任务有以下特点:不能出现 always 语句,但可以包含其它时序控制;可以没有或者有多个输入,输入端口声明可以包含 inout,没有返回值,可以没有或有多个输出;任务可以调用函数和任务;任务可以在非零时刻开始执行;任务可以作为一条单独的语句出现在语句块中。任务调用时,端口必须按顺序对应。
进行任务的逻辑设计时,可以把 input 声明的端口变量看做 wire 型,把 output 声明的端口变量看做 reg 型,但无需用 reg 对 output 端口再次说明(当然也可以注明)。对 output 信号赋值时不要用关键字 assign 而建议采用阻塞赋值来避免时序错乱。task 最多的应用场景是用于 testbench 中进行仿真。另外,task 在一些编译器中不支持综合。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
`timescale 1ns/1ns
module test ;
reg clk, rstn ;
initial begin
rstn = 0 ;
#8 rstn = 1 ;
forever begin
clk = 0 ; # 5;
clk = 1 ; # 5;
end
end
reg [3:0] a, b;
wire [3:0] co ;
initial begin
a = 0 ;
b = 0 ;
sig_input(4'b1111, 4'b1001, a, b);
sig_input(4'b0110, 4'b1001, a, b);
sig_input(4'b1000, 4'b1001, a, b);
end
task sig_input ;
input [3:0] a ;
input [3:0] b ;
output [3:0] ao ;
output [3:0] bo ;
@(posedge clk) ;
ao = a ;
bo = b ;
endtask ; // sig_input
xor_oper u_xor_oper
(
.clk (clk ),
.rstn (rstn ),
.a (a ),
.b (b ),
.co (co ));
initial begin
forever begin
#100;
if ($time >= 1000) $finish ;
end
end
endmodule // test
任务可以看作过程型赋值,任务的 output 端信号在任务中所有语句执行完毕后才会返回。任务的内部变量只在任务中可见,如果需要观察任务对变量的操作过程,则需要将变量声明在任务之外模块之内,即全局变量。
与函数类似,任务调用时的局部变量都是静态的,可以用 automatic 关键字修饰,任务调用时各存储空间可以动态分配,各个调用的任务各自独立地对自己的地址空间进行操作,可以并发执行多个相同的任务。否则并行的任务对同一个地址空间操作,则信号之间会出现干扰,出现不确定的结果。
竞争和冒险
在组合逻辑电路中,不同路径的输入信号变化传输到同一点门级电路时,在时间上有先有后,这种先后所形成的时间差称为竞争(Competition)。由于竞争的存在,输出信号需要经过一段时间才能达到期望状态,过渡时间内可能产生瞬间的错误输出,例如尖峰脉冲。这种现象被称为冒险(Hazard)。竞争不一定有冒险,但冒险一定会有竞争。
在编程时多注意以下几点,也可以避免大多数的竞争与冒险问题。1)时序电路建模时,用非阻塞赋值。2)组合逻辑建模时,用阻塞赋值。3)在同一个 always 块中建立时序和组合逻辑模型时,用非阻塞赋值。4)在同一个 always 块中不要既使用阻塞赋值又使用非阻塞赋值。5)不要在多个 always 块中为同一个变量赋值。6)避免 latch 产生。
编译指令
以反引号开始的某些标识符是 Verilog 系统编译指令,编译指令的用法和 C 语言基本类似,包含条件编译指令、宏定义和取消、文件包含、时间单位指定等。
在 Verilog 模型中,时延有具体的单位时间表述,用 `timescale 定义时延及仿真的单位和精度,将时间单位与实际时间相关联。其中 time_precision 的大小需要小于等于 time_unit 的大小。
1
`timescale time_unit / time_precision
由于 Verilog 中没有默认的 `timescale,如果不显式指定,模块就有可能继承前面编译模块参数并导致设计出错。一个设计中的多个模块都带有 `timescale 时,则 time_precision 确定为所有模块中的最小值,其它 time_precision 都相应地换算为这个精度,time_unit 不受影响。如果有并行子模块,子模块间的 `timescale 并不会相互影响。time_precision 越小,仿真时占用内存越多,实际使用的仿真时间就越长,所以在满足需要的前提下应尽量将 time_precision 设置得大一些。
时序控制
这部分的结构层次比较多,先列出总览的思维导图
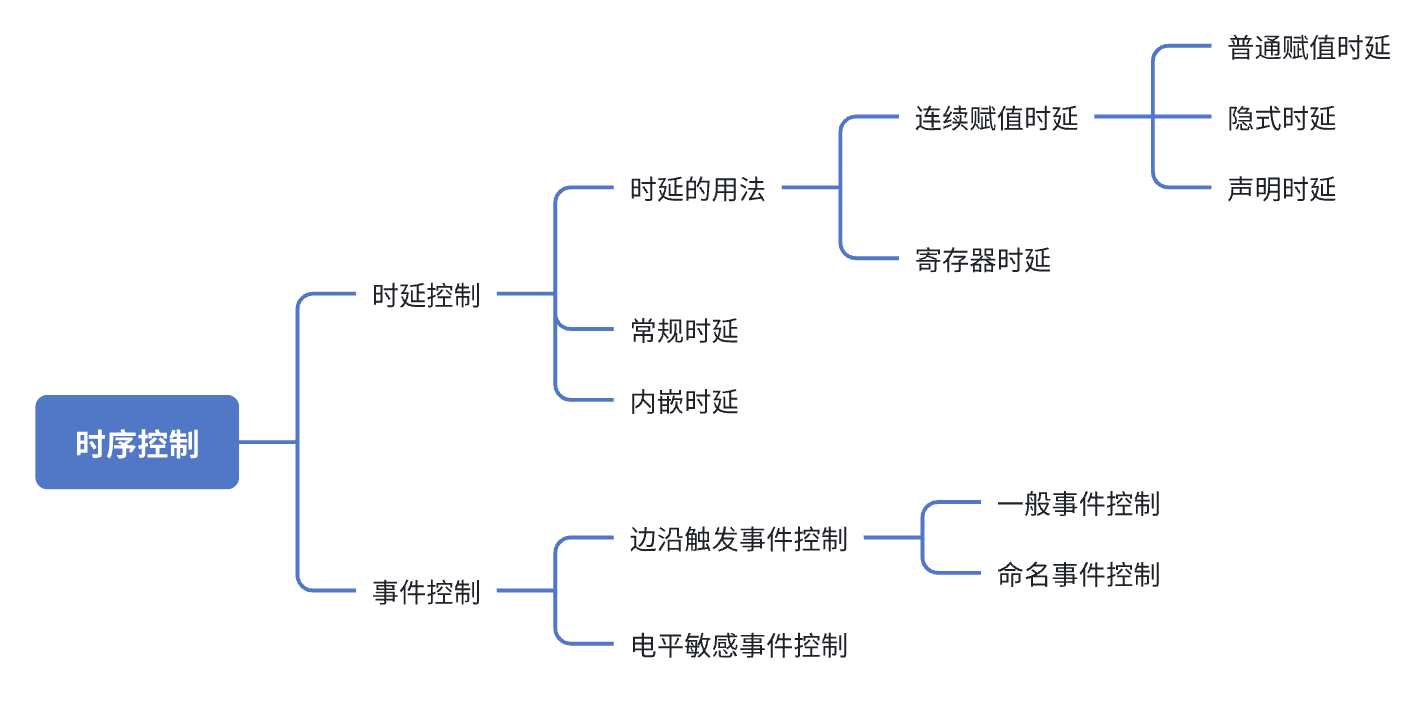
Verilog 提供了两大类时序控制方法:时延控制和事件控制。
时延是连续赋值语句中的延时,用于控制任意操作数发生变化到语句左端赋予新值之间的时间延时。连续赋值时延一般可分为普通赋值时延、隐式时延、声明时延。寄存器时延也是可以控制的,这部分在时序控制里加以说明。时延的值可以是数字、标识符或者表达式。时延一般是不可综合的。下面 3 个例子实现的功能是等效的,分别对应 3 种不同连续赋值时延的写法。
1
2
3
4
5
6
7
8
9
10
11
12
//普通时延,A&B计算结果延时10个时间单位赋值给Z。
wire Z, A, B;
assign #10 Z = A & B;
//隐式时延,声明一个wire型变量时对其进行包含一定时延的连续赋值。
wire A, B;
wire #10 Z = A & B;
//声明时延,声明一个wire型变量时指定一个时延。因此对该变量所有的连续赋值都会被推迟到指定的时间。除非门级建模中,一般不推荐使用此类方法建模。
wire A, B;
wire #10 Z;
assign Z = A & B;
在上述例子中,A 或 B 任意一个变量发生变化,那么在 Z 得到新的值之前,会有 10 个时间单位的时延。如果在这 10 个时间单位内,即在 Z 获取新的值之前,A 或 B 任意一个值又发生了变化,那么计算 Z 的新值时会取 A 或 B 当前的新值。所以称之为惯性时延,即信号脉冲宽度小于时延时,对输出没有影响。因此仿真时,时延一定要合理设置,防止某些信号不能进行有效的延迟。
时延控制出现在表达式中,它指定了语句从开始执行到执行完毕之间的时间间隔。根据在表达式中的位置差异,时延控制又可以分为常规时延与内嵌时延。遇到常规延时时,该语句需要等待一定时间,然后将计算结果赋值给目标信号。遇到内嵌延时时,该语句先将计算结果保存,然后等待一定的时间后赋值给目标信号。内嵌时延控制加在赋值号之后。
1
2
3
4
5
6
// 常规时延
reg value_test, value_general;
# 10 value_general = value_test;
// 内嵌时延
reg value_test, value_embed;
value_embed = # 10 value_test;
当延时语句的赋值符号右端是常量时,两种时延控制都能达到相同的延时赋值效果。当延时语句的赋值符号右端是变量时,两种时延控制可能会产生不同的延时赋值效果。常规时延赋值方式:遇到延迟语句后先延迟一定的时间,然后将当前操作数赋值给目标信号,并没有”惯性延迟”的特点,不会漏掉相对较窄的脉冲。内嵌时延赋值方式:遇到延迟语句后,先计算出表达式右端的结果,然后再延迟一定的时间,赋值给目标信号。
在 Verilog 中,事件是指某一个 reg 或 wire 型变量发生了值的变化。事件控制主要分为边沿触发事件控制与电平敏感事件控制。边沿触发事件控制又分一般事件控制和命名事件控制。事件控制用@表示,语句执行的条件是信号的值发生特定的变化。关键字 posedge 指信号发生边沿正向跳变,negedge 指信号发生负向边沿跳变,未指明跳变方向时,则两种情况的边沿变化都会触发相关事件。例如:
1
2
3
4
5
always @ (clk) q <= d; // 信号clk只要发生变化,就执行q<=d,双边沿D触发器模型
always @ (posedge clk) q <= d; //在信号clk上升沿时刻,执行q<=d,正边沿D触发器模型
always @ (negedge clk) q <= d; //在信号clk下降沿时刻,执行q<=d,负边沿D触发器模型
q = @ (posedge clk) d; //立刻计算d的值,并在clk上升沿时刻赋值给q,不推荐这种写法
不推荐最后一种写法的原因是,=是阻塞赋值,不符合常规的过程赋值语法规范。阻塞赋值通常用于组合逻辑或明确的 “立即执行” 场景。事件控制更常见于 always 块的敏感列表或 always 块内的时序控制。若在 initial 块或普通 always 块(非时序逻辑专用的 always 块)中使用,容易打破 “组合逻辑并行、时序逻辑同步触发” 的设计习惯;若在复杂场景(如多个信号交互、多时钟域)中使用,会导致仿真行为与硬件电路的实际并行执行逻辑脱节。Verilog 中,时序逻辑(如 D 触发器)的标准写法是用 always 块 + 非阻塞赋值(<=)。
命名事件控制是指,用户可以声明 event(事件)类型的变量,并触发该变量来识别该事件是否发生。命名事件用关键字 event 来声明,触发事件用 -> 运算符。
1
2
3
4
5
6
7
8
event start_receiving;
always @ (posedge clk_sample) begin
-> start_receiving;
end
always @ (start_receiving) begin
data_buf = {data_if[0], data_if[1]};
end
电平敏感事件控制是指后面语句的执行需要等待某个条件为真,使用关键字 wait 来表示这种电平敏感情况。
1
2
3
4
5
6
7
initial begin
wait (start_enable);
forever begin
@ (posedge clk_sample);
data_buf = {data_if[0], data_if[1]};
end
end